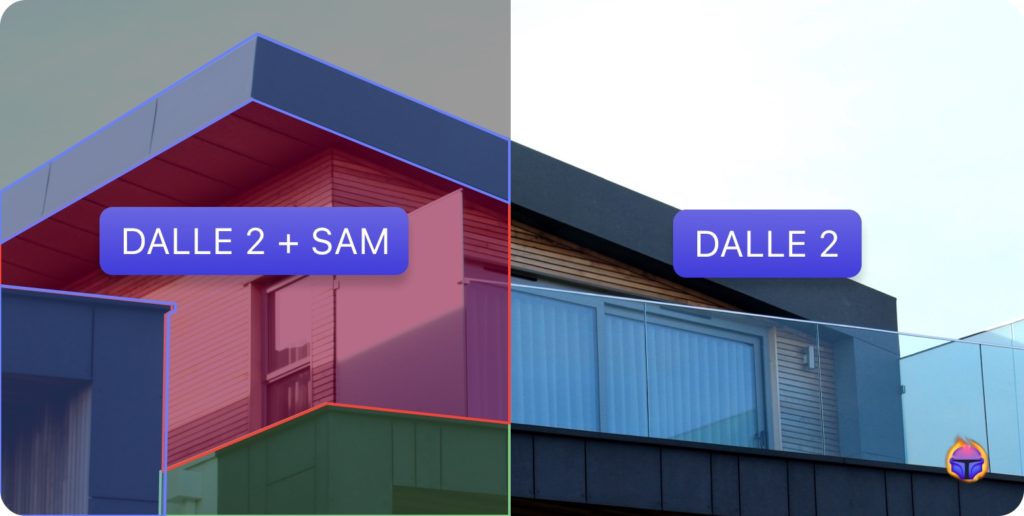
This article was originally published at Tenyks’ website. It is reprinted here with the permission of Tenyks.
Learn about the Foundation Models — for object classification, object detection, and segmentation — that are redefining Computer Vision.
Foundation models have come to computer vision! Initially limited to language tasks, foundation models can now serve as the backbone of computer vision tasks such as image classification, object detection, and image segmentation. Already they have begun to revolutionize industries like autonomous driving, medical imaging, and robotics, letting machines perceive and understand the visual world with unprecedented accuracy.

Table 1. A summary to compare all of the model’s we’ll discuss in detail in the upcoming sections. Hopefully it helps you select the best foundation model for your use case!
Understanding the landscape of foundation models is very important for researchers, practitioners, and enthusiasts in computer vision. With the rapid evolution and proliferation of these models it becomes useful to establish a taxonomy that categorizes and organizes them based on their architecture, capabilities, and underlying principles. This lets us overview the diverse set of foundation models available and build a roadmap for future advancements and research directions.
In this blog post, we delve into the world of foundation models for object classification, detection, and segmentation. We explore the key concepts, techniques, and architectures that form the foundation of these models, empowering them to excel in their respective tasks.
By gaining a deeper understanding of the taxonomy (see Table 1) of foundation models, we can appreciate the nuances and trade-offs inherent in their design and make informed decisions when selecting the most suitable model for a given application.
What is a Foundation Model?

Figure 1. A diagram illustrating the concept of a foundation model — Adapted from NVIDIA
A foundation model is a pre-trained deep neural network that forms the backbone for various downstream tasks such as object classification, object detection, and image segmentation (see Figure 1). The concept of foundation models comes from building upon a base or ‘foundation’ that’s already been built.
These models are trained on massive, diverse datasets to capture visual features that are universal to many different domains. They can then be used to perform specific tasks without the data needed to train a bespoke model from scratch. This approach leverages neural networks’ powerful representational learning capabilities to generalize well across tasks.
By understanding and selecting the suitable foundation model, we can harness the power of deep learning more effectively and efficiently. In the following sections, we will examine the different foundation models prevalent in computer vision tasks and how they relate.
Embedding Extractors
An important subset of foundation models in computer vision are ‘embedding extractors’. This is a neural network that transforms raw input data, like images, into a more compact and condensed vector representation, commonly referred to as an ‘embedding.’ The ability to extract meaningful features from input data lies at the heart of many successful deep learning models, and it forms an integral part of our taxonomy of foundation models.
Embedding extractors are crucial for transferring knowledge from a pre-trained model to a specific task. During the pre-training phase, the foundation model learns to recognize various patterns and structures in the data that might be useful in many different domains. These could range from simple features like edges and colors to more complex ones like shapes, textures, and object parts in the case of images. We can then ‘transfer’ this knowledge to a specific task by training a model on top of these features or performing vector operations such as a similarity search on the given embeddings.
Some popular embedding extractor methods you may have heard of for computer vision include CLIP, DINOv2 and ImageBind.
CLIP (OpenAI, 2021) [1]
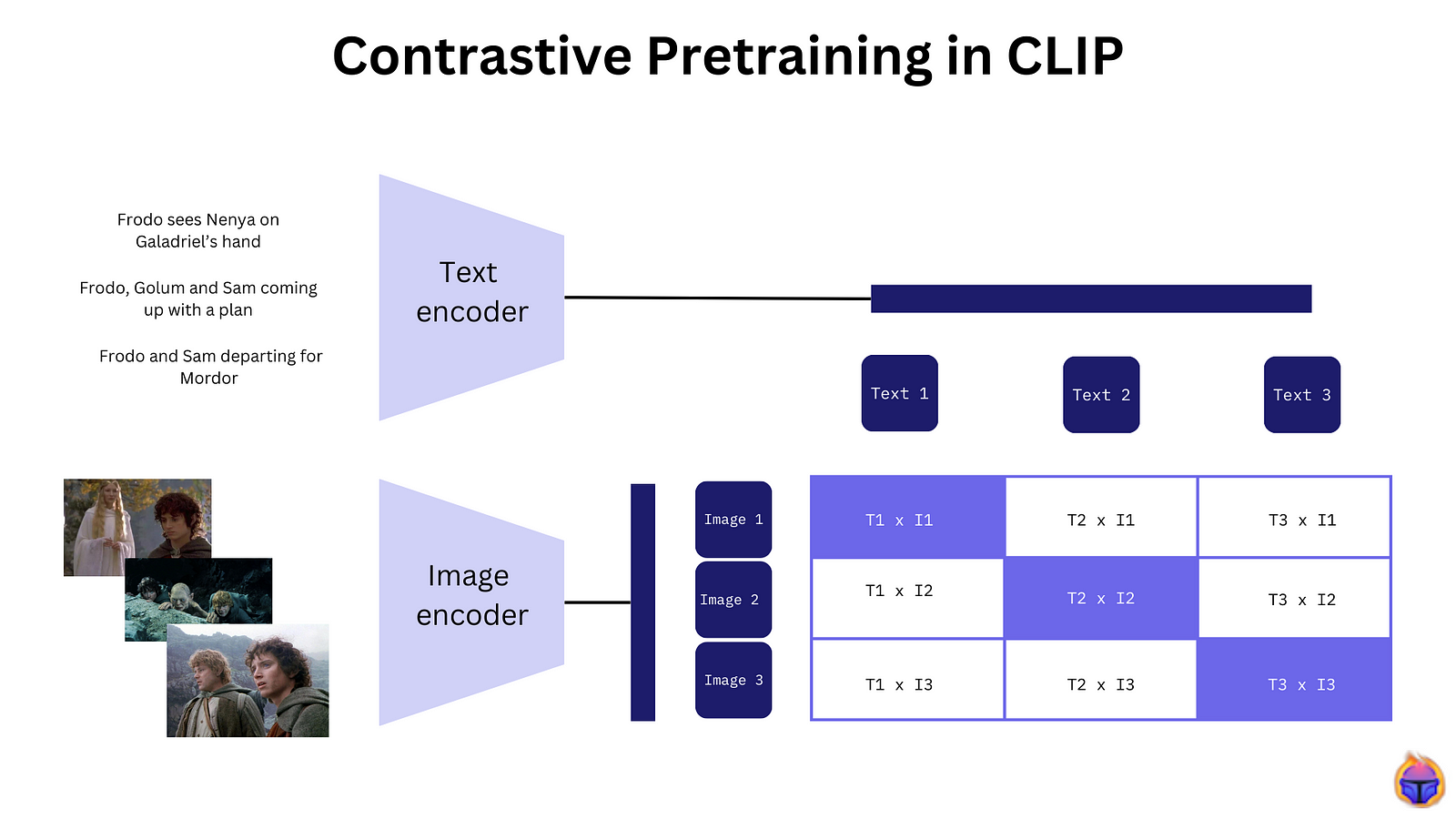
Figure 2. CLIP trains both an image and a text encoder to predict the correct pairings (image, text)
- Inputs: Images and Text.
- Outputs: The output of CLIP is a dense vector representation (or embedding) for both the input image and text that preserves semantic similarity. Similar images and corresponding textual descriptions are mapped closely in the embedding space and vice versa.
- What is it: CLIP, short for Contrastive Language-Image Pre-training, is a series of multimodal image and text encoders introduced by OpenAI. CLIP understands and interprets images in the context of natural language, enabling it to perform a diverse range of tasks that span both the image and text domains. As is typical for encoders in this section, the larger encoders often capture more detailed semantic information in the resulting embeddings.
- License: Open-Source (MIT).
- Bonus: Align (Google Research, 2021) [2] and OpenCLIP (LAION, 2022) [3], which are similar multimodal image and text encoders that claim better performance to CLIP under some circumstances.
DINOv2 (Meta AI, 2023) [4]

Figure 3. DINOv2 augments the original dataset via a self-supervised retrieval system
- Inputs: Images.
- Outputs: The output of DINOv2 is a dense semantic vector representation for the input image.
- What is it: DINOv2 is a series of image encoders introduced by Meta AI. Unlike CLIP, DINOv2 focuses on the vision domain with a novel self-supervised training setup designed to maximize performance on downstream vision tasks.
- License: Non-Commercial (CC-BY-NC 4.0 license).
- Bonus: The original DINO (Meta AI, 2021) [5].
ImageBind (Meta AI, 2023) [6]

Figure 4. ImageBind’s embedding space allows for multi-modal capabilities
- Inputs: Images, Text, Audio, Depth Maps, Thermal Image Maps, and Inertial Measurement Units.
- Outputs: The output of ImageBind is a dense semantic vector representation.
- What is it: ImageBind is a multimodal encoder introduced by Meta AI that expands on existing image and text encoders with support for additional mediums. Counter-intuitively, Meta AI finds that training on these other mediums improves image and text encoding support.
- License: Non-Commercial (CC-BY-NC 4.0 license).
Zero-Shot Models

Figure 5. Segment Anything Model applied to an image of a dog — Image Credit: Alana Jones-Mann
While embedding extractors output features that can then be used on a downstream task, zero-shot models are pre-trained neural networks that aim to perform the task directly on unseen data. Zero-shot models can be really useful in scenarios with many object categories and little or no labeled data.
Zero-shot models operate on the idea that even if a model has not seen a specific object during training, it should be able to use its knowledge about other similar objects to identify the new object. In object classification, detection, and segmentation, zero-shot models can recognize or detect objects and their boundaries even if they don’t appear in the training data.
The strength of zero-shot models lies in their flexibility and the ability to handle new categories gracefully. They have to build a semantic understanding of new classes from the underlying features associated with them. As we will see, zero-shot models often take advantage of the embedding extractors seen in the previous section to get this understanding.
Some popular zero-shot models you may have heard of for computer vision include Meta AI’s Segment Anything Model (or SAM) and Google Research’s OWL-ViT.
Segment Anything Model (Meta AI, 2023) [7]

Figure 6. Components of Segment Anything: a foundation model for segmentation
- Inputs: Images and Point Prompts.
- Outputs: Instance Segmentations of Objects at that Point.
- What is it: The Segment Anything Model (SAM) is an artificial intelligence model developed by Meta AI Research. It can segment any object in an image or video with high quality and efficiency. Segmentation separates an object from its background or other objects and creates a mask that outlines its shape and boundaries. SAM can be prompted to find segmentation only at a specific point, and can generalize zero-shot to unfamiliar objects and images without additional training.
- License: Open-Source (Apache 2.0).
OWL-ViT (Google Research, 2022) [8]

Figure 7. OWL-ViT: two stages to enable open-set object detection
- Inputs: Images and a Text Query.
- Outputs: Open-Set Object Detection.
- What is it: OWL-ViT is an open-set object detector. Given an unstructured text query, it will find object bounding boxes matching that query. It can be used to do zero-shot object detection, finding objects belonging to a class even if it has never seen that class before. OWL-ViT is built upon CLIP and generates corresponding embeddings for each retrieved bounding box.
- License: Open-Source (Apache 2.0).
- Bonus: Grounding DINO (Tsinghua University, 2023) [9], a similar open-set object detector built upon DINO embeddings instead.
State-of-the-Art Architectures
We can also dive into the state-of-the-art architectures that have proven their mettle in industrial object classification, detection, and segmentation tasks. These architectures have delivered remarkable performance and pushed the frontiers of computer vision research and applications. Unlike previous sections where we looked at pre-trained models, these architectures require bespoke training on a given task and labeled dataset.
Some popular state-of-the-art architectures you may have heard of for computer vision include YOLO-NAS, Mask2Former, DETR and ConvNeXt.
YOLO-NAS (Deci.ai, 2023) [10]

Figure 8. A comparison of state-of-the-art object detection models — Image Credit: Saboo_Shubham_
- Inputs: Images.
- Outputs: Object Detection.
- What is it: YOLO-NAS stands for “You Only Look Once — Neural Architecture Search” and is a new object detection model that provides state-of-the-art real-time object detection capabilities. YOLO-NAS is an open-sourced YOLO-based architecture found using a neural architecture search to maximize performance.
- License: Open Source (Code), Non-Commercial (Weights).
- Bonus: YoloV8 (Ultralytics, 2023) [15], a similar state-of-the-art YOLO-based architecture.
Mask2Former (Meta AI, 2022) [11]

Figure 9. In Mask2Former a new Transformer decoder with masked attention is used, instead of the standard cross-attention
- Inputs: Images.
- Outputs: Panoptic, Instance, and Semantic Segmentation.
- What is it: Mask2Former is an architecture capable of addressing any image segmentation task (panoptic, instance, or semantic). It is built upon a Meta architecture for mask classification and introduces a new Transformer decoder using masked attention to improve convergence and performance. Lastly, it proposes training improvements that make Mask2Former more efficient and accessible.
- License: Open Source (MIT).
- Bonus: SegFormer (NVIDIA, 2021) [14] a similar Vision Transformer architecture for semantic segmentation.
DETR (Meta AI, 2020) [12]

Figure 10. In DETR, few-shot detection is achieved with a class-agnostic Transformer encoder & decoder that learns to predict objects’ locations as well as their corresponding task encodings
- Inputs: Images.
- Outputs: Object Detection.
- What is it: DETR is a deep learning model that views object detection as a direct set prediction problem. It streamlines the detection pipeline, removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task.
- License: Open Source (Apache 2.0).
ConvNeXt (Meta AI, 2022) [13]

Figure 11. In the ConvNeXt architecture, the encoder processes only the visible pixels, and the decoder reconstructs the image using the encoded pixels and mask tokens
- Inputs: Images.
- Outputs: Classification, Object Detection, and Segmentation.
- What is it: ConvNeXt is a model family that co-designs self-supervised learning techniques and architectural improvements to improve the performance of pure ConvNets on various recognition benchmarks including ImageNet classification, COCO detection, and ADE20K segmentation.
- License: Open Source (MIT).
Case Study: Tenyks
Figure 12. Zero Shot object detection on unlabelled data: crosswalks in different conditions
Imagine exploring a very large dataset comprised of millions of images of cars, trucks, and pedestrians in the autonomous driving domain. Suppose the majority of these images lack labels. How can we efficiently search over these unlabelled data?
At Tenyks, we use foundation models extensively to make visual data more accessible and informative. One way we do this uses OpenAI’s CLIP and Meta AI’s Segment Anything Model (SAM). Our platform uses a powerful combination of these two state-of-the-art foundation models to perform zero-shot object detection on unlabelled data.
Figure 12 shows how searching for “crosswalks in sunny days” returns images that contain crosswalks in daytime conditions, whereas searching for “crosswalks in nighttime” yields images containing nighttime scenes with crosswalks. How can Tenyks do this?
A high-level overview of one of our many workflows follows a two-step process: extracting objects using SAM, then comparing the objects using CLIP embeddings. SAM provides a comprehensive outline of every object, distinguishing between foreground and background and different object categories even in complex and cluttered scenes. We then pass each object through a CLIP encoder to obtain meaningful semantic embeddings of every object in the dataset.
We use text queries to find new objects and other objects as image queries to find new objects in categories of interest. The power of foundation models means this can be done entirely without manual annotations — with all the heavy lifting done automatically by the Tenyks platform.
Conclusion

Figure 13. An object detection meme — Image Credit: @BehnazEl
In computer vision’s vast and rapidly evolving landscape, foundation models have etched an indelible mark. Significant strides have been in object classification, detection, and segmentation due to foundation models, paving the way for advanced applications in many industries.
As we look towards the future, understanding the taxonomy of foundation models becomes not just a luxury but a necessity for anyone interested in computer vision. With the rapid pace of research in AI the landscape of foundation models will continue to evolve and diversify. Understanding the core principles, strengths, and weaknesses of these models lets us navigate this landscape and put this technology to its full potential.
This taxonomy of foundation models is a map to navigate the future of vision-based AI. As we continue to explore and refine this map, one thing is sure: the best is yet to come.
References
[1] CLIP
[2] ALIGN
[3] OpenCLIP
[4] DinoV2
[5] Dino
[6] ImageBind
[7] Segment Anything
[8] OWL-ViT
[9] Grounding DINO
[10] Yolo-NAS
[11] Mask2Former
[12] DETR
[13] ConvNeXt
[14] SegFormer
[15] YoloV8
Authors: Shea Cardozo, Dmitry Kazhdan, Jose Gabriel Islas Montero.