Tokunbo Ogunfunmi, Professor of Electrical Engineering and Director of the Signal Processing Research Laboratory at Santa Clara University, presents the “New Methods for Implementation of 2-D Convolution for Convolutional Neural Networks” tutorial at the September 2020 Embedded Vision Summit.
The increasing usage of convolutional neural networks (CNNs) in various applications on mobile and embedded devices and in data centers has led researchers to explore application specific hardware accelerators for CNNs. CNNs typically consist of a number of convolution, activation and pooling layers, with convolution layers being the most computationally demanding. Though popular for accelerating CNN training and inference, GPUs are not ideal for embedded applications because they are not energy efficient.
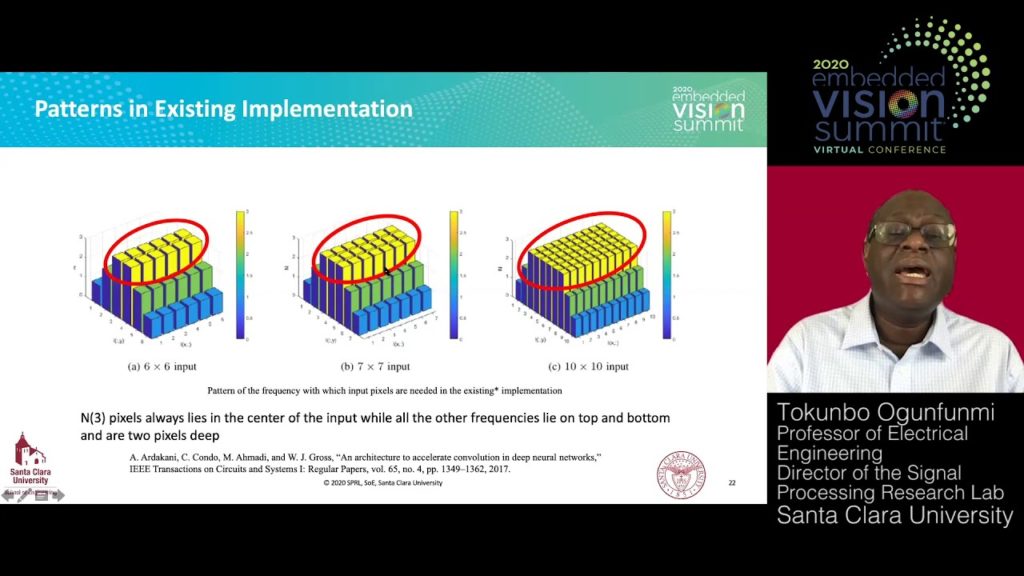
ASIC and FPGA accelerators have the potential to run CNNs in a highly efficient manner. Ogunfunmi presents two new methods for 2-D convolution that offer significant reduction in power consumption and computational complexity. The first method computes convolution results using row-wise inputs, as opposed to traditional tile-based processing, yielding considerably reduced latency. The second method, single partial product 2-D (SPP2D) convolution, avoids recalculation of partial weights and reduces input reuse. Hardware implementation results are presented.
See here for a PDF of the slides.