
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
Dive in to learn how we achieve a 1.4x latency decrease on Qualcomm Cloud AI 100 Ultra accelerators by applying an innovative DeepCache technique to text-to-image generation. What’s more, the throughput can be further improved by 3x by combining DeepCache with a novel MultiDevice Scheduling technique. Read on!
Stable Diffusion XL (SDXL) is a text-to-image workload, which takes positive and negative text prompts as input and generates a 1024×1024 image corresponding to the prompts as output. Since 2024, this workload has been included in the industry-leading MLPerf Inference benchmark (sometimes called “The Olympics of ML benchmarking”).
The overall computation pipeline for SDXL consists of four components: text encoder, text encoder 2, UNet, and VAE decoder. UNet is the most computationally intensive part (90-95% of execution time), requiring separate processing of positive and negative prompts, and performing 20 iterations.
MultiDevice Scheduling
In our original implementation, each of the four components is compiled into a separate binary by the Qualcomm Cloud AI 100 SDK. The binaries are loaded onto a device before execution. Using a mechanism called model switching, the implementation switches between the component binaries when processing a single input sample. The switching is relatively fast (only 100-200 ms), but it does add overhead to the pipeline.
The impact of this switching overhead becomes particularly apparent when comparing the SingleStream and Offline scenarios of MLPerf Inference. In the SingleStream scenario, the system processes one sample at a time, requiring model switching between the components of a single request and between multiple requests. In the Offline scenario, the system processes a large batch of samples (e.g. 5,000 prompts), providing an opportunity to reduce the need for frequent model switching and enabling more efficient processing.
We have further found that computational efficiency can be improved by compiling to use 4 cores and running 4 parallel activations (instances) resulting in a 50% throughput boost for UNet.
To overcome these challenges, we have developed an advanced scheduling technique where the computation is distributed between several accelerator devices in the system. We dedicate a small number of “master” devices to text encoding and VAE decoding, and a larger number of “worker” devices to UNet. This simple adjustment has no effect on the output, but unlocks substantial performance improvements.
Let’s break this down with some numbers. On a Pro card, UNet processing takes 20 times longer than VAE decoding. Given this disparity, we found that in a system equipped with 8 Pro cards (8 devices), a 1:7 ratio of master to worker nodes yields optimal results. That is, one master node handles text encoding and VAE decoding, while seven worker nodes focus on parallel UNet execution. This configuration minimises switching overhead while maximizing computational efficiency.
The same principle applies to systems equipped with Ultra cards, where UNet processing takes 26 times longer than VAE decoding. On systems with 2 Ultra cards (8 devices), the same 1:7 ratio of master to worker nodes proves to be most effective. On systems with 4 or more Ultra cards, a 1:13 ratio proves to be most effective.
By tailoring our pipeline scheduling to the specific characteristics of each system, we are able to extract maximum performance across different hardware configurations.
DeepCache
In a separate effort to optimise SingleStream latency, we explore DeepCache [1], a recent training-free technique that accelerates diffusion models by leveraging the temporal redundancy in the sequential denoising process. DeepCache capitalises on the high degree of similarity observed in high-level features between adjacent denoising steps. By caching these slowly-changing features and reusing them across steps, DeepCache eliminates redundant calculations. We have found that using one Deep iteration followed by two Shallow iterations allows us still to meet the MLPerf Inference accuracy constraints for the Closed division.
Results
For evaluation, we use GIGABYTE R282-Z93 servers equipped with 2 Ultra cards and 8 Pro cards with SDK v1.18.2.0, the same servers as was used for the official MLPerf Inference v4.0 submissions with SDK v1.12.2.0.
Offline
| Milestone | Samples per second | Speedup |
| Baseline | 0.356 | 1.00 |
| MultiDevice | 0.533 | 1.50 |
| DeepCache | 0.830 | 2.33 |
| MultiDevice + DeepCache | 1.077 | 3.03 |
Table 1: SDXL Offline on 2x Qualcomm Cloud AI 100 Ultra cards (8 devices).
| Milestone | Samples per second | Speedup |
| Baseline | 0.608 | 1.00 |
| MultiDevice | 0.827 | 1.36 |
| DeepCache | 1.195 | 1.97 |
| MultiDevice + DeepCache | N/A | N/A |
Table 2: SDXL Offline on 8x Qualcomm Cloud AI 100 Pro cards (8 devices).
SingleStream
| Milestone | Milliseconds per sample | Speedup |
| Baseline | 11,669 | 1.00 |
| DeepCache | 8,335 | 1.40 |
Table 3: SDXL SingleStream on 1x Qualcomm Cloud AI 100 Ultra card (2 devices).
| Milestone | Milliseconds per sample | Speedup |
| Baseline | 7,429 | 1.00 |
| DeepCache | 4,633 | 1.60 |
Table 4: SDXL SingleStream on 2x Qualcomm Cloud AI 100 Pro card (2 devices).
Visualization Tool
To truly understand and optimize our system, we developed an interactive visualization tool. This web-based demo provides real-time insights into node utilisation, task distribution, and performance metrics across the system equipped with Qualcomm Cloud AI 100 accelerators. Users can scrub through the execution timeline, observe task distribution across nodes, and dive deep into performance charts for individual accelerators. This tool not only showcases the efficiency of our distributed architecture but also serves as an invaluable aid for further optimization and debugging.
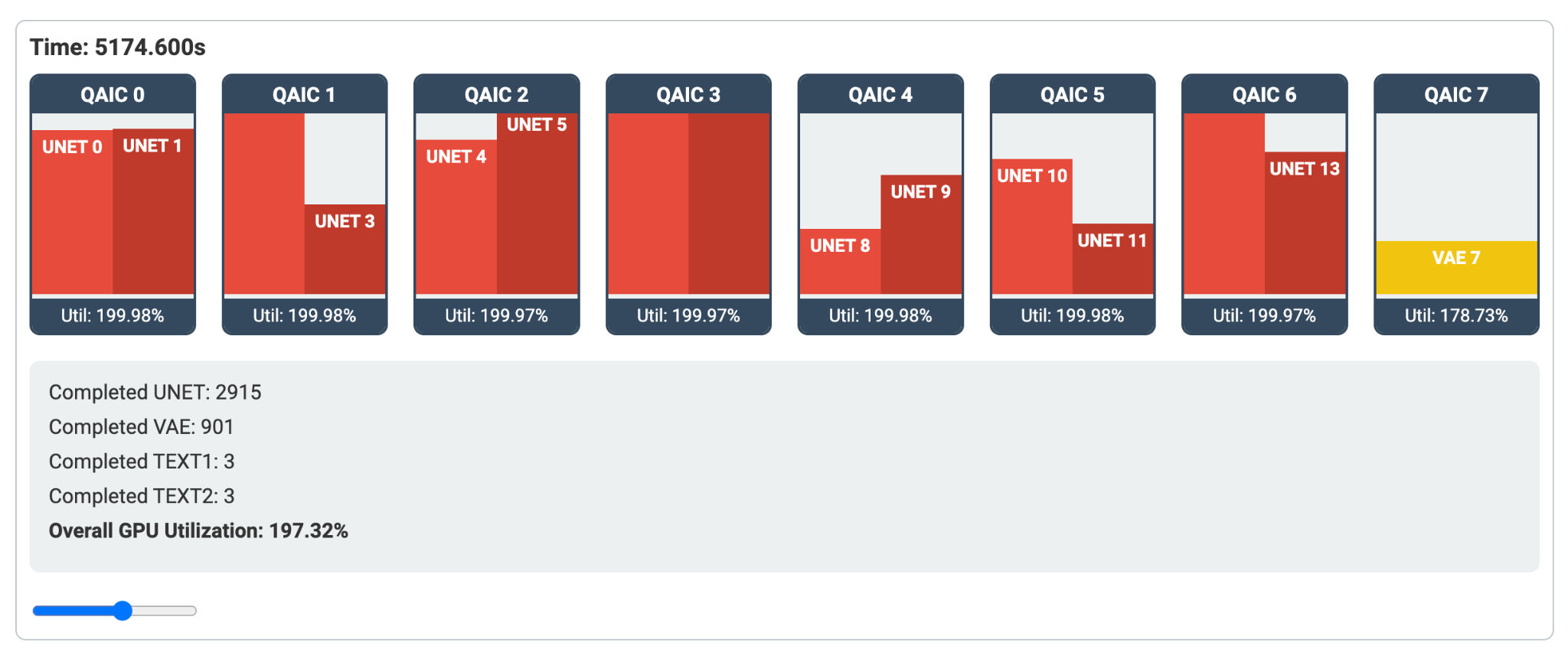
Next steps
Our work represents a step forward in performance and efficiency of text-to-image generation on Qualcomm Cloud AI 100 accelerators.
Looking ahead, we are exploring even more advanced optimization techniques. We’re developing an auto-scheduling system based on compiled model runtime information, leveraging greedy algorithms to dynamically allocate tasks for maximum efficiency. This approach promises to further push the boundaries of SDXL inference performance on Qualcomm Cloud AI 100 accelerators.
Try out the Qualcomm AI Inference Suite including our SDXL text-to-image inferencing.
[1] Ma, Xinyin, Gongfan Fang, and Xinchao Wang. “DeepCache: Accelerating diffusion models for free.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
Junfan Huang
Senior R&D Engineer, KRAI
Dr Anton Lokhmotov
Founder & CEO, KRAI
Natarajan Vaidhyanathan
Senior Director of Technology, Qualcomm Technologies