|
Deep Learning on Arm Cortex-M Microcontrollers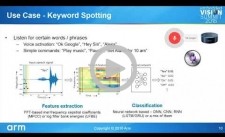
Deep learning algorithms are gaining popularity in IoT edge devices due to their human-level accuracy in many tasks, such as image classification and speech recognition. As a result, there is increasing interest in deploying neural networks (NNs) on the types of low-power processors found in always-on systems, such as those based on Arm Cortex-M microcontrollers. In this talk, Vikas Chandra, Senior Principal Engineer and Director of Machine Learning at Arm, introduces the challenges of deploying neural networks on microcontrollers with limited memory and compute resources and power budgets. He introduces CMSIS-NN, a library of optimized software kernels to enable deployment of neural networks on Cortex-M cores. He also presents techniques for NN algorithm exploration to develop lightweight models suitable for resource constrained systems, using image classification as an example.
Neural Network Compiler: Enabling Rapid Deployment of DNNs on Low-Cost, Low-Power Processors
The use of deep neural networks (DNNs) has accelerated in recent years, with DNNs making their way into diverse commercial products. But DNNs consume vast amounts of computation performance and memory bandwidth, creating challenges for developers seeking to deploy them in cost- and power-constrained systems. Specialized processors, such as the Cadence Tensilica Vision C5 DSP and Vision P6 DSP, address these performance and efficiency challenges. However, additional challenges arise due to time-to-market pressures, and from the complexities of DNN algorithms and specialized processor architectures. Specialized software tools are key to addressing these challenges, enabling engineers to quickly generate efficient implementations of deep neural networks to run on specialized processors, without requiring detailed knowledge of the algorithms and processors. This talk from Megha Daga, Senior Technical Marketing Manager at Cadence, illustrates how Cadence’s Neural Network Compiler enables engineers to start from a neural network description based on a framework such as TensorFlow or Caffe and then quickly generate optimized fixed-point neural network code. Daga illustrates how the compiler speeds deployment from months to days. She also highlights compiler configurability options that help in optimizing system performance and shows how the generated code can be easily deployed to run in real time on an AI DSP hardware platform.
|
|
Achieving High-Performance Vision Processing for Embedded Applications with Qualcomm SoC Platforms
Advancements in machine learning are making it possible to equip devices such as connected cameras, robots, drones and smart home solutions with improved on-device vision processing and analytics capabilities. This talk from Sahil Bansal, Senior Director of Product Management at Qualcomm, addresses how a hybrid approach, combining deep learning with traditional computer vision and utilizing Qualcomm Technologies System-on-Chips (SoCs) and solutions, can deliver significant performance and power-efficiency improvements for embedded applications requiring vision processing. Bansal presents the benefits and trade-offs, use cases and results from concrete implementations using this hybrid approach.
SoCs for Computer Vision-enabled IoT Devices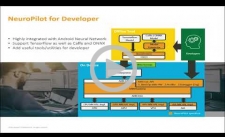
In this presentation at the Embedded Vision Alliance's March 2019 Silicon Valley Meetup, Bing Yu, Senior Technical Manager at MediaTek, introduces the company's line of SoCs for computer-vision-enabled IoT devices.
|
