
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
Key takeaways: We talk about five techniques—compiling to machine code, quantization, weight pruning, domain-specific fine-tuning, and training small models with larger models—that can be used to improve on-device AI model performance.
Whether you think edge AI is cutting edge or rough around the edges (or both!), Edge AI is creating new opportunities for developers. Hardware is getting more powerful—with speed, processing power, and battery life that dramatically expand the kind of projects that are possible on a device. The IoT market is growing fast and wide, with analysts forecasting hundreds of billions of dollars of market growth,1 including expansion in sectors like healthcare, manufacturing, energy, logistics, and smart cities.2
With this rapid expansion, savvy developers have a unique opportunity to establish themselves as thought leaders and shape the future of edge AI.
Getting your head out of the cloud
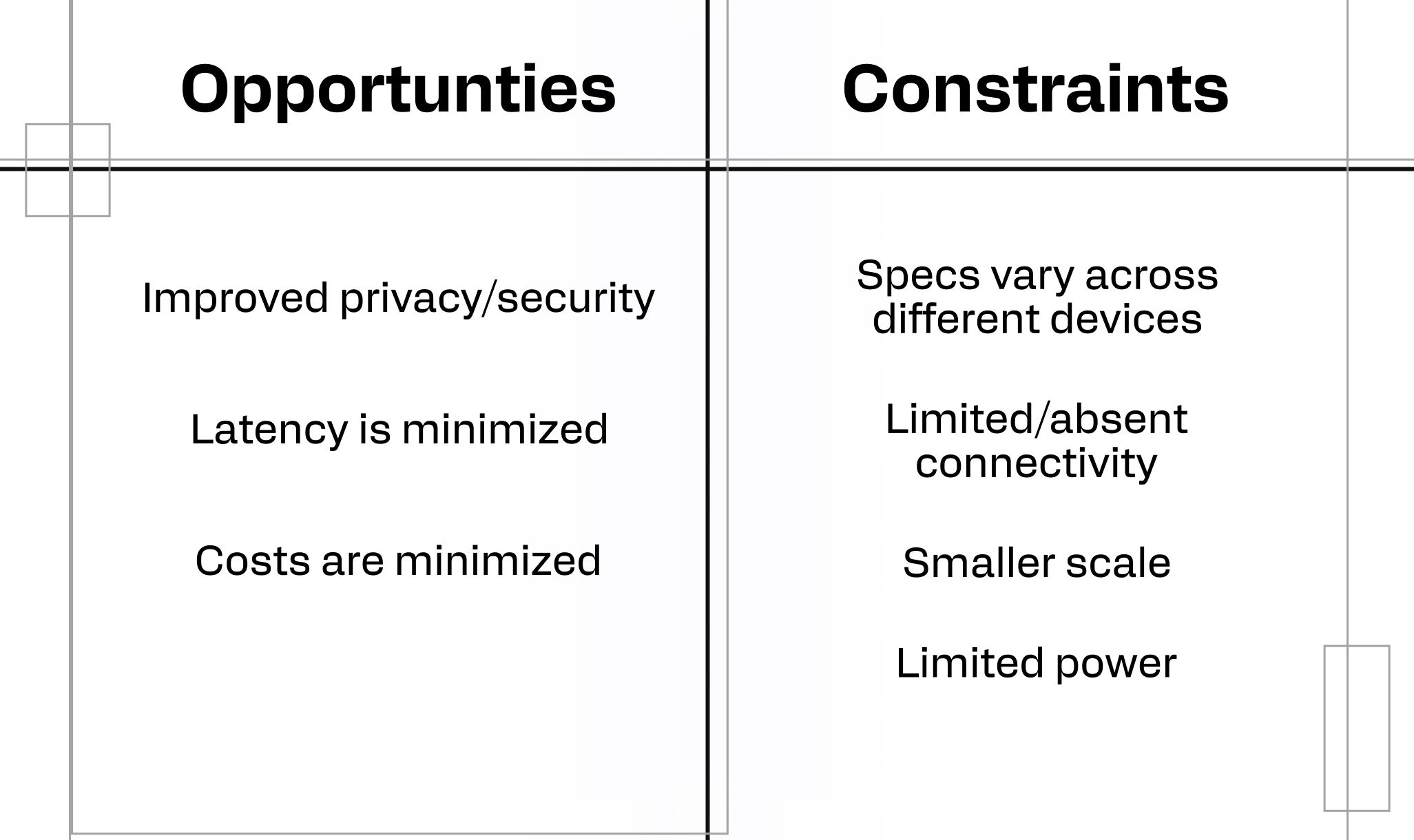
Effective edge AI development depends on working within the specifications and capabilities of the hardware. That means choosing an AI model that can complete the desired task and ensuring that the chosen model has been optimized for the hardware on which it is deployed.
In many ways, building AI applications for the edge requires developers to revisit principles from the pre-cloud era. Many of the same best practices apply:
- Building small, reusable code elements
- Thoughtful resource allocation, garbage collection, minimizing external dependencies, and other similar practices
- Working with connectivity constraints using local storage and processing, data compression, and other techniques
Making it happen: techniques for optimizing your AI model for the edge
Here are a few optimization techniques that you can use to improve AI model performance at the edge:
- Fine-tune a model or a subset of its layers to increase performance in a specific domain. This can help maintain domain-specific accuracy even in a resource-constrained environment. Consider the following steps:
- Ensure you have the right training dataset—choosing a high-quality, relevant data set of sufficient size is important in all kinds of training scenarios; training a subset of your layers for domain-specific training is no exception.
- Adjust your model’s architecture if necessary—freezing, adding, or otherwise modifying layers can make it easier to preserve general features while allowing domain-specific training.
- Choose the right fine-tuning technique and training parameters—take steps to avoid catastrophic forgetting. Consider reducing the learning rate, working in smaller batches, or stopping after fewer epochs to achieve the desired goal.
- Evaluate and optimize as needed—check your work! Test model benchmarks to see whether domain training improved efficiency. Check for general and domain-specific accuracy.
- Compile an inference model to machine code to increase performance. This technique helps by tuning your model’s hardware-specific capabilities, reducing runtime overhead, and maximizing resource efficiency. The EON compiler included in Edge Impulse is a powerful option, but some developers prefer a more hands-on approach. To do this, follow these steps:
- Export your model to a framework-agnostic format—PyTorch TorchScript, ONNX, and TensorFlow SavedModel are all good options. Consider visiting the Qualcomm AI Hub to learn more.
- Use an ML compiler or optimizer to transform the architecture into hardware-optimized code—you may already have worked with XLA or Glow, or use the compiler available on the Qualcomm AI Hub.
- Integrate with native code post-processing—once you’ve compiled your model, you can embed it into an application using your library of choice (e.g., TensorFlow Lite or ONNX Runtime).
- Quantization. This technique helps because it works to address hardware constraints in memory, power, and compute units. To quantize your model, follow the steps below:
- Select the right quantization ops—it helps to focus on computationally expensive operators here.
- Choose an appropriate quantization method to maintain the necessary level of accuracy—dynamic quantization, static quantization, or quantization-aware training may all be good choices depending on your project.
- Validate your model after quantization—check your model size and run inference tests to make sure your model is still performing as expected. AIMET is a good resource here. You can also try QuantSim to confirm accuracy and latency.
- Prune weights that do not significantly impact performance. This will help you maintain accuracy and performance in a resource-constrained environment. Follow these steps to prune your model:
- Select a pruning strategy—remember to consider the accuracy impact of whatever strategy you choose. Gradient-based and iterative pruning might be more computationally intensive, but they will also do a better job of ensuring that your model maintains accuracy following pruning.
- Analyze weight distributions—remember that distributions may be different across layers, requiring different approaches to pruning.
- Set pruning thresholds—adaptive and validation-driven pruning approaches may be most effective in cases where maintaining accuracy is important.
- Apply pruning and evaluate model performance—check sparsity, accuracy, and inference speed to ensure that your efforts produced the desired result.
- Use large models to distill knowledge and teach small models about scoped domains. This will help avoid overparameterization while still allowing you the smaller size, faster inference, and improved energy efficiency afforded by a smaller model. (However, note that it’s still important to consider the device constraints when choosing your model.)
- Ensure compatibility between teacher and student models—consider matching architecture, capacity, and output formats to reduce feature misalignment and other disruptions.
- Curate a domain-specific training data set—ensure that your training data adheres to any relevant regulations. Use balanced sampling methods and don’t shy away from including edge cases!
- Extract teacher knowledge—consider feature alignment between the student and teacher, and choose the distillation method that makes sense for the specific type of knowledge transfer you’re trying to achieve.
- Train the student—use a lower training rate than the teacher’s original training rate, and work with larger batches to help stabilize feature transfer.
- Evaluate performance—as before, combine performance benchmarks and accuracy metrics to ensure the model will be performant at the edge without sacrificing output quality.
Developers have a unique opportunity to define the future of edge AI by bringing novel use cases on-device. If you want to be part of this effort, you can get yourself into an edge-friendly mindset by returning to classic, hardware-aware coding principles that help you optimize your code for the edge. When deploying AI at the edge, compiling to machine code, quantization, pruning, fine-tuning to a necessary domain, and using large models to teach small models can help with optimization. Of course, this list of optimization techniques isn’t exhaustive! Have you had success with other optimization techniques?
Have a suggestion that improves on one of the techniques discussed here? We want to know!
Join us on Discord to talk about your experiments with optimizing AI for edge deployment.
FAQ
Q: How does AIMET assist in model optimization?
A: AIMET provides advanced quantization and compression techniques for trained neural network models, enabling them to run more efficiently on edge devices.
Q: Can I deploy models optimized with these techniques on any device?
A: While these optimization techniques enhance model efficiency, deployment compatibility depends on the specific hardware and software configurations of the target device.
Q: What’s the best way to handle post-quantization calibration on non-representative datasets?
A: If a representative dataset isn’t available, consider using synthetic data generation or leveraging transfer learning to simulate realistic activation ranges. Quantization-aware training (QAT) is another solution, as it adapts to quantization effects during model training itself.