
This blog post was originally published at Ceva’s website. It is reprinted here with the permission of Ceva.
Not so long ago, AI inference at the edge was a novelty easily supported by a single NPU IP accelerator embedded in the edge device. Expectations have accelerated rapidly since then. Now we want embedded AI inference to handle multiple cameras, complex scene segmentation, voice recognition with intelligent noise suppression, fusion between multiple sensors, and now very large and complex generative AI models. Such applications can deliver acceptable throughput for edge products only when run on multi-core AI processors. NPU IP accelerators are already available to meet this need, extending to 8 or more parallel cores and able to handle multiple inference tasks in parallel. But how should you partition expected AI inference workloads for your product to take maximum advantage of all that horsepower? That’s the subject of this article.
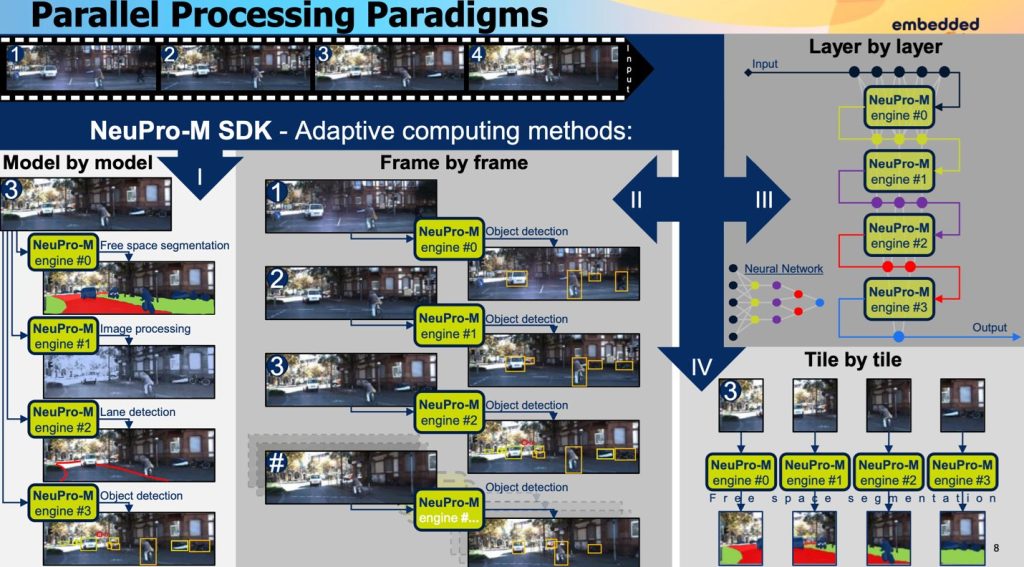
Six paths to exploit parallelism for AI inference
As in any parallelism problem, we start with a defined set of resources for our AI inference objective: some number of available accelerators with local L1 cache, shared L2 cache and a DDR interface, each with defined buffer sizes. The task is then to map the network graphs required by the application to that structure, optimizing between total throughput and resource utilization.
One obvious strategy is in processing large input images which must be split into multiple tiles – partitioning by input map where each engine is allocated a tile. Here, multiple engines search the input map in parallel looking for the same feature. Conversely you can partition by output map – the same tile is fed into multiple engines in parallel, and you use the same model but different weights to detect different features in the input image at the same time.
Parallelism within a neural net is commonly seen in subgraphs, as in the example below. Resource allocation will typically optimize breadth wise then depth wise, each time optimizing to the current step. Obviously that approach won’t necessarily find a global optimum on one pass, so the algorithm must allow for backtracking to explore improvements. In this example, 3 engines can deliver >230% of the performance that would be possible if only one engine were available.
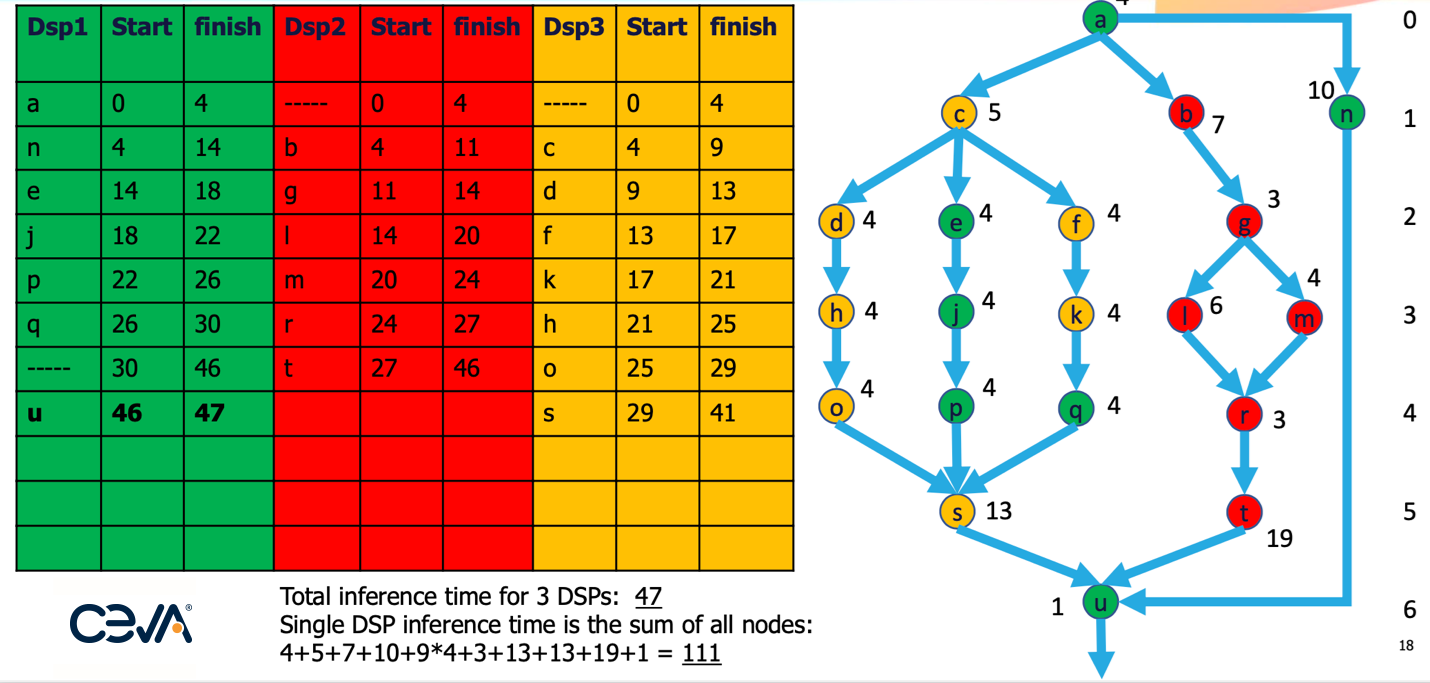
While some AI inference models or sub-graphs may exhibit significant parallelism as in the graph above, others may display long threads of operations, which may not seem very parallelizable. However, they can still be pipelined, which can be beneficial when considering streaming operations through the network. One example is in layer-by-layer processing in a DNN. Simply organizing layer operations per image to minimize context switches per engine can boost throughput, while allowing following pipeline operations to switch in later but still sooner than in purely sequential processing. Another good example is provided by transformer-based generative AI networks where alternation between attention and normalization steps allows for sequential recognition tasks to be pipelined.
Batch partitioning is another method, providing support for the same AI inference model running on multiple engines, each fed by a separate sensor. This might support multiple image sensors for a surveillance device. And finally, you can partition by having different engines run different models. This strategy is useful especially in sematic segmentation, say for autonomous driving where some engines might detect lane markings, others might handle free (drivable) space segmentation, and others might detect objects (pedestrians, other cars, etc).
Planning
There are plenty of options to optimize throughput and utilization but how do you decide how best to tune for your AI inference application needs? This architecture planning step must necessarily come before model compile and optimization. Here you want to explore tradeoffs between partitioning strategies. For example, a subgraph with parallelism followed by a thread of operations might sometimes be best served simply by pipelining rather than a combination of parallelism and pipelining. Best options in each case will depend on the graph, buffer sizes, and latencies in context switching; support for experimentation is critical to determining optimal implementations.
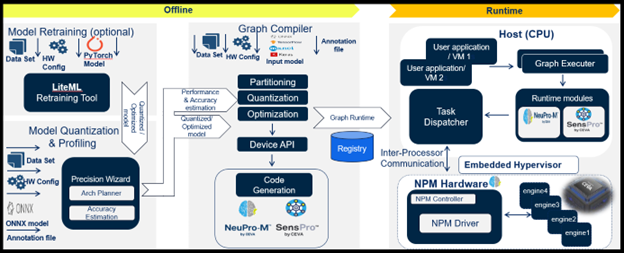
If you have been wrestling with how to best optimize your AI workload across a multicore NPU AI inference subsystem, checkout our NeuPro-M platform and give us a call to exchange ideas on parallelism for challenging AI inference workloads at the edge.
Rami Drucker
Machine Learning Software Architect, Vision Business Unit, Ceva