Nota AI Demonstration of LLM Acceleration on Mobilint NPU, Optimized with NetsPresso
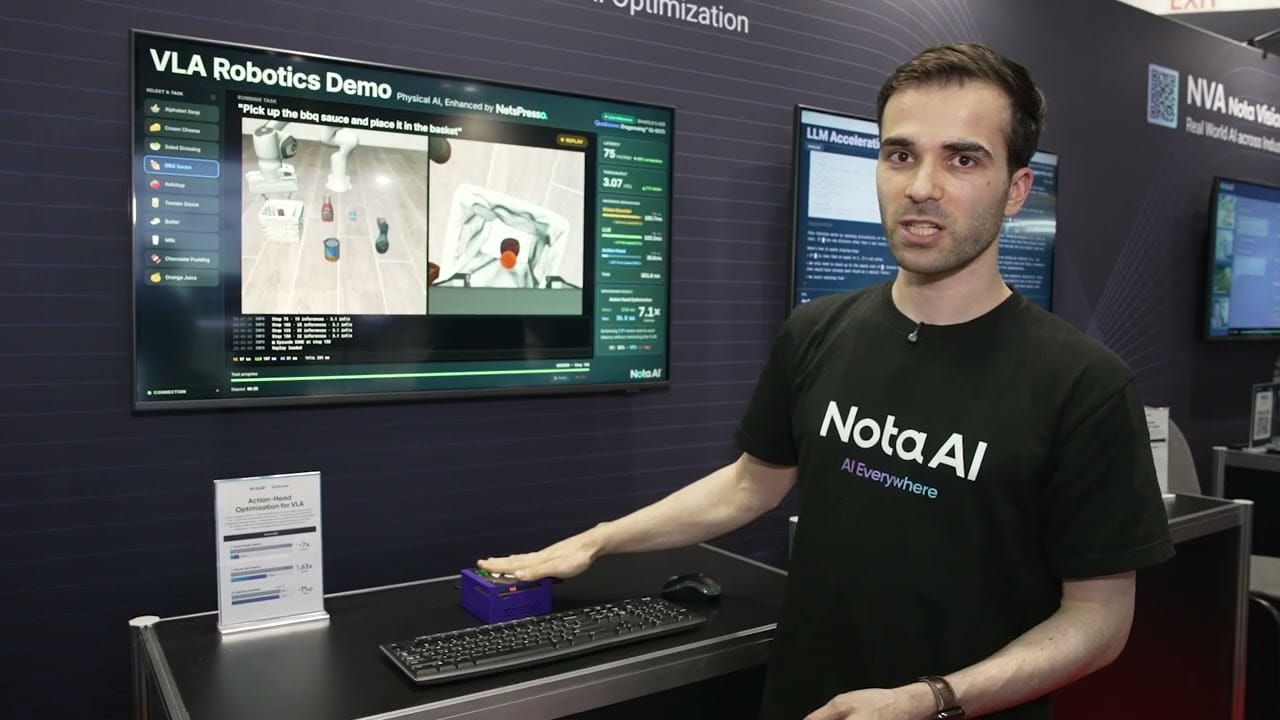
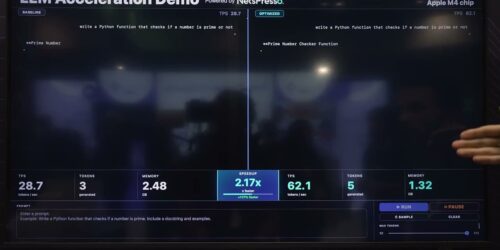
Thibault Castells, Research Engineer at Nota AI, demonstrates the company’s latest edge AI technologies at the 2026 Embedded Vision Summit. Specifically, he demonstrates Qwen3-4B running as a real-time LLM Coding Assistant entirely on Mobilint MLA100 NPU, optimized with NetsPresso. Achieving 179–478ms Time to First Token and 8.5–10.8 tokens per second, the demo proves that high-performance […]
Nota AI Demonstration of LLM Acceleration on Mobilint NPU, Optimized with NetsPresso Read More +