|
Dear Colleague,
The Embedded Vision Alliance is performing research to better understand what types of technologies are needed by product developers who are incorporating computer vision in new systems and applications. To help guide suppliers in creating the technologies that will be most useful to you, please take a few minutes to fill out this brief survey. As our way of saying thanks for completing it, you’ll receive $50 off an Embedded Vision Summit 2019 2-Day Pass. Plus, you'll be entered into a drawing for one of several cool prizes. The deadline for entries is November 7, 2018. Please fill out the survey here.
The Embedded Vision Summit is the preeminent conference on practical computer vision, covering applications from the edge to the cloud. It attracts a global audience of over one thousand product creators, entrepreneurs and business decision-makers who are creating and using computer vision technology. The Embedded Vision Summit has experienced exciting growth over the last few years, with 97% of 2018 Summit attendees reporting that they’d recommend the event to a colleague. The next Summit will take place May 20-23, 2019 in Santa Clara, California. The deadline to submit presentation proposals is December 1, 2018. For detailed proposal requirements and to submit a proposal, please visit https://www.embedded-vision.com/summit/call-proposals. For questions or more information, please email [email protected].
Brian Dipert
Editor-In-Chief, Embedded Vision Alliance
|
|
Getting More from Your Datasets: Data Augmentation, Annotation and Generative Techniques
Deep learning for embedded vision requires large datasets. Indeed, the more varied the training data is, the more accurate the resultant trained network tends to also be. But, acquiring and accurately annotating datasets costs time and money. This talk from Peter Corcoran, co-founder of FotoNation (a business unit of Xperi) and lead principle investigator and director of C3Imaging (a research partnership between Xperi and the National University of Ireland, Galway), shows how to get more out of existing datasets. First, Corcoran reviews state-of-art data augmentation techniques and explains a new approach, smart augmentation. Next, he describes generative adversarial networks (GANs) that learn the structure of an existing dataset; several example use cases (such as creating a very large dataset of facial training data) show how GANs can generate new data corresponding to the original dataset. But building a dataset does not by itself represent the entirety of the challenge; data must also be annotated in a way that is meaningful for the training process. Corcoran's presentation then gives an example of training a GAN from a dataset that incorporates annotations. This technique enables the generation of "pre-annotated data," providing an exciting way to create large datasets at significantly reduced cost.
Deep Learning in MATLAB: From Concept to Optimized Embedded Code
In this presentation from Avinash Nehemiah, Product Marketing Manager for Computer Vision, and Girish Venkataramani, Product Development Manager, both of MathWorks, you'll learn how to adopt MATLAB to design deep learning-based vision applications and re-target deployment to embedded CPUs and GPUs. The workflow starts with algorithm design in MATLAB, which enjoys universal appeal among engineers and scientists because of its expressive power and ease of use. The algorithm may employ deep learning networks augmented with traditional computer vision techniques and can be tested and verified within MATLAB. Next, those networks are trained using MATLAB's GPU and parallel computing support either on the desktop, a local compute cluster, or in the cloud. In the deployment phase, code-generation tools are employed to automatically generate optimized code that can target both embedded GPUs like Jetson TX2, DrivePX2, or Intel based CPU platforms or ARM-based embedded platforms. The generated code is highly optimized to the chosen target platform. The auto-generated code is ~2.5x faster than mxNet, and ~5x faster than Caffe2. Nehemiah and Venkataramani use an example of LiDAR processing for autonomous driving to illustrate these concepts.
|
|
Depth Cameras: A State-of-the-Art Overview
In the last few years, depth cameras have reached maturity and are being incorporated in an increasing variety of commercial products. Typical applications span gaming, contactless authentication in smartphones, AR/VR and IoT. State-of-the-art depth cameras are based on three fundamental technologies: stereo vision, time-of-flight (ToF) and structured light (SL). These technologies are available in rather different implementations, which are characterized by specific properties in terms of measurement quality (e.g., precision, accuracy, range and resolution) and in terms of system requirements (e.g., power consumption, size, computational requirements). This talk from Carlo Dal Mutto, CTO of Aquifi, provides an overview of the fundamentals behind stereo, ToF and SL technologies. It presents measurement characterization and system requirements of different implementations, and it explores a selection of depth cameras available in the market.
Optimizing Your System Software and Board Support Package for Embedded Vision and AI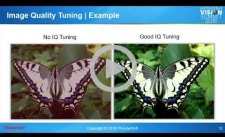
While computer vision and AI algorithms tend to get the most attention, many other software components can have an equally important impact on image quality, algorithm accuracy and performance. For example, to get the best images from the chosen image sensor, the image signal processor must be tuned for the characteristics of the sensor and the environment. Camera device drivers also affect image quality. In addition, software component libraries and frameworks (such as frameworks for accelerating neural network inference) can speed application development, but also have a huge impact on performance and, in some cases, algorithm accuracy. In this presentation, Daniel Sun, Vice President of the Intelligent Vision Business Unit at Thundersoft, explores how carefully selecting and integrating these supporting software components alongside algorithm software modules leads to systems with superior image quality, accuracy and performance.
|
