|
Dear Colleague,
The next session of the Embedded Vision Alliance's in-person, hands-on technical training class series, Deep Learning for Computer Vision with TensorFlow, takes place in two days in San Jose, California. These classes give you the critical knowledge you need to develop deep learning computer vision applications with TensorFlow. The one-day class takes place this Thursday, October 4, 2018. Details, including online registration, can be found here.
Lattice Semiconductor will deliver the free webinar "Architecting Always-On, Context-Aware, On-Device AI Using Flexible Low-power FPGAs" on October 30, 2018 at 9 am Pacific Time, in partnership with the Embedded Vision Alliance. The webinar will be presented by Deepak Boppana, the company's Senior Director of Marketing, and Gordon Hands, Marketing Director for IP and Solutions (and a highly-rated Embedded Vision Summit presenter). In this webinar, the presenters will leverage the company's experience in developing low-cost, low-power, always-on, vision-based AI solutions to illustrate deep learning inferencing design tradeoffs and explore optimizations across edge processing implementations ranging from 1 mW to 1 W and $1 to $10. For more information, and to register, see the event page.
Brian Dipert
Editor-In-Chief, Embedded Vision Alliance
|
|
A Physics-based Approach to Removing Shadows and Shading in Real Time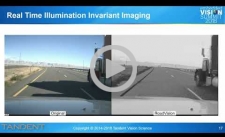
Shadows cast on ground surfaces can create false features and modify the color and appearance of real features, masking important information used by autonomous vehicles, advanced driver assistance systems, pedestrian guides, or autonomous wheelchairs. In this top-rated presentation, Bruce Maxwell, Director of Research at Tandent Vision Science, presents a method for generating an illumination-independent image suitable for analysis and classification using a physics-based 2D chromaticity space. To explore its utility, Tandent has implemented a system for removing spatial and spectral illumination variability from roads and pathways that runs at frame rate on embedded processors. The combination of physics-based pre-processing with a simple classifier to identify road features significantly outperforms a more complex classifier trained to do the same task on standard imagery, while using less computation. Removing illumination variability prior to classification can be a powerful strategy for simplifying computer vision problems to make them practical within the computational and energy budgets of embedded systems.
Words, Pictures, and Common Sense: Visual Question Answering
Wouldn't it be nice if machines could understand content in images and communicate this understanding as effectively as humans? Such technology would be immensely powerful, be it for helping a visually-impaired user navigate a world built by the sighted, assisting an analyst in extracting relevant information from a surveillance feed, educating a child playing a game on a touch screen, providing information to a spectator at an art gallery, or interacting with a robot. As computer vision and natural language processing techniques are maturing, we are closer to achieving this dream than we have ever been. Visual Question Answering (VQA) is one step in this direction. Given an image and a natural language question about the image (e.g., “What kind of store is this?”, “How many people are waiting in the queue?”, “Is it safe to cross the street?”), the machine’s task is to automatically produce an accurate natural language answer (“bakery”, “5”, “Yes”). In this talk, Devi Parikh, Research Scientist at Facebook AI Research and Assistant Professor at Georgia Tech, presents her research group's dataset, the results it has obtained using neural models, and open research questions in free-form and open-ended VQA.
|
|
Real-time Calibration for Stereo Cameras Using Machine Learning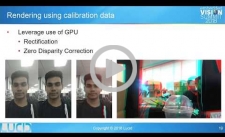
Calibration involves capturing raw data and processing it to get useful information about a camera's properties. Calibration is essential to ensure that a camera's output is as close as possible to what it "sees." Calibration for a stereo pair of cameras is even more critical because it also obtains data on the cameras’ positions relative to each other. These extrinsic parameters ensure that 3d data can be properly rectified for viewing, and enable further advanced processing, such as obtaining disparity and depth maps and performing 3d reconstruction. In order for advanced processing to work correctly, calibration data should be error-fee. With age, heat and external conditions, extrinsic properties of a camera can change. In this presentation, Sheldon Fernandes, Senior Software and Algorithms Engineer at Lucid VR, discusses calibration techniques and a model for calibration, and proposes advanced techniques using machine learning to estimate changes in extrinsic parameters in real time.
Optimize Performance: Start Your Algorithm Development With the Imaging Subsystem
Image sensor and algorithm performance are rapidly increasing, and software and hardware development tools are making embedded vision systems easier to develop. Even with these advancements, optimizing vision-based detection systems can be difficult. To optimize performance, it’s important to understand the imaging subsystem and its impact on image quality and the detection algorithm. Whether performance improvement involves tuning an imaging subsystem parameter or increasing algorithm capability, it is the designer’s responsibility to navigate these relationships and trade-offs. This top-rated presentation from Ryan Johnson, lead engineer at Twisthink, describes a design approach that allows the designer to iteratively adjust imaging subsystem performance while increasing the fidelity of the detection algorithm. Viewers will gain an understanding of several high-impact imaging subsystem noise sources, methods for evaluation and ways to determine requirements driven by the detection algorithm. Viewers will also learn how datasets enable evaluation of non-obvious noise sources and system performance.
|
|
Deep Learning for Computer Vision with TensorFlow Training Class: October 4, 2018, San Jose, California
Lattice Semiconductor Webinar – Architecting Always-On, Context-Aware, On-Device AI Using Flexible Low-power FPGAs: October 30, 2018, 9:00 am PT
Embedded Vision Summit: May 20-23, 2019, Santa Clara, California
More Events
|
