This blog post was originally published at Intel's website. It is reprinted here with the permission of Intel.
Data scientists need annotated data (and lots of it) to train the deep neural networks (DNNs) at the core of AI workflows. Obtaining annotated data, or annotating data yourself, is a challenging and time-consuming process. For example, it took about 3,100 total hours for members of Intel’s own data annotation team to annotate the more than 769,000 objects used for just one of our algorithms. To help solve this challenge, Intel is conducting research to find better methods to annotate data and deliver tools that help developers do the same.
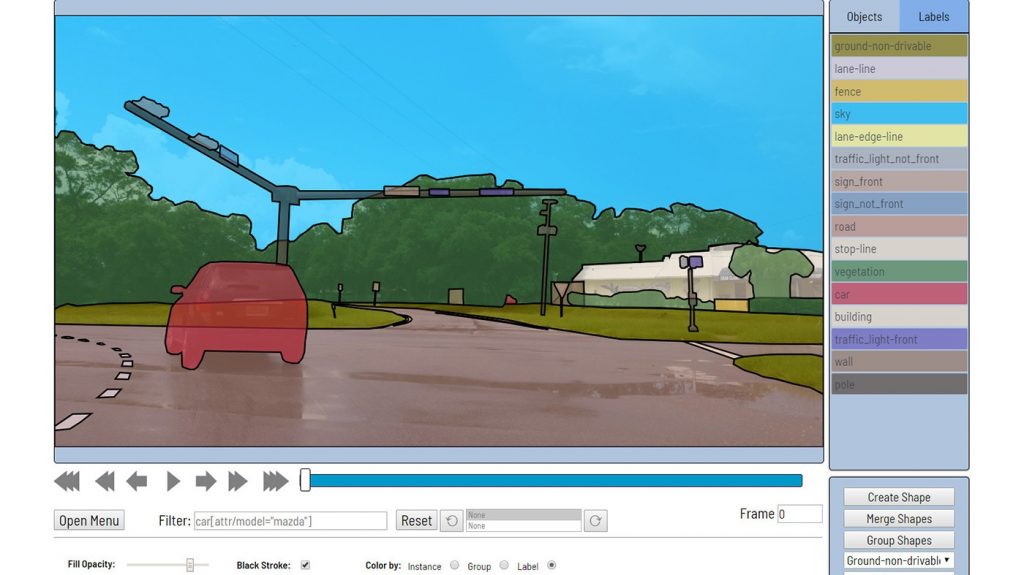
As part of these efforts, we are pleased to present a new open source program called Computer Vision Annotation Tool (CVAT, pronounced “si-vi-eɪ-ti”) that accelerates the process of annotating digital images and videos for use in training computer vision algorithms. In this post, we’ll provide an overview of CVAT’s key capabilities. Please consult our article on the Intel Developer Zone for a detailed tutorial of how to use CVAT.
Current Challenges with Data Annotation
Though there is a wealth of training data available on the Internet, it isn’t always possible to use online data to train a deep learning algorithm. For example, there may not be pre-annotated data available for new use cases. If pre-annotated training data does exist, the data may require license agreements that prevent their use in commercial products.
Today, there are generally two ways for data scientists to obtain new annotated data:
- Delegate to a third-party company specializing in annotation. However, this can complicate the processes of data validation and re-annotation and additionally requires more paperwork.
- Create and support an internal data annotation team. We found this to be more convenient for our team, because we could more quickly assign new tasks and better manage the workflow. We also found it easier to find a balance between the price and quality of the work.
Working with an internal team also gives data scientists the opportunity to develop automation algorithms and other tools to improve the quality and speed of annotation.
Computer Vision Annotation Tool’s Key Capabilities
CVAT was designed to provide users with a set of convenient instruments for annotating digital images and videos. CVAT supports supervised machine learning tasks pertaining to object detection, image classification, and image segmentation. It enables users to annotate images with four types of shapes: boxes, polygons (both generally and for segmentation tasks), polylines (which can be useful for annotating markings on roads), and points (e.g., for annotating face landmarks or pose estimation).
Additionally, CVAT provides features facilitating typical annotation tasks, such as a number of automation instruments (including the ability to copy and propagate objects, interpolation, and automatic annotation using the TensorFlow* Object Detection API), visual settings, shortcuts, filters, and more.
CVAT is easy to access via a browser-based interface; following a simple deployment via Docker*, no further installation is necessary. CVAT supports collaboration between teams as well as work by individuals. Users can create public tasks and split up work between other users. CVAT is also highly flexible, with support for many different annotation scenarios, a variety of optional tools, and the ability to be embedded into platforms such as Onepanel*. CVAT was developed for and with support from professional annotation and algorithmic teams, and we have tried to provide the features that those teams will find most valuable.
Like many early open-source projects, CVAT also has some known limitations. Its client has only been tested in Google Chrome* and may not perform well in other browsers. Though CVAT supports some automatic testing, all checks must be done manually, which can slow the development process. CVAT’s documentation is currently somewhat limited, which can impede participation in the tool’s development. Finally, CVAT can have performance issues in certain use cases due to the limitations of Chrome Sandbox. Despite these disadvantages, CVAT should remain a useful tool for image annotation workflows. Additionally, we hope to address some of these shortcomings through future development.
We’ve recorded several video examples showing CVAT’s annotation processes in different modes:
- Interpolation mode. CVAT can be used to interpolate bounding boxes and attributes between key frames, after which a set of images will be annotated automatically.
- Attribute annotation mode. This was developed for image classification and accelerates the process of attribute annotation by focusing the annotator’s attention on only one attribute. Additionally, the process of annotation is carried out by using hotkeys.
- Segmentation mode. In this mode, visual settings make the annotation process easier.
Next Steps and Future Development
Feedback from users is helping Intel determine future directions for CVAT’s development. We hope to improve the tool’s user experience, feature set, stability, automation features, and ability to be integrated with other services, and encourage members of the community to take an active part in CVAT’s development.
For a deeper dive into how CVAT works, please visit our post on the Intel Developer Zone. We’ve also provided guidelines for getting up and running with CVAT on GitHub, and encourage you to reach out for questions anytime in Gitter chat. Finally, please check out our blog for future news about CVAT and other AI technologies from Intel and don’t forget to follow @IntelAIDev on Twitter.
Boris Sekachev
Deep Learning Software Developer, Internet of Things Group, Intel
Nikita Manovich
Deep Learning Manager, Internet of Things Group, Intel