
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
From how AI started to how it impacts you today, here’s your comprehensive AI primer
When you hear Artificial Intelligence (AI): Do you think of the Terminator or Data on “Star Trek: The Next Generation”? While neither example of artificial general intelligence is available today, AI has given rise to a form of machine intelligence. And it’s trained on huge publicly available data, proprietary data and/or sensor data.
As we embark on our AI on the Edge series, we’d like to explain exactly what we mean by “AI” — especially since this broad category can include everything from machine learning to neural networks and deep learning. Don’t be embarrassed: “What is AI, exactly?” requires a more technical and nuanced answer than you might expect.
Alan Turing, an outstanding mathematician, introduced the concept of “Computing Machinery and Intelligence.”

History of AI: The origins of AI research
Answering “what is AI” is much easier when you know the history of AI.
By the 1950s, the concept of AI had taken its first steps out of science fiction and into the real world as we began to build capable electronic computers. Researcher Alan Turing began to explore the mathematical possibility of building AI. He suggested that machines, like humans, can use information and reasoning to solve problems and make decisions.
These concepts were introduced in his famous 1950 paper titled “Computing Machinery and Intelligence,” in which he discussed the potential for intelligent machines and proposed a test of their intelligence, now called the Turing Test. The test posits that if a machine can carry on a conversation (over a text interface) that is indistinguishable from a conversation with a human being, then it is reasonable to say that the machine is “thinking.” Using this simplified test, it is easier to argue that a “thinking machine” is at least plausible.
The world’s first programmable, electronic, digital computers were limited in terms of performance.

AI’s proof of concept
In the 1950s, computers were still very limited and very expensive to own and operate, limiting their use in further AI research. Yet, researchers were not deterred. Five years later, a proof of concept was initiated with a program called Logic Theorist, likely the first AI program to be written. In 1956, the program was shown at the Dartmouth Summer Research Project on Artificial Intelligence (DSRPAI). This historic conference brought together top researchers from various fields for an open-ended discussion on AI, the term which was coined at the event by host John McCarthy, then a mathematics professor at Dartmouth.
From 1957 to 1974, AI research flourished as computers could store more information and became faster, cheaper and more accessible. Machine learning algorithms also improved and people became better at knowing which algorithm to apply to their problem. But mainstream applications were few and far between, and AI research money began to dry up. The optimistic vision of AI researchers like Marvin Minsky in the ‘60’s and ‘70’s looked to be going nowhere.
Deep learning took off due to increased processing capabilities, the abundance of data, and improved AI algorithms.

Modern day leaps in AI
Continued improvements in computing and data storage reinvigorated AI research in the 1980s. New algorithms and new funding fed an AI renaissance. During this period, John Hopfield and David Rumelhart popularized “deep learning” techniques which allowed computers to learn using experience.
This milestone was followed with certain landmark events. In 1997, IBM’s chess playing computer, Deep Blue, defeated reigning world chess champion and grandmaster Gary Kasparov. It was the first time a reigning world chess champion had lost to a computer. In the same year, speech-recognition software, developed by Dragon Systems, became widely available. In 2005, a Stanford robot vehicle won the DARPA Grand Challenge by driving autonomously for 131 miles along an unrehearsed desert trail. And just two years later, a vehicle from Carnegie Mellon University won the DARPA Urban Challenge by autonomously navigating 55 miles in an urban environment while avoiding traffic hazards and following all traffic laws. Finally, in February 2011, in a “Jeopardy!” quiz show exhibition match, IBM’s question answering system, named Watson, defeated the two greatest “Jeopardy!” champions of the day.
Exciting as they were, these public demonstrations weren’t mainstream AI solutions. The DARPA challenges, though, did spur autonomous vehicle research that continues to this day.
What really kicked off the explosion in AI applications was the use of math accelerators like graphics processing units (GPUs), digital signal processors (DSP), field programmable gate arrays (FPGA) and neural processing units (NPUs), which increased processing speeds by orders of magnitude over mere CPUs.
While CPUs can process tens of threads, math accelerators like DSPs, GPUs, and NPUs process hundreds or thousands of threads all in parallel. At the same time, AI researchers also got access to vast amounts of training data through cloud services and public data sets.
In 2018, large language models (LLMs) trained on vast quantities of unlabeled data became the foundation models that can be adapted to a wide range of specific tasks. More recent models, such as GPT-3 released by OpenAI in 2020, and Gato released by DeepMind in 2022, pushed AI capabilities to new levels. These generative AI models have made AI more useful for a much wider range of applications. Where previous uses of AI were mostly about recognition such as detecting bad parts in a product line, classification such as recognizing faces in a video feed, and prediction such as determining the path of an autonomous vehicle, generative AI can be used to create new text, images, or other content based on input prompts.
Digital neurons, inspired by biological neurons, are the building blocks of digital neural networks.
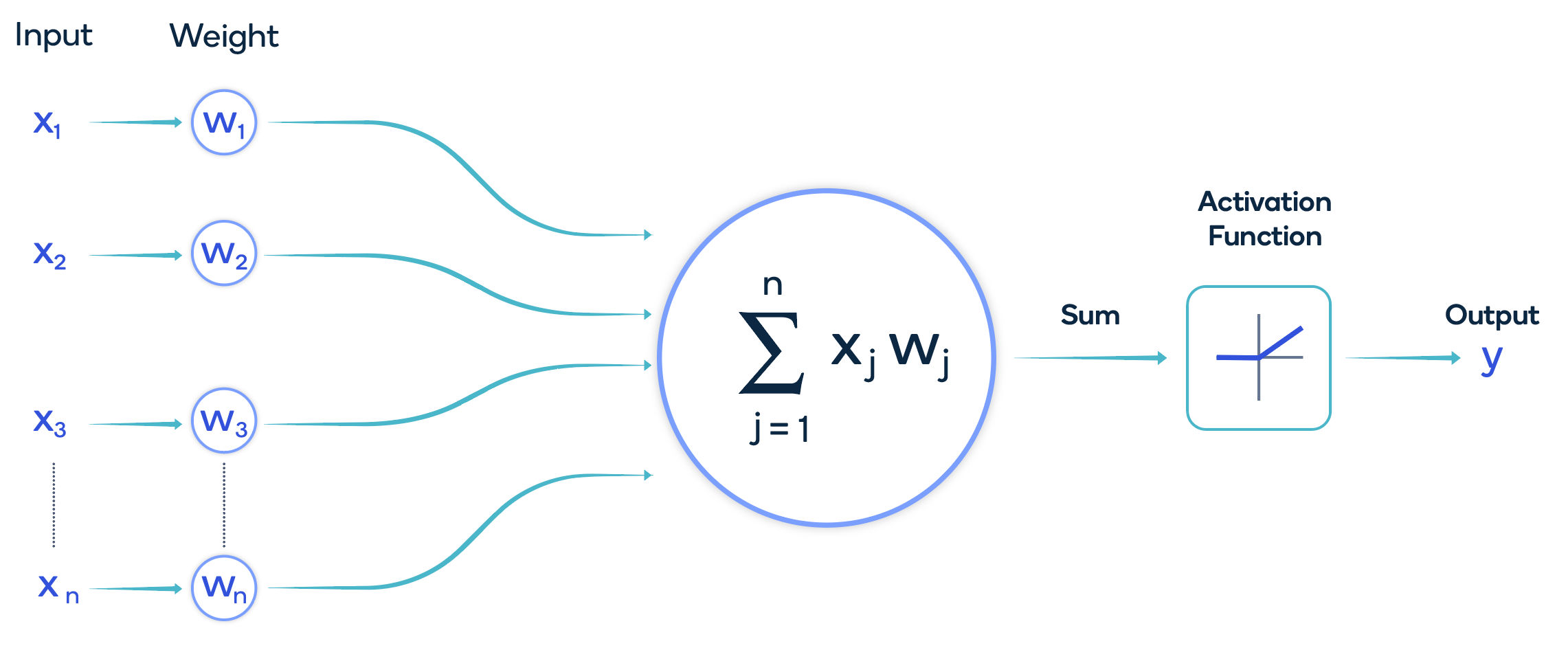
How AI works and AI technology definitions
The fundamental approach of modern AI is inspired by the way that animal brains (including human brains) function using a digital neuron modeled after those of the biological brain. Collections of these digital neurons process an input in different layers with the results of each layer feeding the next layer. This structure is called a neural network. Each neuron has multiple inputs that are each given a specific weight. The weighted inputs are summed together, and the output is fed to an activation function. An activation function, such as the popular rectified linear unit, known as a ReLU, introduces the property of nonlinearity to a deep learning model. The outputs of the activation function are the inputs into the next layer of the neural network. The collective weights and any bias applied to the summation function represent the parameters of the model.
Neural network architectures vary in the number of interconnected neurons per layer and the number of layers, which all impact accuracy at the cost of performance, power and size.
A deep neural network consists of multiple hidden layers between the input and output layers.

The deep in deep learning
The “deep” in “deep learning” refers to the use of many layers in the network. Major increases in computing power, especially as delivered by GPUs, NPUs and other math accelerators, by around a thousand-fold or more make the standard backpropagation algorithm feasible for training networks that are many layers deeper and have reduced training times from many months to days.
The values of digital neuron parameters are determined through a learning process. Humans learn throughout life from experiences and our senses. Because AI itself does not have life experiences or senses, it must learn through a digital imprint that’s called training.
Neural networks “learn” (or are trained) by processing examples.
In supervised learning, the examples contain known “inputs” and “outputs,” which form probability-weighted associations between the two in the digital neuron that are stored within the data structure of the neural network itself (called the “model”).
The training of a neural network from a given example is usually conducted by determining the difference between the processed output of the network (often a prediction) and a desired output. Minimizing the difference between the prediction and the desired output is then used to adjust the network iteratively until it converges to the desired accuracy. This algorithm is called backpropagation.
The more data you feed the neural network, the more examples it accumulates knowledge about. That said, the neural network model itself needs to be relatively large to represent complex sets of information.
Also, a significant number of examples need to be used in training large models to make them more capable and accurate.
The trained neural network model is then used to interpret new inputs and create new outputs. This application of the model processing new data is commonly called inference. Inference is where an AI model is applied to real-world problems.
Training is often performed with 32-bit or 16-bit floating point math, but inference models can often be scaled down to 8-bit or 4-bit integer precision to save memory space, reduce power and improve performance without significantly affecting accuracy of the model. This scaling down is known as quantization, and going from 32-bit to 8-bit reduces the model size by one-fourth.
A variety of neural network architectures have been introduced over time, offering benefits in performance, efficiency and/or capabilities.
Well-studied neural network architectures, like convolutional neural networks (CNNs), recurrent neural networks (RNNs) and long short-term memory (LSTM) have been used to detect, classify, and predict and have been widely deployed for voice recognition, image recognition, autonomous vehicles and many other applications.
A recently-popular class of latent variable models called diffusion models, can be used for a number of tasks including image denoising, inpainting, super-resolution upscaling, and image generation. This technique helped start the popularization of generative AI. For example, an image generation model would start with a random noise image and then, after having been trained to reverse the diffusion process on numerous images, the model would be able to generate new images based on text input prompts. A good example is OpenAI’s text-to-image model DALL-E 2. Other popular examples of text-to-image generative AI models include Stable Diffusion and ControlNet. These models are known as language-vision models or LVMs.
Many of the latest LLMs such as Llama 2, GPT-4 and BERT use the relatively new neural network architecture called Transformer, which was introduced in 2017 by Google. These complex models are leading to the next wave of generative AI where AI is used to create new content. The research into AI is ongoing and you should expect continual changes in architectures, algorithms and techniques.
AI is being seamlessly integrated into our daily activities, like medical diagnostics, to enhance lives and improve outcomes.

Real-time AI for everyone, everywhere
Over the years there have been several leaps forward in the development of modern AI.
It started with the idea that you could train neural networks with a process called deep learning that employed deeper layers of neurons to store more substantial information and represent more complex functions. Training these neural network models required a lot of computation, but advancements in parallel computing and more sophisticated algorithms have addressed this challenge.
Running neural network training and inference through a DSP, FPGA, GPU, or NPU, made the development and deployment of deep neural networks more practical. The other big breakthrough for large-scale AI was access to large amounts of data through all the cloud services and public data sets.
A complex and nuanced AI model requires lots of generalized data, which can be in the form of text, speech, images and videos. All these data types are fodder for neural network training. Using these vast troves of rich content to train neural networks has made the models smarter and more capable.
Compressing that knowledge into more compact models is allowing them to be shared beyond the cloud and placed into edge devices. The democratization of AI is happening now.
Pat Lawlor
Director, Technical Marketing, Qualcomm Technologies, Inc.
Jerry Chang
Senior Manager, Marketing, Qualcomm Technologies