This blog post was originally published at Nota AI’s website. It is reprinted here with the permission of Nota AI.
-
Delivers real-time AI performance on edge devices such as smartphones, IoT devices, and embedded systems.
-
Introduces a novel “Reuse Attention” technique that minimizes redundant computations in Multi-Head Attention.
-
Achieves competitive accuracy and significant inference speed improvements on benchmarks like ImageNet-1K.
Transformer-based architectures have demonstrated remarkable success across various domains but remain challenging to deploy on edge devices due to high memory and computational demands. In this paper, we propose UniForm (Unified TransFormer), a novel framework that unifies multi-head attention computations into a shared attention mechanism—Reuse Attention—to enhance efficiency without compromising accuracy. By consolidating redundant operations into a unified representation, UniForm effectively reduces memory overhead and computational complexity, enabling seamless deployment in resource-constrained environments.
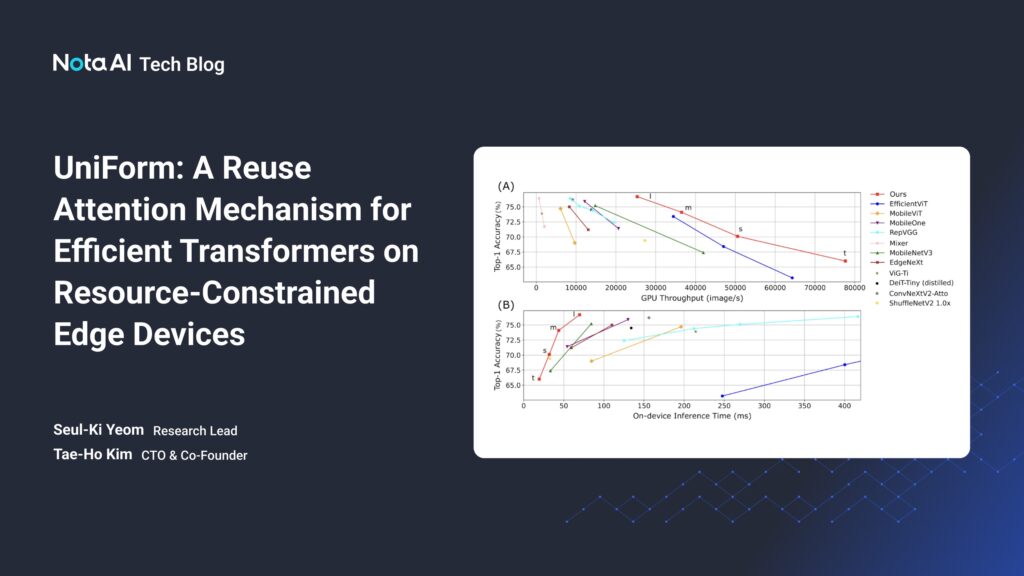
Experiments on ImageNet-1K and downstream tasks show that UniForm achieves state-of-the-art accuracy while improving inference speed and memory efficiency. Notably, UniForm-l attains 76.7% Top-1 accuracy on ImageNet-1K with a 21.8ms inference time on Jetson AGX Orin, achieving up to a 5x speedup over competing benchmarks. These results highlight UniForm’s versatility across GPUs and edge platforms, demonstrating its potential for real-time AI applications in low-resource settings.
Code available at https://github.com/seulkiyeom/mixtransform.
Significance/Importance of the Paper
As AI applications increasingly demand on-device processing—ranging from real-time video analysis and autonomous navigation to smart home automation—there is a growing need for models that can run efficiently on limited hardware.
By dramatically reducing computational redundancy and memory overhead, UniForm makes it feasible to deploy state-of-the-art Transformer models on edge devices. This not only broadens the potential applications of advanced AI but also enhances energy efficiency and reduces operational costs, democratizing access to powerful AI solutions.
Summary of Methodology
The innovative heart of UniForm is its “Reuse Attention” mechanism. Traditional MHA calculates separate attention matrices for each head—a process that is both time-consuming and memory intensive. In contrast, UniForm computes a single shared attention matrix. This matrix, which captures the relative importance of input tokens, is then used by all attention heads, eliminating redundant calculations. This design not only streamlines the computation process but also lowers the memory footprint significantly.

To further enhance efficiency, UniForm applies a multi-scale strategy when processing value projections. By incorporating depthwise convolutions with multiple kernel sizes, the model is able to capture local and global contextual information simultaneously without incurring additional computational cost.
Experimental Results
UniForm was rigorously evaluated on the ImageNet-1K benchmark and across various edge devices. The experimental results demonstrated that the UniForm-l variant achieves up to 76.7% Top-1 accuracy while delivering impressive inference speeds—for example, an inference time of 21.8 milliseconds on the Jetson AGX Orin platform, which is up to 5× faster than competing models.
These results underline the effectiveness of the UniForm architecture in bridging the gap between high-performance server-grade hardware and resource-limited edge devices, making real-time AI applications viable in a wide range of settings.

Conclusion
UniForm represents a significant advance in the design of efficient Transformer architectures. By introducing the “Reuse Attention” mechanism, the model eliminates redundant attention computations and reduces memory usage—key factors that enable high-speed, real-time AI inference on edge devices.
This breakthrough not only enhances the practical deployment of AI models in environments with limited resources but also paves the way for future innovations in model efficiency and energy-saving AI solutions.
If you have any further inquiries about this research, please feel free to reach out to us at the following email address: [email protected].
Furthermore, if you have an interest in AI optimization technologies, you can visit our website at netspresso.ai.
Seul-Ki Yeom, Ph. D.
Research Lead, Nota AI GmbH
Tae-Ho Kim
CTO & Co-Founder, Nota AI