
This blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
This is the third post in the CUDA Refresher series, which has the goal of refreshing key concepts in CUDA, tools, and optimization for beginning or intermediate developers.
Ease of programming and a giant leap in performance is one of the key reasons for the CUDA platform’s widespread adoption. The second biggest reason for the success of the CUDA platform is the availability of a broad and rich ecosystem.
Like any new platform, CUDA’s success was dependent on tools, libraries, applications, and partners available for CUDA ecosystem. Any new computing platform needs developers to port applications to a new platform.To do that, developers need state of art tools and development environments.
After applications start scaling, more tools are essential at the datacenter level. NVIDIA is committed to providing state-of-art tools and ecosystem services to developers and enterprises.
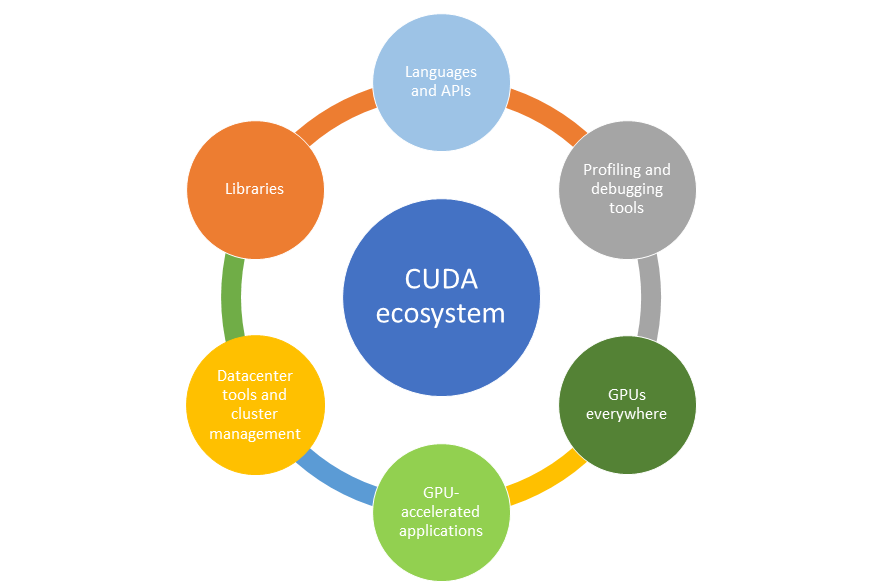
Figure 1: CUDA Ecosystem: The building blocks to make the CUDA platform the best developer choice.
NVIDIA recently announced the latest A100 architecture and DGX A100 system based on this new architecture. The new A100 GPU also comes with a rich ecosystem.
Figure 1 shows the wider ecosystem components that have evolved over a period of 15+ years. In this post, I dive into the introductory details to each ecosystem component.
Programming languages and APIs
CUDA 1.0 started with support for only the C programming language, but this has evolved over the years. CUDA now allows multiple, high-level programming languages to program GPUs, including C, C++, Fortran, Python, and so on.
NVIDIA released the CUDA toolkit, which provides a development environment using the C/C++ programming languages. With this toolkit, you can develop, optimize, and deploy applications on GPUs. NVIDIA also provides a PGI toolkit to program using the Fortran language.
There are also many third-party tool-chains available:
- PyCUDA—Use CUDA API operations from a Python interface.
- Altimesh Hybridizer—Generate CUDA C source code from .NET assemblies (MSIL) or Java archives (java bytecode).
- OpenACC—Use directives to program GPUs and compiler-generated CUDA code before executing on CUDA GPUs.
- OpenCL—Use low-level API operations to program CUDA GPUs.
- Alea-GPU—Program CUDA GPUs with the .NET framework.
Libraries
Libraries are essential to providing drop-in performance for widely used common routines in any programming environment. They are well-optimized for the target compute architecture and are of high software quality. They also save application development time and provide the easiest way to get started with GPU acceleration.
NVIDIA provides a layer on top of the CUDA platform called CUDA-X, , which is a collection of libraries, tools, and technologies. GPU-accelerated CUDA libraries enable drop-in acceleration across multiple domains such as linear algebra, image and video processing, deep learning, and graph analytics. For developing custom algorithms, you can use available integrations with commonly used languages and numerical packages, as well as well-published development API operations.
The NVIDIA CUDA toolkit comes with a wide collection of commonly used libraries. Many partners also contribute many libraries on the CUDA platform. Here is a list of some widely used libraries:
- Mathematical libraries: cuBLAS, cuRAND, cuFFT, cuSPARSE, cuTENSOR, cuSOLVER
- Parallel algorithm libraries: nvGRAPH, Thrust
- Image and video libraries: nvJPEG, NPP, Optical Flow SDK
- Communication libraries: NVSHMEM, NCCL
- Deep learning libraries: cuDNN, TensorRT, Jarvis, DALI
- Partner libraries: OpenCV, FFmpeg, ArrayFire, MAGMA
Profiling and debugging tools
One of the vital elements of any programming architecture is robust and efficient tools to write, debug, and optimize programs. The CUDA ecosystem is robust and NVIDIA has spent a tremendous amount of effort to make sure that you have all the tools necessary to write quickly, easily, and efficiently.
Here is a preview of CUDA profiling and debugging tools:
- NVIDIA Nsight—This is a low overhead profiling, tracing, and debugging tool. It provides a GUI-based environment to scale across a wide range of NVIDIA platforms, such as large multi-GPU x86 servers, Quadro workstations, and so on.
- CUDA GDB—This is an extension of Linux GDB, which provides a console-based debugging interface that you can use from the command line. CUDA GDB can be used on your local system or any remote system. GUI-based plugins are also available, for example, DDD, EMACS, or Nsight Eclipse Edition.
- CUDA-Memcheck—A must-have tool that provides insights into memory access issues by examining the thousands of threads running concurrently.
There are also many third-party solutions available, including the following:
Datacenter tools and cluster management
NVIDIA GPUs provide massive acceleration to applications and these applications are scaled further to a large number of GPUs. Many scientific applications, like molecular dynamics and quantum chemistry, and also AI applications need a cluster of GPUs to scale out application performance to thousands of GPUs connected by a high-speed network. The modern data centers are built using NVIDIA GPUs and Mellanox high-speed interconnect to scale the applications to massively scale performance.
You need a sophisticated ecosystem to have ease of deployment in datacenters. Enterprises need tools to easily manage and run these dense datacenters. NVIDIA works closely with ecosystem partners to provide developers and DevOps with software tools for every step of the AI and HPC software lifecycle.
Here are some of the efforts that NVIDIA is working on to strengthen this ecosystem:
- Container registry
- Scheduling and orchestration
- Cluster management tools
- Monitoring tools
Containers
Containers are the modern way to easily deploy applications. NVIDIA provides all deep learning and HPC containers from NVIDIA NGC. These containers are tested, maintained, and well-optimized by NVIDIA. NGC also provides a way to host third-party containers. Organizations can also choose to have private container repositories.
Scheduling and orchestration
Scheduling and orchestration is another important aspect of datacenter management and operations. Kubernetes is the modern and popular container-orchestration system for automating application deployment, scaling, and management. Kubernetes on NVIDIA GPUs extends the industry-standard container orchestration platform with GPU acceleration capabilities. Kubernetes provides state-of-the-art support for NVIDIA GPU resource scheduling.
Cluster management tools
Major standard cluster management tools have support for NVIDIA GPUs. Some examples include Bright Cluster, Ganglia, StackIQ, and Altair PBS Works.
Monitoring tools
NVIDIA also provides a suite of tools called DCGM for the management and monitoring of GPUs in cluster environments. NVIDIA also exposes an API-based interface to monitor GPUs by NVML APIs. With help from these tools, the datacenter ops team can continuously perform active health monitoring, comprehensive diagnostics, system alerts, and governance policies including power and clock management. These tools can be used either standalone or integrated with any industry-standard tool suites. You can also build your own tools using NVML API operations.
CUDA ecosystem and GPU-accelerated applications
After the release of CUDA in 2006, developers have ported many applications on CUDA.
The first set of developers who started porting applications were the scientific community. This community ported many standard applications, as well as homegrown code. Applications having inherent parallelism, like image and video processing, were one of the first use cases ported to CUDA.
Deep learning was another example where massive parallelism helped to accelerate applications. Almost every deep learning framework today uses CUDA/GPU computing to accelerate deep learning training and inference.
NVIDIA maintains a catalog to list all GPU-accelerated applications. This list is only a subset of applications that have been accelerated by GPU computing. Many applications are in-house and do not make it on to this list.
GPUs everywhere
The wide adoption of CUDA requires that every developer who needs a GPU to develop CUDA code and port applications. Many years before, NVIDIA decided that every GPU designed at NVIDIA will support CUDA architecture:
- GeForce GPUs for gaming and notebooks
- Quadro GPUs for professional visualization
- Datacenter GPUs
- Tegra for embedded SoCs
A single compute architecture across all product lines with backward compatibility of CUDA makes this platform a developer’s choice. You can access GPUs in laptops and PCs, workstations, servers, and embedded devices—and run the same CUDA code everywhere. Every cloud service provider on the planet powers CUDA-supported GPUs.
Summary
NVIDIA is committed to having a wide and rich ecosystem support for CUDA developers. A large team of engineers is continually working to make sure that you can get all the right tools. Here is what CUDA developers can take advantage of :
- Development of CUDA code with rich programming language support and development environment tools like debugger, profiler, and so on.
- Drop-in acceleration to an application by tuned, tested, and maintained libraries.
- Ease of deployment with tuned and tested containers and their availability on NVIDIA NGC.
- Tools to support scaling out applications in a cluster environment.
- A wider range of applications accelerated using CUDA.
Pradeep Gupta
Director, Solutions Architecture and Engineering Team, NVIDIA