This blog post was originally published by SOYNET. It is reprinted here with the permission of SOYNET.
To deliver the best end-user experience for your consumers, lower the cost of AI installations, and increase ROI for your AI initiatives, AI inference performance at scale is crucial. Currently, businesses face many problems in implementing AI in real-time.
SoyNet is an inference-only framework
Current business applications run on devices requiring inference/output to be fast and require substantial memory. In most frameworks like Tensorflow, and Pytorch, training and inference are combined to run an AI model. It takes a considerable portion of memory, making the inference slower. Hence, although perfect for training models, these frameworks may not be suitable for inference.
SOYNET focuses on inference only by eliminating the training engine. SoyNet is a proprietary technology that reduces memory consumption and optimizes AI models to run faster than other frameworks.
Benefits of SoyNet
- It can support customers to provide AI applications and AI services in time (Time to Market)
- It can help application developers execute AI projects without additional technical AI knowledge and experience.
- It can help customers to reduce H/W (GPU, GPU server) or Cloud Instance cost for the same AI execution (Inference)
- It can support customers to respond to real-time environments that require very low latency in AI inference.
Features of SoyNet
- Supports NVIDIA and non-NVIDIA GPUs (based on technologies such as CUDA and OpenCL, respectively)
- Optimization for models in computer vision, NLP, time series, and GAN available.
- Library files to be easily integrated with customer applications DLL file (Windows), so file (Linux) with header or *.lib for building in C/C++
- Integration with the application using SoyNet APIs is easy.
- It can be deployed easily on the cloud, on-premises and edge devices.
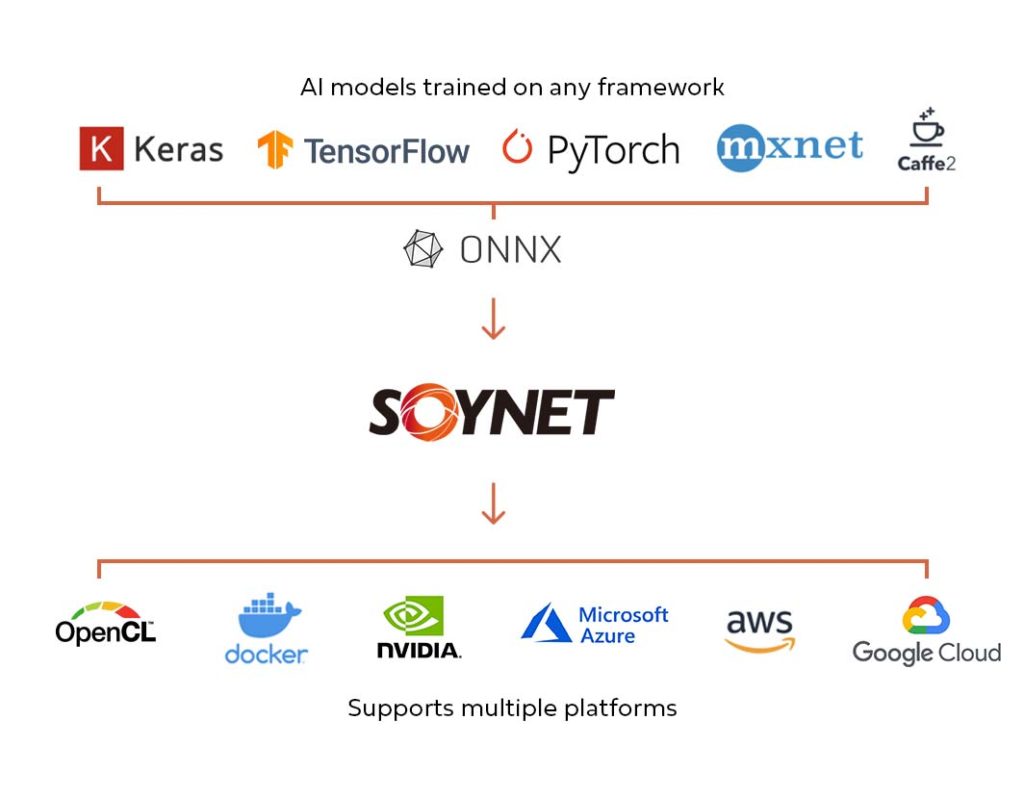
Process:
- Input to SoyNet is the pre-trained weights from common frameworks like ONNX, Pytorch and Tensorflow.
- SoyNet converter converts these into SoyNet weight files.
- It combines the converted weight with the model-specific configuration to make an engine file for Inference.
- Weight extraction codes may vary depending on the structure of the AI framework or custom usage used by the model. Hence SoyNet can support various AI models, including computer vision, NLP and GAN.
- SoyRT is a component that uses CUDA and cuDNN to optimize the model structure according to the inference code.
- We provide the SoyNet-optimized model in a bin folder which can be containerized in a docker file.
- To integrate with your application, you can use C++, Java or Python to call SoyNet APIs.
| Functions | Description |
| void* initSoyNet(char* cfg_file, char* extend_param) | Initialize SoyNet inference engine handle extended_param can contains as follows – BATCH_SIZE, ENGINE_SERIALIZE, DATA_LEN, ENGINE_FILE, WEIGHT_FILE, LOG_FILE, LICENSE_FILE |
| void feedData(void* soynet, input) | Fill the input data for inference |
| void inference(void* soynet) | Execute inference process on GPU |
| void getOutput(void* soynet, void* output) | Get the result from inference |
| void freeSoyNet(void* soynet) | Destroy SoyNet inference engine handle |
What makes SoyNet faster than other frameworks?
SoyNet’s proprietary technology makes the model lightweight and faster to run under any setup and environment. SoyNet uses pointer * to save memory when referring to big images. SoyNet accelerates speed by reducing the bottleneck between CPU and GPU (often, custom layer causes to run them on CPU instead of GPU). Along with this, SoyNet also works on model optimization from 32-bit to 16-bit.
With SoyNet, the AI developer/engineer job will now focus only on research and AI development tasks. They no longer need to worry about the application side and vice-versa.
To learn about how to use SoyNet in detail, please check our document “Getting Started with SoyNet” which has a detailed explanation of hardware and software requirements along with the other processes to deploy SoyNet.
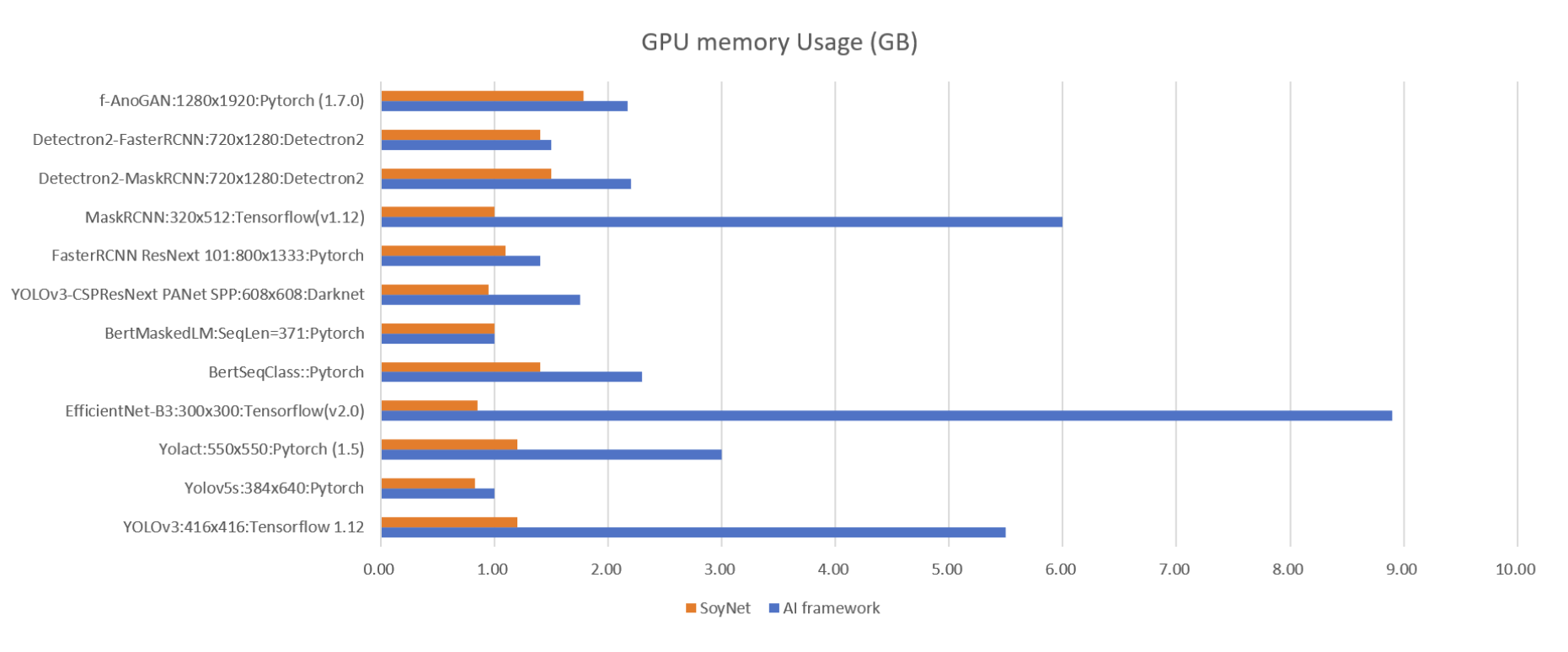
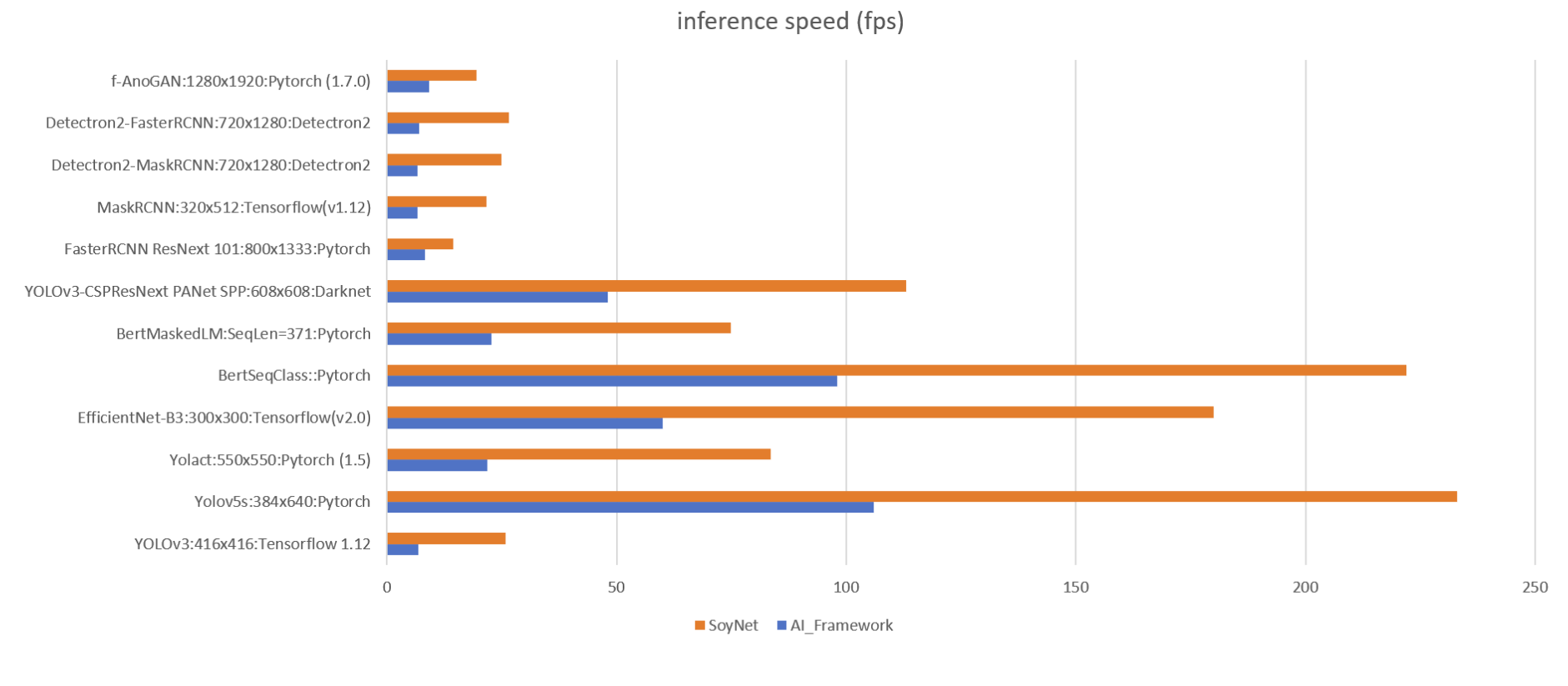
Benchmarks
Some of the benchmarks SoyNet has achieved are listed below. More on the Model Market page.
Pricing
Currently, we use a subscription pricing approach.
Free: Optimized models ready to download with a 5-GPU license.
Standard: Optimized models ready to download, along with consultation and an unlimited-GPU license.
Enterprise: Custom model consultation for optimization and other partnership opportunities. Contact us on [email protected] or post a message on our contact-us page.
Sweta Chaturvedi
Global Marketing Manager, SOYNET