This blog post was originally published in expanded form at RapidFire AI’s website. It is reprinted here with the permission of RapidFire AI.
When people talk about deep learning, they usually talk about the inner loop—the elegant dance of forward passes, backpropagation, and gradient descent. This is the part that’s been endlessly refined over the years, from improved optimizers to better loss functions. But if you’ve ever built models in the real world, you know that the most critical decisions—the ones that actually determine success—don’t happen inside the training loop.
They happen before and around it. This is the outer loop.
At RapidFire AI, we believe the outer loop is the most important and least optimized layer of the modern ML stack. It governs the choices that define whether a model converges quickly or not at all, whether it delivers marginal improvements or breakthrough results. And yet, it’s still mostly held together by Jupyter notebooks, ad-hoc scripts, and wishful thinking.
Let’s unpack what it is, why it matters, and how we’re changing the game.
The Outer Loop, Defined
The inner loop is what happens during training: a model makes predictions, compares them to the truth, and updates its weights. But the outer loop is the set of decisions that shape what gets trained and how. Which model architecture should you use? What learning rate, batch size, or prompt format? Which data augmentations? What metric best captures success in your use case?
This is experimentation, orchestration, iteration—and it’s what determines how quickly you move from concept to high-performing solution.
Maybe “training deep neural networks” for clarity.
Maybe it’s because of the 2M people in our investors deeplearning.AI network but we think deep learning is the broader term. Do you think we should change this to talk about computer vision as an example or leave it as is?
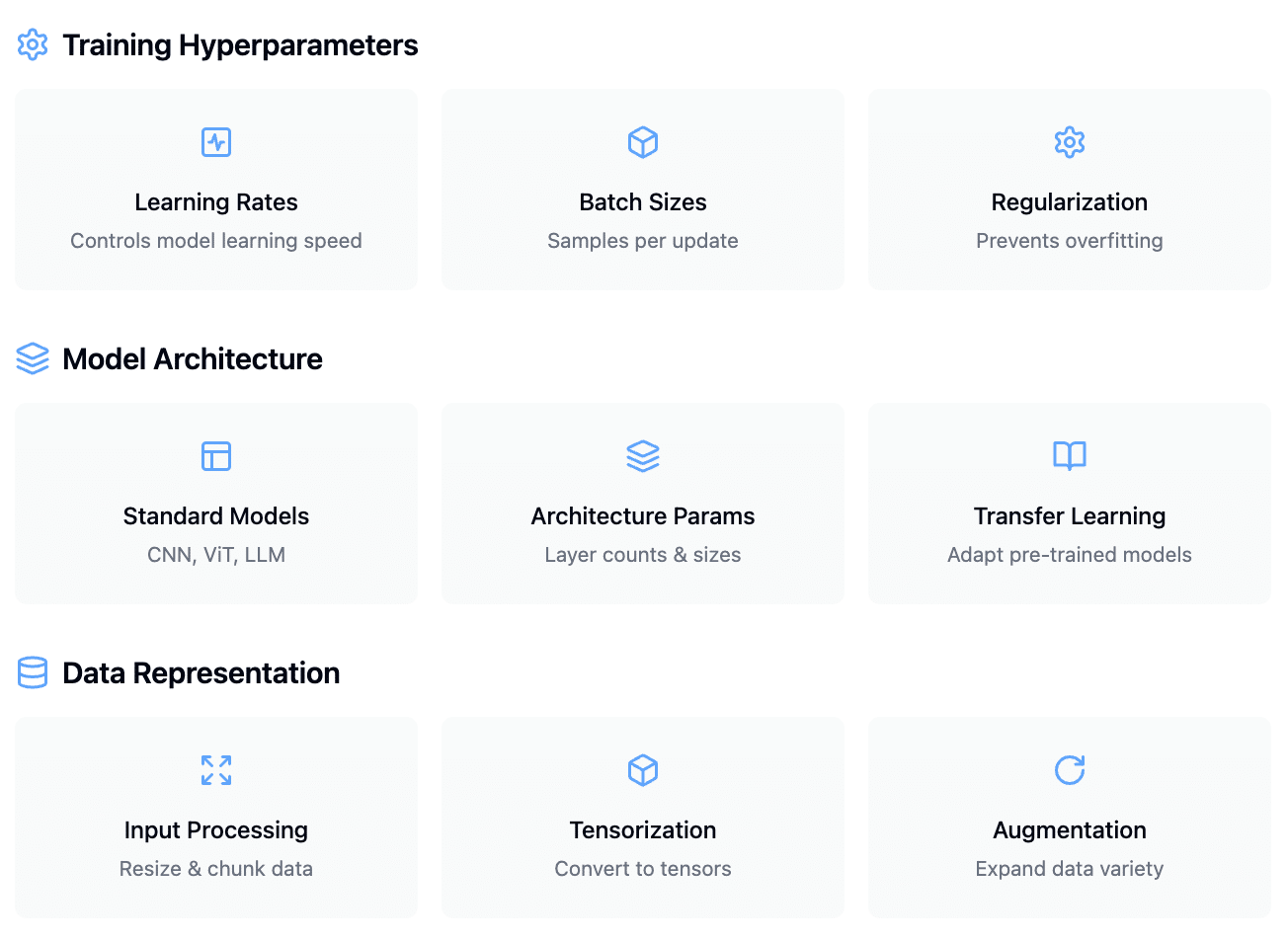 Fig 1. Deep learning accuracy depends critically on three classes of experimental choices, each requiring careful exploration and tuning if one wants to maximize accuracy for their use case
Fig 1. Deep learning accuracy depends critically on three classes of experimental choices, each requiring careful exploration and tuning if one wants to maximize accuracy for their use case
Why It’s So Crucial Now
As deep learning scales, the cost of choosing the wrong configuration grows. You can waste thousands in GPU time training a model that was doomed from the start because of a poor hyperparameter choice or a bad data slice. Worse, you might never realize a better solution was just a few iterations away.
In research and in production, the outer loop is how real progress happens. When teams make meaningful gains, it’s often because they explored a different architecture, introduced a new regularization technique, or fine-tuned on more-relevant data. These aren’t inner-loop tweaks. They’re outer-loop decisions.
And in today’s world—where AI agents are learning continuously, where LLMs are being rapidly customized, and where costs are under scrutiny—nailing the outer loop isn’t just a nice-to-have. It’s how you stay competitive.
What’s Broken—and How We Fix It
The irony is that the most impactful part of the ML process is also the most neglected. Experimentation is slow, messy, and hard to track. Engineers repeat the same runs with tiny variations, often without knowing what worked or why. Infrastructure gets wasted on low-yield training jobs. There’s no easy way to orchestrate or visualize the space of possibilities.
Thorough experimentation in accuracy-critical applications can lead to an overwhelming number of configurations. Consider the following (simplified) config space for a medical imaging example:
configurations = [
{
"architecture": "ViT-base-patch16-224",
"batch_size": 32,
"optimizer": "Adam",
"learning_rate": 1e-3,
"augmentation": "standard"
},
{
"architecture": "Resnet50",
"batch_size": 64,
"learning_rate": 1e-4,
"optimizer": "AdamW",
"augmentation": "aggressive"
},
# ... many more configurations
]With just 8 hyperparameter combinations, 2 model architectures, and 2 data preprocessing strategies, we have 32 different configs. At, say, 24 hours per training run, that adds up to almost a month sequentially!
Alternatively, the team could pay for a lot more resources to increase the number of configs that can be run, but this often comes at prohibitively large costs.
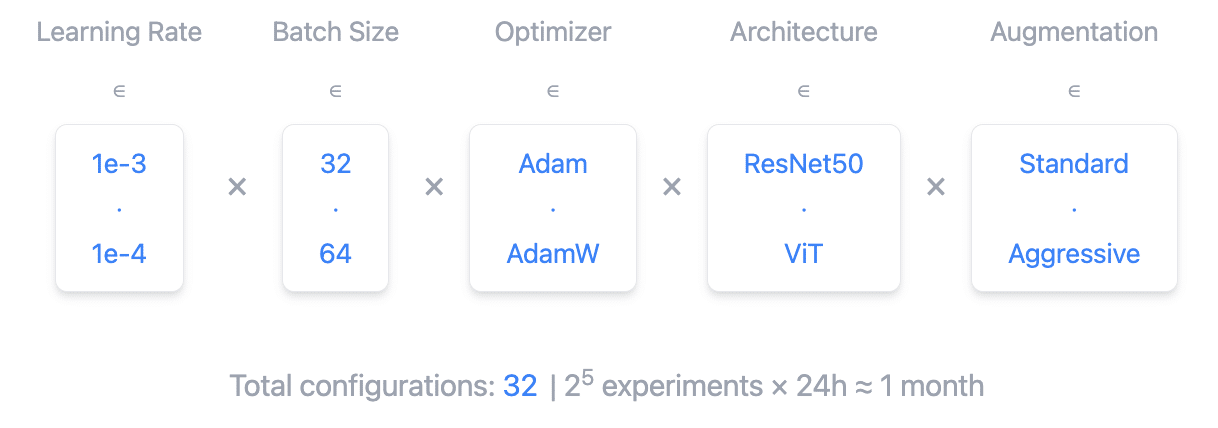 Fig 2. Exploration across the search space to improve accuracy can require significant time and resources. RapidFire AI accelerates this process by intelligently managing the process, making real-time adjustments, and reallocating resources so you reach the best models faster with less compute.
Fig 2. Exploration across the search space to improve accuracy can require significant time and resources. RapidFire AI accelerates this process by intelligently managing the process, making real-time adjustments, and reallocating resources so you reach the best models faster with less compute.
That’s why we built RapidFire AI
RapidFire gives teams a way to explore, control, and optimize the outer loop like never before. With our platform, you can launch hundreds of experiments in parallel on the same cluster, make real-time adjustments to running jobs, and systematically zero in on what actually works. Whether you’re fine-tuning or training a vision model, or testing reinforcement learning policies, RapidFire helps you move faster—with fewer dead ends and dramatically lower GPU costs.
This Is the Future of Productive AI
If your models are underperforming—or if you’re spending too much time and money getting to good results—chances are the problem isn’t your optimizer or model weights. It’s your outer loop.
By investing in this overlooked layer, you can unlock more performance, more insight, and more progress. That’s what RapidFire is here to deliver.
Try RapidFire AI free today, and see what happens when your experimentation loop moves at the speed of your ideas.
Jack Norris
CEO and Co-Founder, RapidFire AI