|
Dear Colleague,
We're pleased to announce our first keynote speaker for the Embedded Vision Summit, taking place May 20-23, 2019 in Santa Clara, California. Ramesh Raskar is an award-winning innovator with over 80 patents and the founder of the Camera Culture research group at the MIT Media Lab. In his talk "Making the Invisible Visible: Within Our Bodies, the World Around Us, and Beyond," Raskar will show us the work he and his team are doing in combining novel camera technologies and deep learning AI algorithms to deliver advanced imaging and visual perception, in the process highlighting how vision technology continues to make possible new and seemingly impossible applications.
The Embedded Vision Summit attracts a global audience of over one thousand product creators, entrepreneurs and business decision-makers who are developing and using visual AI technology. The Summit has experienced exciting growth over the last few years, with 97% of 2018 Summit attendees reporting that they'd recommend the event to a colleague. The Summit is the place to learn about the latest applications, techniques, technologies, and opportunities in visual AI and deep learning, and online registration is now available.
In 2019, the event will feature new, deeper and more technical sessions, with more than 90 expert presenters in 4 conference tracks (the first round of accepted speakers and talks is now published, with more to follow soon) and 100+ demonstrations in the Technology Showcase. Two hands-on trainings, the updated Deep Learning for Computer Vision with TensorFlow 2.0 and brand new Computer Vision Applications in OpenCV, will run concurrently on the first day of the Summit, May 20. And the last day of the Summit, May 23, will again feature the popular vision technology workshops from Intel (both introductory and advanced), Khronos and Synopsys. Register today using promotion code EARLYBIRDNL19 to save 15% with our limited-time Early Bird Discount rate.
A newly launched publication, Vision Spectra, covers various topics of relevance to the computer vision community, such as neural networks, smart cameras, intelligent lighting, vision-guided robotics, 3D vision and machine vision optics. For more information and to sign up for your own subscription, visit www.photonics.com/vision.
Brian Dipert
Editor-In-Chief, Embedded Vision Alliance
|
|
Exploiting Reduced Precision for Machine Learning on FPGAs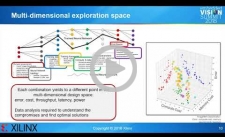
Machine learning algorithms such as convolutional neural networks have become essential for embedded vision. Their implementation using floating-point computation requires significant compute and memory resources. Research over the last two years has shown that reducing the precision of the representations of network inference parameters, inputs and activation functions results in more efficient implementations with a minimal reduction in accuracy. With FPGAs, it is possible to customize hardware circuits to operate on these reduced precision formats: 16 bit, 8 bit and even lower precision. This significantly reduces the hardware cost and power consumption of inference engine implementations. In this talk, Kees Vissers, Distinguished Engineer at Xilinx, shows detailed results of the accuracy and implementation cost for several reduced-precision neural networks on a set of embedded platforms. From these design points, he extracts the pareto-optimal results for accuracy versus precision of both weights and activations, ranging from 16 bit to 8 bit, and down to only a few bits.
Project Trillium: A New Suite of Machine Learning IP
Machine learning processing engines today tend to focus on specific device classes or the needs of individual sectors. Arm’s Project Trillium, as explained in this presentation by Steve Steele, Director of Platforms in the company's Machine Learning Group, changes that by offering ultimate scalability. While the initial launch focuses on mobile processors, future Arm ML products will deliver the ability to move up or down the performance curve–from sensors and smart speakers to mobile, home entertainment and beyond. Project Trillium comprises a suite of Arm IP including ML and object detection processors and Arm NN, a SW stack supporting ML across a wide range of Arm and other hardware IP. The Arm ML processor is built specifically for machine learning, based on a highly scalable architecture that can target ML across a wide range of performance points. The Arm OD processor efficiently identifies people and other objects with virtually unlimited detections per frame. And Arm NN serves as a bridge between neural network frameworks and the underlying hardware by leveraging a library of highly optimized NN primitives.
|
|
Using MATLAB and TensorRT on NVIDIA GPUs
As you design deep learning networks, how can you quickly prototype the complete algorithm—including pre- and postprocessing logic around deep neural networks—to get a sense of timing and performance on standalone GPUs? This question, according to MathWorks' Bill Chou, Product Manager for Code Generation Products, comes up frequently from the scientists and engineers he works with. Traditionally, you would hand translate the complete algorithm into CUDA and compile it with the NVIDIA toolchain. However, depending on the tools you're using, compilers exist which can help automate the process of converting designs to CUDA. Engineers and scientists using MATLAB have access to tools to label ground truth and accelerate the design and training of deep learning networks. MATLAB can also import and export using the ONNX format to interface with other frameworks. Finally, to quickly prototype designs on GPUs, MATLAB users can compile the complete algorithm to run on any modern NVIDIA GPUs, from Tesla to DRIVE to Jetson AGX Xavier platforms. This technical article explains how to use MATLAB’s new capabilities to compile MATLAB applications, including deep learning networks and any pre- or postprocessing logic, into CUDA and run them on NVIDIA GPUs.
Recent Developments in the GPU Computing Market
In this presentation, Jon Peddie, President and Founder of Jon Peddie Research, shares his perspective on how GPUs and the GPU competitive landscape are evolving in response to the fast-growing use of GPUs as parallel compute engines.
|
