This blog post was originally published at Intel's website. It is reprinted here with the permission of Intel.
Deep Learning (DL) computational performance is critical for scientists and engineers applying deep learning techniques to many challenges in healthcare, commerce, autonomous driving, and other domains. This is why in March, we released an early version of Intel nGraph Library and Compiler as an open-source project available on GitHub. It was clear to us early on that open standards and lateral collaboration for interoperability would be essential to help those scientists and engineers achieve the next wave of breakthroughs in their respective fields. Some of our researchers have already started using nGraph to explore next-generation AI topics, such as enabling inference on private data using homomorphic encryption.
Which brings us to today’s announcement: our Beta release of the nGraph Compiler stack. This release focuses on accelerating deep learning inference workloads on Intel® Xeon® Scalable processors and has the following key features:
- Streamlined out-of-box installation experience for TensorFlow*, MXNet*, and ONNX*.
- Validated optimization for 20 common workloads available in TensorFlow, 18 in MXNet, and 14 in ONNX.
- Support for Ubuntu* 16.04 (TensorFlow, MXNet, and ONNX) and MacOS* X 13.x (buildable for TensorFlow and MXNet).
This includes optimizations built for popular workloads already widely deployed in production. These workloads cover various genres of deep learning including:
- Image recognition and segmentation
- Object detection
- Language translation
- Speech generation and recognition
- Recommender systems
- Generative adversarial network (GAN)
- Reinforcement learning

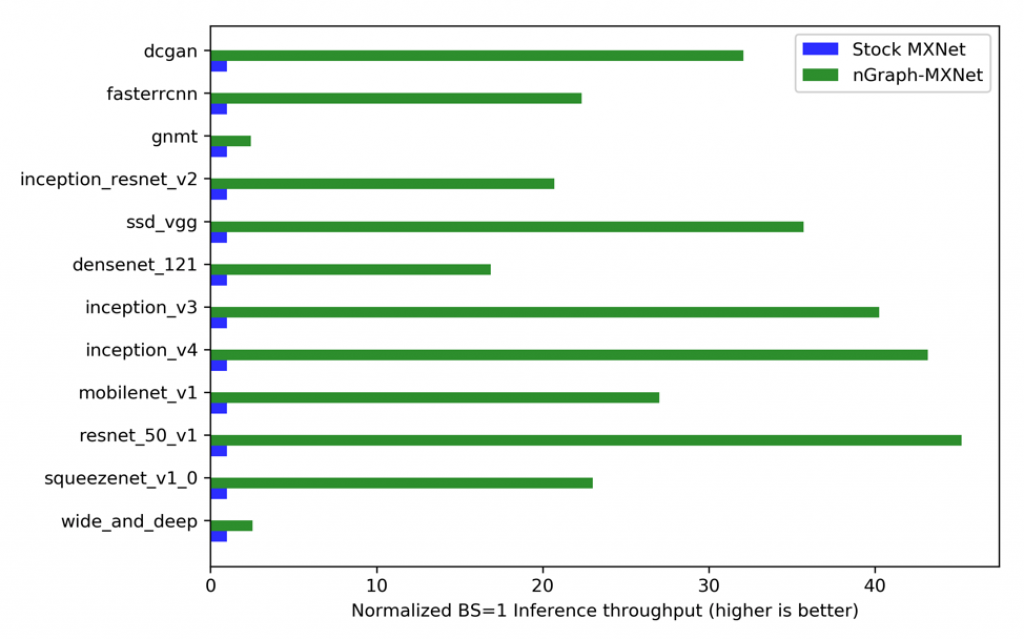
Figure 1. nGraph increases MXNet inference performance
In our tests, the optimized workloads can perform up to 45X faster than native frameworks1, and we expect performance gains for other workloads from our powerful pattern matching feature described below.
Traditionally, to get deep learning performance out of hardware, users had to wait for hardware manufacturers to create and update kernel libraries which expose (sometimes hand-tuned) individual operations in an “immediate mode” execution interface. And while these kernel optimizations often bring amazing performance gains, they tend to be hardware-specific, which preemptively eliminates any opportunity to optimize at the non-device-specific level. By pairing the non-device-specific and device-specific optimizations, we can unlock even more performance, which is why we built nGraph Compiler.

Our Beta release has many key features: nGraph was the first graph compiler to enable both training and inference while also supporting multiple frameworks; it allows developers the freedom of completely changing hardware backends underneath their same conceptual model or algorithmic design. Any one of these features on their own might be good enough; taken all together, these features give developers assurance that their Neural Network (NN) design can not only grow, but also adapt to myriad changing factors. Adaptability will become increasingly important, as it becomes harder for developers to guess ahead of time the bounds for which they might need to optimize a very large or complex machine learning problem.
In our upcoming Gold release tentatively planned for early second quarter of 2019, we’ll announce further-expanded workload coverage for more frameworks, including additional support for quantized graphs and Int8. Since we designed the nGraph Compiler to support an ever-growing list of AI hardware, early adopters of the Intel® Nervana™ Neural Network Processor and other accelerators will be able to test them using nGraph Compiler throughout 2019. See our ecosystem documentation for further details about what we have in the works. We encourage you to get started by accessing our quick start guide or downloading the latest release. And as always, we welcome any feedback or comments via GitHub.
Harry Kim
Product Manager, Artificial Intelligence Products Group, Intel
Jason Knight
Senior Technology Officer, Artificial Intelligence Products Group, Intel
Notices and Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations, and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/benchmarks.
1.Hardware configuration: 2S Intel® Xeon® Platinum 8180 CPU @ 2.50GHz (28 cores), HT enabled, turbo enabled, scaling governor set to “performance” via intel_pstate driver, microcode version 0x200004d, Intel Corporation Bios Version SE5C620.86B.00.01.0014.070920180847, 384GB (12 * 32GB) DDR4 ECC SDRAM RDIMM @ 2666MHz (Micron* part no. 36ASF4G72PZ-2G6D1),800GB SSD 2.5in SATA 3.0 6Gb/s Intel Downieville SSDSC2BB800G701 DC S3520, client ethernet adapter: Intel PCH Integrated 10 Gigabit Ethernet Controller.
Software configuration: Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-109-generic x86_64), base MXNet version https://github.com/apache/incubator-mxnet/tree/064c87c65d9a316e5afda26d54ed2c1e6f38e04f and ngraph-mxnet version https://github.com/NervanaSystems/ngraph-mxnet/tree/a8ce39eee3b5baea070cefea0aa991f6773ba694 and Intel® MKL-DNN version 0.14. Both tests used environment variables OMP_NUM_THREADS=28 and KMP_AFFINITY=granularity=fine,compact,1,0.
Performance results were measured by Intel Corporation using a custom automation wrapper around publicly available model implementations. Gluon models DCGAN, Densenet, and Squeezenet were converted to static graphs via standard module APIs. Performance tests were performed with real data and random weights initialized with the Xavier initializer. Performance results are based on testing as of October 10, 2018 and may not reflect all publicly available security updates. No product or component can be absolutely secure.
Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Notice Revision #20110804
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com.