
This technical article was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
Transportation monitoring systems, healthcare, and retail have all benefited greatly from intelligent video analytics (IVA). DeepStream is an IVA SDK. DeepStream enables you to attach and detach video streams in runtime without affecting the entire deployment.
This post discusses the details of stream addition and deletion work with DeepStream. I also provide an idea about how to manage large deployments centrally across multiple isolated datacenters, serving multiple use cases with streams coming from many cameras.
The NVIDIA DeepStream SDK is a streaming analytics toolkit for multisensor processing. Streaming data analytics use cases are transforming before your eyes. IVA is of immense help in smarter spaces. DeepStream runs on discrete GPUs such as NVIDIA T4, NVIDIA Ampere Architecture and on system on chip platforms such as the NVIDIA Jetson family of devices.
DeepStream has flexibility that enables you to build complex applications with any of the following:
- Multiple deep learning frameworks
- Multiple streams
- Multiple models combining in series or in parallel to form an ensemble
- Multiple models working in tandem
- Compute at different precisions
- Custom preprocessing and post-processing
- Orchestration with Kubernetes
DeepStream application can have multiple plug-ins, as shown in Figure 1. Each plug-in as per the capability may use GPU, DLA, or specialized hardware.
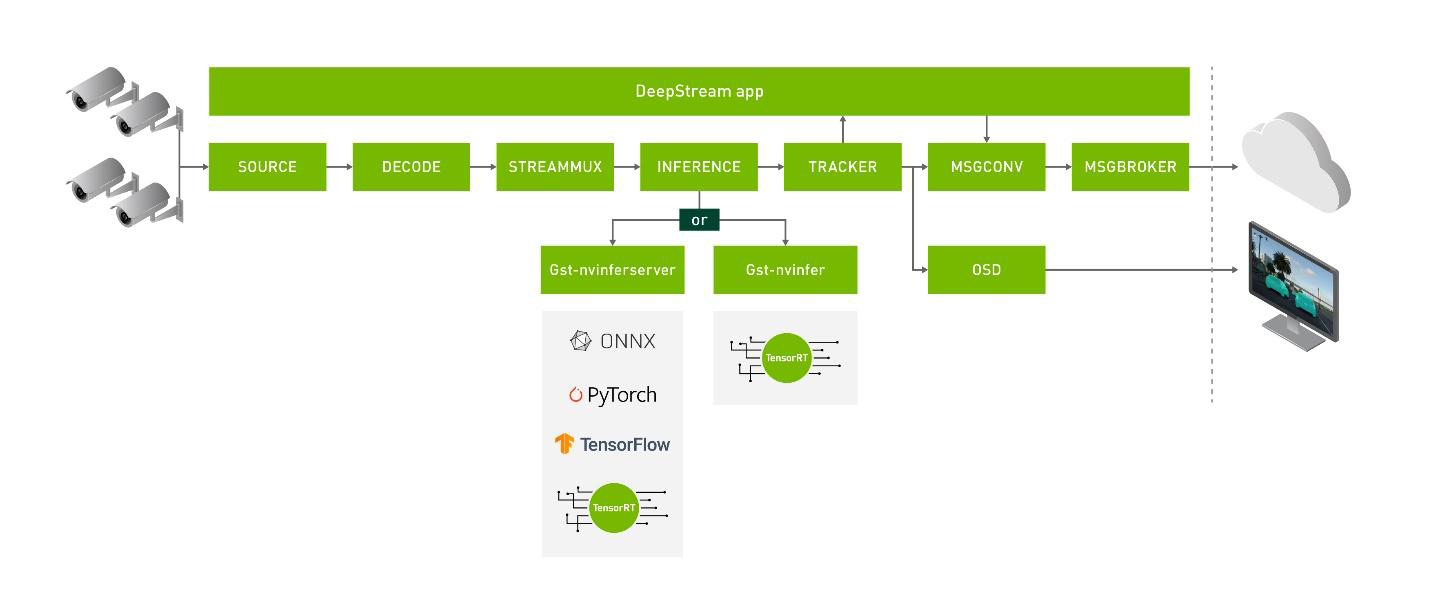
Figure 1. Showing integration of nvinferserver and nvinfer plug-in with DeepStream. Nvinfer server can work with backends like ONNX, TensorFlow, PyTorch, and TensorRT. It also enables creating ensemble models.
DeepStream is fundamentally built to allow deployment at scale, making sure throughput and accuracy at any given time. The scale of any IVA pipeline depends on two major factors:
- Stream management
- Compute capability
Stream management is a vital aspect of any large deployment with many cameras. Any large deployment cannot be brought down to add/remove streams. Such large deployment must be made failsafe to handle spurious streams in runtime. Also, the deployment is expected to handle runtime attachment/detachment of the use case to the pipeline running with specific models.
This post helps you in understanding the following aspects of stream management:
- Stream consumption with DeepStream Python API
- Adding and removing streams in runtime
- Attaching specific stream to pipeline with specific models in runtime
- Stream management on large-scale deployment involving multiple data centers
As the application grows in complexity, it becomes increasingly difficult to change. A well-thought-out development strategy from the beginning can help a long way. In the next section, I discuss different ways to develop a DeepStream application briefly. I also discuss how to manage streams/use-case allocation and deallocation and consider some of the best practices.
DeepStream application development
DeepStream enables you to create seamless streaming pipelines for AI-based video, audio, and image analytics. DeepStream gives you the choice of developing in C or Python, providing them more flexibility. DeepStream comes with several hardware-accelerated plug-ins. DeepStream is derived From Gstreamer and offers and unified API between Python and C language.
Python and C API for DeepStream are unified. This means any application developed in Python can be easily converted to C and the reverse. Python and C provide all the levels of freedom to the developer. With DeepStream Python and C API, it is possible to design dynamic applications that handle streams and use-cases in runtime. Some example Python applications are available at: NVIDIA-AI-IOT/deepstream_python_apps.
The DeepStream SDK is based on the GStreamer multimedia framework and includes a GPU-accelerated plug-in pipeline. Plug-ins for video inputs, video decoding, image preprocessing, NVIDIA TensorRT-based inference, object tracking, and display are included in the SDK to make the application development process easier. These features can be used to create multistream video analytics solutions that are adaptable.
Plug-ins are the core building block with which to make pipelines. Each data buffer in-between the input (that is, the input of the pipeline, for example, camera and video files) and output (for example, the screen display) is passed through plug-ins. Video decoding and encoding, neural network inference, and displaying text on top of video streams are examples of plug-ins. The connected plug-in constitutes a pipeline.
Pads are the interfaces between plug-ins. When data flows from one plug-in to another plug-in in a pipeline, it flows from the Source pad of one plug-in to the Sink pad of another. Each plug-in might have zero, one, or many source/sink components.
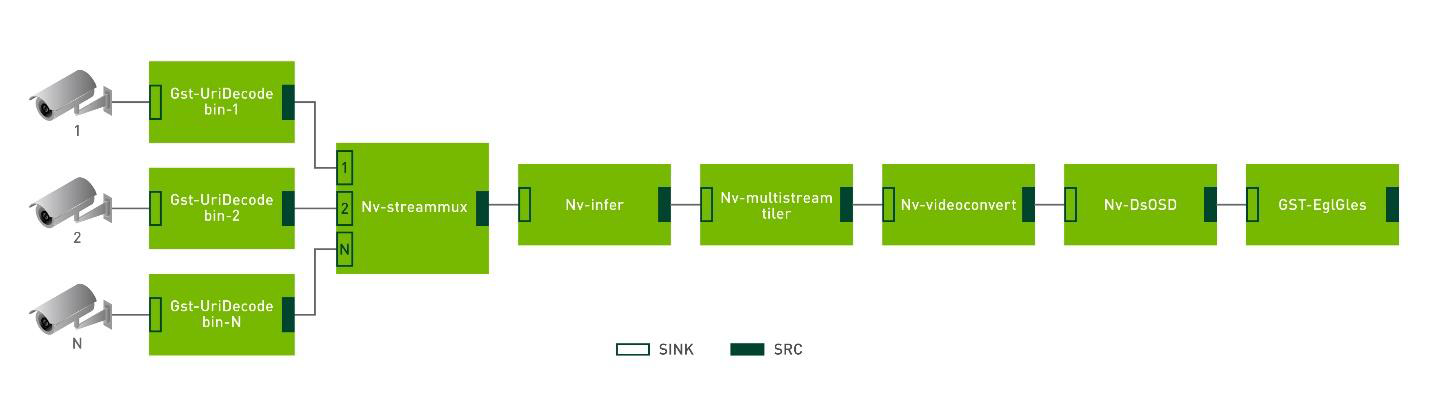
Figure 2. The simplified DeepStream application with multiple stream support.
The earlier example application consists of the following plug-ins:
GstUriDecodebin: Decodes data from a URI into raw media. It selects a source plug-in that can handle the given scheme and connects it todecodebin.Nvstreammux: TheGst-nvstreammuxplug-in forms a batch of frames from multiple input sources.Nvinfer: TheGst-nvinferplug-in does inferencing on input data using TensorRT.Nvmultistream-tiler: TheGst-nvmultistreamtilerplug-in composites a 2D tile from batched buffers.Nvvideoconvert:Gst-nvvideoconvertperforms scaling, cropping, and video color format conversion.NvDsosd:Gst-nvdsosddraws bounding boxes, text, and region of interest (ROI) polygons.GstEglGles:EglGlesSinkrenders video frames on an EGL surface (xOverlay interface and Native Display).
Each plug-in can have one or more source and sink pads. In this case, when the streams are added, the Gst-Uridecodebin plug-in gets added to the pipeline, one for each stream. The source component from each Gst-Uridecodebin plug-in is connected to each sink component on the single Nv-streammux plug-in. Nv-streammux creates batches from the frames coming from all previous plug-ins and pushes them to the next plug-in in the pipeline. Figure 3 shows how multiple camera streams are added to the pipeline.
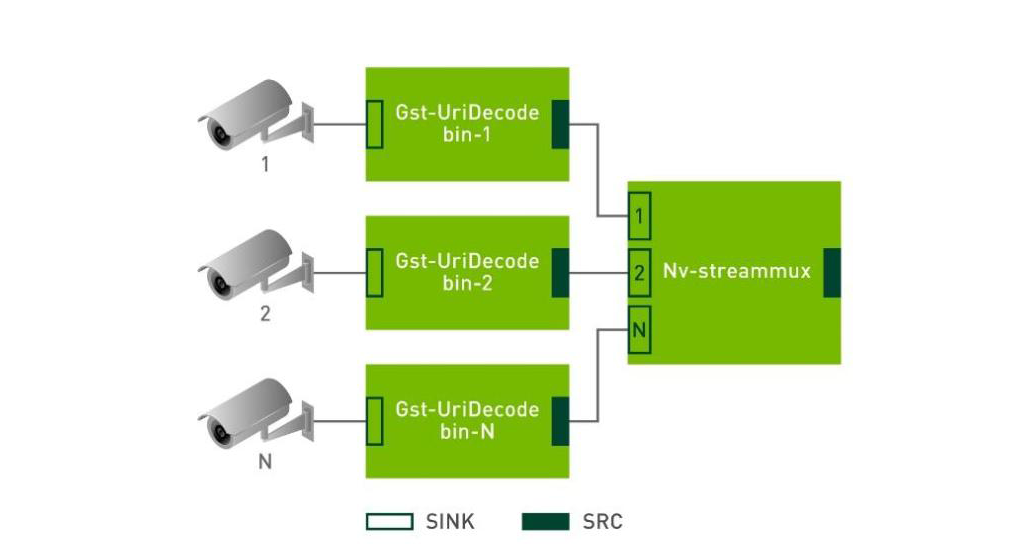
Figure 3. Showing Pads as the linking interfaces between plug-ins.
Buffers carry the data through the pipeline. Buffers are timestamped, contain metadata attached by various DeepStream plug-ins. Buffer carries information such as how many plug-ins are using it, flags, and pointers to objects in memory.
DeepStream applications can be thought of as pipelines consisting of individual components plug-ins. Each plug-in represents a functional block like inference using TensorRT or multistream decode. Where applicable, plug-ins are accelerated using the underlying hardware to deliver maximum performance. DeepStream’s key value is in making deep learning for video easily accessible, to allow you to concentrate on quickly building and customizing efficient and scalable video analytics applications.
Runtime stream addition/deletion application
DeepStream provides sample implementation for runtime add/delete functionality in Python and C languages. The samples are located at the following locations:
- DeepStream source add remove (C): https://github.com/NVIDIA-AI-IOT/deepstream_reference_apps/tree/master/runtime_source_add_delete
- DeepStream source add remove (Python): https://github.com/NVIDIA-AI-IOT/deepstream_python_apps/tree/master/apps/runtime_source_add_delete
These applications are designed keeping simplicity in mind. These applications take one input stream, and the same stream is added multiple times to the running pipeline after a set interval of time. This is how a specified number of streams are added to the pipeline without restarting the application. Eventually, each stream is removed at every interval of time. After the last stream is removed, the application gracefully stops.
To start with the sample applications, follow these steps.
To create a Python-based application
- Pull the DeepStream Docker image from ngc.nvidia.com.
- Run git clone on the Python application repository within the Docker container.
- Go to the following location within the Docker container: deepstream_python_apps/apps/runtime_source_add_delete
- Set up the Python prerequisites.
- Go to apps/runtime_source_add_delete and execute the application as follows:
python3 deepstream-test-rt-src-add-del.py <uri> python3 deepstream_rt_src_add_del.py file:///opt/nvidia/deepstream/deepstream-<VER>/samples/streams/sample_720p.mp4
To create a C-based application
- Pull the DeepStream Docker image from ngc.nvidia.com. :
- Run git clone on the C application repository at
/opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/within the Docker container. - Go to
deepstream_reference_apps/runtime_source_add_deleteand compile and run the application as follows:
make ./deepstream-test-rt-src-add-del <uri> ./deepstream-test-rt-src-add-del file:///opt/nvidia/deepstream/deepstream-<VER>/samples/streams/sample_720p.mp4
Application aspect: Runtime camera add-remove
DeepStream Python or C applications usually take input streams as a list of arguments while running the script. After code execution, a sequence of events takes place that eventually adds a stream to a running pipeline.
Here, you use the uridecodebin plug-in that decodes data from a URI into raw media. It selects a source plug-in that can handle the given scheme and connects it to a decode bin.
Here’s the list of sequence that takes place to register any stream:
- The source bin is created from
Curidecodebinplug-in by the functioncreate_uridecode_bin. The functioncreate_uridecode_bintakes the first argumentsource_id, which is an integer, and the second argument isrtsp_url. In this case, this integer is the order of the stream from 1…..N. This integer is used to create a uniquely identifiablesource-binname assource-bin-1,source-bin-2,…source-bin-N. g_source_bin_listdictionary maps between thesource-binandidvalue.- After the source bin is created, the RTSP stream URLs from arguments to the program are attached to this source bin.
- Later, the source-bin value of
uridecodebinis linked to the sink-bin of the next plug-in,streammux. - Such multiple
uridecodebinplug-ins are created, each for one stream, and attached tostreammuxplug-in.
The following code example shows the minimal code in Python to attach multiple streams to a DeepStream pipeline.
g_source_bin_list = []
for i in range(num_sources):
print("Creating source_bin ",i," \n ")
uri_name=argv[i]
if uri_name.find("rtsp://") == 0 :
is_live = True
#Create source bin and add to pipeline
source_bin=create_uridecode_bin(i, uri_name)
g_source_bin_list[rtsp[i]] = source_bin
pipeline.add(source_bin)
In a more organized application, these lines of code responsible for stream addition are shifted to a function that takes two arguments to attach a stream: stream_id and rtsp_url. You can call such a function anytime and append more streams to the running application.
Similarly, when the stream must be detached from the application, the following events take place:
source_idof the already attached stream is given to the functionstop_release_source.sink-padofstreammuxattached to thesource_idto be released is detached from thesource binofuridecodebin.- The source bin of uridecodebin is then removed from the pipeline.
- The active source count is decreased by one.
The following code example shows a minimal code for Python and C to detach streams from a DeepStream pipeline.
def stop_release_source(source_id):
pad_name = "sink_%u" % source_id
print(pad_name)
#Retrieve sink pad to be released
sinkpad = streammux.get_static_pad(pad_name)
#Send flush stop event to the sink pad, then release from the streammux
sinkpad.send_event(Gst.Event.new_flush_stop(False))
streammux.release_request_pad(sinkpad)
#Remove the source bin from the pipeline
pipeline.remove(g_source_bin_list[source_id])
source_id -= 1
g_num_sources -= 1
Deployment aspect: Runtime camera and use case management
Earlier, I discussed how to add and remove streams from the code. There are a few more factors, considering the deployment aspect.
Previously, you took all the input streams with command-line arguments. However, after the program is executed and while it is in deployment, you cannot provide any additional argument to it. How do you pass instructions to the running program on which stream to attach or detach?
Deployment required additional code that takes care of periodically checking whether there are new streams available that must be attached. The following streams should be deleted:
- Stream no longer requires monitoring.
- Camera issues lead to no streams.
- Previously attached stream must be used for another use case.
In the case of multiple data centers for stream processing, give priority to the stream source nearest to the data center.
The DeepStream pipeline runs in the main thread. A separate thread is required to check for the stream to be added or deleted. Thankfully, Glib has a function named g_timeout_add_seconds. Glib is the GNU C Library project that provides the core libraries for the GNU system and GNU/Linux systems, as well as many other systems that use Linux as the kernel.
g_timeout_add_seconds (set) is a function to be called at regular intervals when the pipeline is running. The function is called repeatedly until it returns FALSE, at which point the timeout is automatically destroyed, and the function is not called again.
guint g_timeout_add_seconds (guint interval, GSourceFunc function, gpointer data);
g_timeout_add_seconds takes three inputs:
Interval: The time between calls to the function, in seconds.function: The function to call.data: The data and arguments to pass to the function.
For example, you call a function watchDog and it takes GSourceBinList. A dictionary map between streamURL and streamId. streamId is an internal ID (Integer) that gets generated after the stream is added to the pipeline. The final caller function looks like the following code example:
guint interval = 10; guint g_timeout_add_seconds (interval, watchDog, GSourceBinList, argv);
As per the current interval setting, the watchDog function is called every 10 seconds. A database must be maintained to manage and track many streams. Such an example database table is shown in Table 1. The function watchDog can be used to query a database where a list of all the available streams against their current state and use case is maintained.
| Source ID | RTSP URL | Stream State | Use case | Camera Location | Taken |
| 1 | Rtsp://123/1.mp4 |
ON | License Plate Detection | Loc1 | True |
| 2 | Rtsp://123/2.mp4 |
BAD STREAM | License Plate Detection | Loc2 | False |
| 3 | Rtsp://123/3.mp4 |
OFF | Motion Detection | Loc2 | False |
| n | Rtsp://123/n.mp4 |
OFF | Social Distance | Loc3 | False |
Here’s an example of the bare minimum database structure (SQL/no-SQL) needed to manage many streams at the same time:
- Source ID: A unique ID, which is also the sink pad ID of
nvstreammuxwhere it is connected to.source_idwould be useful to monitornv-gstevents, for example, pad added deleted EOS for each stream. Remember that in the earlier simple app, you considered making source bin assource-bin-1,source-bin-2,…source-bin-N in order of argument input. You use the same method with many cameras and track all active source bins in the application scope. - RTSP URL: The URL that the source plug-in should use.
- Stream state: Helps in managing the states of the stream such as ON or OFF. The database client must also be able to change the camera, such as BAD STREAM, NO STREAMm CAMERA FAULT, and so on, according to what is perceived by the client. This can help in instant maintenance.
- Use case: Assigns a use case to the camera. This use case is checked and only those cameras whose model is currently active are attached.
- Camera Location: Helps with the localization of the compute based on the cameras’ location. This check avoids unnecessary capture from a camera located at distant locations and could be better assigned to other nearby compute clusters.
- Taken: Assume that deployment is multiple GPUs with multiple nodes. When a DeepStream application running on any machine and any GPU adds any source, it sets the flag to
True. This prevents another instance from repeatedly adding the same source again.
Maintaining a schema as described enables easy dashboard creation and monitoring from a central place.
Returning to the watchDog function, here’s the pseudo-code to check for the stream state and attach a new video stream according to the location and use cases:
FUNCTION watchDog (Dict: GSourceBinList) INITIALIZE streamURL ⟵ List ▸ Dynamic list of stream URLs INITIALIZE streamState ⟵ List ▸ Dynamic list of state corresponding to stream URLs INITIALIZE streamId ⟵ Integer ▸ variable to store id for new stream streamURL, streamState := getCurrentCameraState() FOR X = 1 in length(streamState) IF ((streamURL[X] IN gSourceBinList.keys()) & (streamState[X] == "OFF")) stopReleaseSource(streamURL[X]) ▸ Detach stream streamURL, streamState := getAllStreamByLocationAndUsecase() FOR Y = 1 in length(streamState) IF ((streamURL[Y] NOT IN gSourceBinList.keys()) & (streamState [Y] == "ON") streamId := addSource(streamURL[Y]) ▸ Add new stream GSourceBinList(streamURL, streamId) ▸ update mappings RETURN GSourceBinList
- An application enters the main function after module loading and global variable initialization.
- In the main function, the local modules and variables are initialized.
- As the application starts for the first time, it requests the list of streams from the database after location and use case filters are applied.
- After receiving the stream list ,all the plug-ins of the DeepStream pipeline are initialized, linked, and set to the
PLAYstate. At this point, the application is running with all the streams provided. - After every set interval of time, a separate thread checks for the state of the current stream in the database. If the state of any already-added stream is changed to
OFFin the database, the stream is released. The thread also checks if a new camera is listed in the database withONstate, the stream is added to the DeepStream pipeline after applying location and use case filter. - After the stream is added, the flag in the
Takencolumn of the database must be set toTrueso that no other process can add the same stream again.
Figure 4 shows the overall flow of the functional calls required to efficiently add remove camera stream and attach to the server running with an appropriate model.
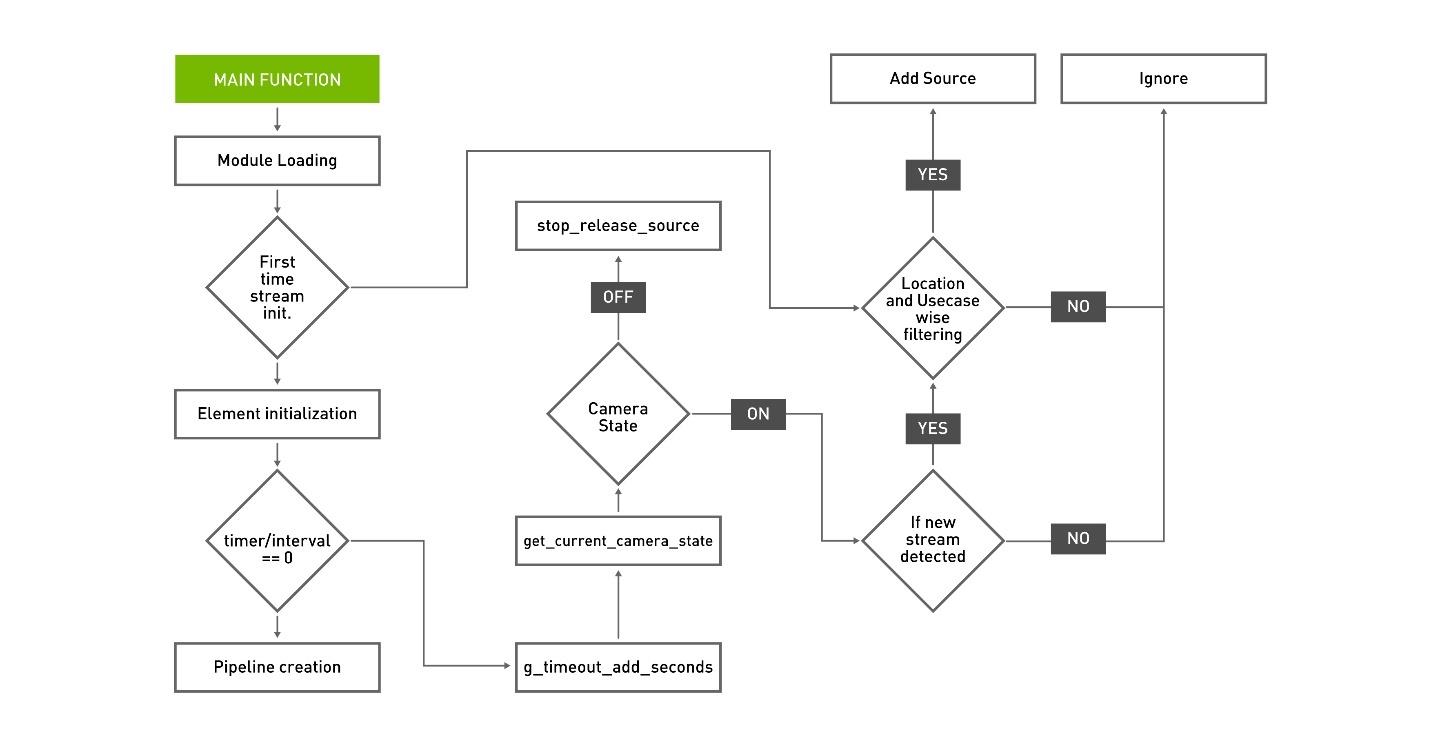
Figure 4. Overall control flow to manage streams and attach/detach use cases.
ust changing the number of sources does not help, as downstream components to the source must be able to change their properties according to the number of streams. For this purpose, components of the DeepStream application are already optimized to change properties in runtime.
However, many of the plug-ins use batch size as a parameter during initialization to allocate compute/memory resources. In this case, we recommend specifying maximum batch size while executing the application. Table 2 shows a few such plug-in examples:
| Plug-ins | Functionality | Runtime changes |
| Gst-nvstreammux | Forms a batch of frames from multiple input sources. | The muxer supports the addition and deletion of sources at run time. |
| Gst-nvdsanalytics | Performs analytics on metadata attached by nvinfer (primary detector) and nvtracker. |
If the runtime stream resolution is different from the configuration resolution. The plug-in handles the resolution change and scales the rules for the runtime resolution. |
| Gst-nvinfer | Performs inferencing on input data using TensorRT. | Enables the reconfiguration of batch size according to number of the stream at runtime. |
| Gst-nvinferserver | Performs inferencing on input data using NVIDIA Triton Inference Server. | Enables the reconfiguration of batch size according to number of the stream at runtime. |
| Gst-nvmultistreamtiler | Composites a 2D tile from batched buffers. | Reconfigures 2D tile for new sources added at runtime. |
| Gst- nvtracker | Enables the DS pipeline to use a low-level tracker to track the detected objects with unique IDs. | Supports tracking on new sources added at runtime and cleanup of resources when sources are removed. |
You can explicitly change the property when the number of streams is detected. To manually tweak the properties of the plug-in at runtime, use the set_property function in Python and C or the g_object_set function in C.
Best practices
- Always check your stream properties before adding to the pipeline. Stream properties can be checked with the
gst-discoverer-1.0command-line utility. It accepts a URI from the command line and prints all information regarding the stream. It is useful to find out what container and codecs have been used to produce the media, and therefore what plug-ins you must put in a pipeline to play it. Gst-Discover can be used with Python and C by using the respective APIs. - Profile the DeepStream application when it is developed. This is the first step in optimizing and tuning your application. Profiling helps in the understanding of an application’s performance characteristics and can easily identify parts of the code that present opportunities for improvement. Find hotspots and bottlenecks in your application to help you decide where to focus your optimization efforts.
- Count the maximum number of streams that can be run on GPU by profiling the application. At runtime, make sure that you keep the maximum stream below the maximum supported number so that your application performance remains stable.
To increase performance, consult the DeepStream troubleshooting manuals.
For more information, see the following resources:
- NVIDIA DeepStream SDK Quickstart Guide
- GStreamer Tutorials
- DeepStream Basics: iPython notebooks
- DeepStream performance optimization cycle lab
Sunil Patel
Deep Learning Data Scientist, NVIDIA