|
Dear Colleague,
If you're interested in low-power, low-cost machine learning at the edge, attend Lattice Semiconductor's free webinar "Architecting Always-On, Context-Aware, On-Device AI Using Flexible Low-power FPGAs" on October 30, 2018 at 9 am Pacific Time, presented in partnership with the Embedded Vision Alliance. The speakers will be Deepak Boppana, the company's Senior Director of Marketing, and Gordon Hands, Marketing Director for IP and Solutions (and a highly-rated Embedded Vision Summit presenter). In this webinar, the presenters will leverage the company's experience in developing low-cost, low-power, always-on, vision-based AI solutions to illustrate deep learning inferencing design tradeoffs and explore optimizations across edge processing implementations ranging from 1 mW to 1 W and $1 to $10. For more information, and to register, see the event page.
The Embedded Vision Alliance is performing research to better understand what types of technologies are needed by product developers who are incorporating computer vision in new systems and applications. To help guide suppliers in creating the technologies that will be most useful to you, please take a few minutes to fill out this brief survey. As our way of saying thanks for completing it, you’ll receive $50 off an Embedded Vision Summit 2019 2-Day Pass. Plus, you'll be entered into a drawing for one of several cool prizes. The deadline for entries is November 7, 2018. Please fill out the survey here.
The Embedded Vision Summit is the preeminent conference on practical computer vision, covering applications from the edge to the cloud. It attracts a global audience of over one thousand product creators, entrepreneurs and business decision-makers who are creating and using computer vision technology. The Embedded Vision Summit has experienced exciting growth over the last few years, with 97% of 2018 Summit attendees reporting that they’d recommend the event to a colleague. The next Summit will take place May 20-23, 2019 in Santa Clara, California. The deadline to submit presentation proposals is November 10, 2018. For detailed proposal requirements and to submit a proposal, please visit https://www.embedded-vision.com/summit/call-proposals. For questions or more information, please email [email protected].
Brian Dipert
Editor-In-Chief, Embedded Vision Alliance
|
|
Even Faster CNNs: Exploring the New Class of Winograd Algorithms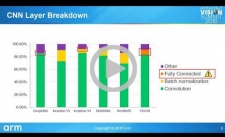
Over the past decade, deep learning networks have revolutionized the task of classification and recognition in a broad area of applications. Deeper and more accurate networks have been proposed every year and more recent developments have shown how these workloads can be implemented on modern low-power embedded platforms. This presentation from Gian Marco Iodice, Senior Software Engineer in the Machine Learning Group at Arm, discusses a recently introduced class of algorithms to reduce the arithmetic complexity of convolution layers with small filter sizes. After an introduction to the latest optimizations techniques for the most common solutions such as GEMM, the talk dives deeply into the design of Winograd algorithms, analyzing the complexity and the performance achieved for convolutional neural networks.
Deep Quantization for Energy Efficient Inference at the Edge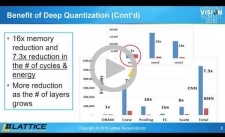
Intelligence at the edge is different from intelligence in the cloud in terms of requirements for energy, cost, accuracy and latency. Due to limits on battery power and cooling systems in edge devices, energy consumption is strictly limited. In addition, low cost and small size requirements make it hard to use packages with large numbers of pins, limiting the bandwidth to DRAM chips commonly used for storing neural network algorithm information. Despite these limitations, most applications require real-time operation. To tackle this issue, the industry has developed networks that heavily rely on deep quantization. In this talk, Hoon Choi, Senior Director of Design Engineering at Lattice Semiconductor, shows how to use the deep quantization in real applications without degrading accuracy. Specifically, he explains the use of different quantizations for each layer of a deep neural network and how to use deep layered neural networks along with deep quantization. He also explains the use of this deep quantization approach with recent lightweight networks.
|
|
Building a Typical Visual SLAM Pipeline
Maps are important for both human and robot navigation. SLAM (simultaneous localization and mapping) is one of the core techniques for map-based navigation. As SLAM algorithms have matured and hardware has improved, SLAM is spreading into many new applications, from self-driving cars to floor cleaning robots. In this talk, YoungWoo Seo, Senior Director at Virgin Hyperloop One, walks through a typical pipeline for SLAM, specifically visual SLAM. A typical visual SLAM pipeline, based on visual feature tracking, begins with extracting visual features and matching the extracted features to previously surveyed features. It then continues with estimation of the current camera poses based on the feature matching results, executing a (local) bundle adjustment to jointly optimize camera poses and map points, and lastly performing a loop-closure routine to complete maps. While explaining each of these steps, Seo also covers challenges, tips, open source libraries, performance metrics and publicly available benchmark datasets.
Augmented Reality Will Show Us Things That Aren’t Really There (and We'll Live Safer, Happy Lives Because of It)
This in-depth article from Jon Peddie Research covers the various challenges still to be resolved in order for augmented reality smart glasses to become widely adopted.
|
|
Arm TechCon Presentation – Computer Vision at the Edge and in the Cloud: Understanding the Tradeoffs: October 17, 2018, 3:30 pm PT, San Jose, California
Lattice Semiconductor Webinar – Architecting Always-On, Context-Aware, On-Device AI Using Flexible Low-power FPGAs: October 30, 2018, 9:00 am PT
Consumer Electronics Show: January 8-11, 2019, Las Vegas, Nevada
Embedded Vision Summit: May 20-23, 2019, Santa Clara, California
More Events
|
