
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
How our pioneering research and leading proof-of-concepts are paving the way for generative AI to scale
What you should know:
-
Qualcomm AI Research is pioneering research and inventing novel techniques to deliver efficient, high-performance GenAI solutions.
-
Our full-stack AI research allows us to be first in demonstrating GenAI proof-of-concepts on edge devices.
-
By tackling system-level and feasibility challenges, we transform GenAI breakthroughs into real-world, scalable products.
At Qualcomm, we don’t just imagine the future — we engineer it. Our AI breakthroughs are the result of a relentless pursuit of innovation, where foundational research meets full-stack engineering to deliver world-firsts that run on real edge devices.
Building on our AI firsts blog post, this post focuses on generative AI (GenAI) firsts, showcasing how Qualcomm AI Research has pioneered novel techniques and delivered proof-of-concept implementations that push the boundaries of what’s possible on device. From large language models (LLMs) to embodied AI, our generative AI firsts are not just theoretical — they’re proven, scalable and deployable. I’ll briefly describe a few innovations and world-first demonstrations, but please tune into my webinar for a more detailed explanation across eight different generative AI research areas.

LLMs: Redefining edge intelligence
Qualcomm AI Research has achieved multiple world-first breakthroughs that are transforming how language models operate in real-world applications. Among our most impactful innovations are advanced parallel decoding techniques that dramatically boost token generation speed without sacrificing accuracy. It began with speculative decoding (SD), evolving into self-speculative decoding and the cutting-edge SD 2.0.
We were the first to demonstrate self-speculative decoding on mobile at Snapdragon Summit 2024 — a game-changing parallel decoding technique that utilizes the target model to accelerate token rate, eliminating the need for a separate draft model. This leap-forward innovation unlocks faster, smoother and more natural interactions with AI assistants and chatbots, bringing next-gen responsiveness directly to your fingertips.

Multimodal: Fusing modalities for richer understanding
Multimodal GenAI is revolutionizing user interaction, making experiences more intuitive, intelligent and productive. By seamlessly integrating diverse inputs like text, voice, images, video and sensor data, it provides richer, context-aware responses. We invented ultra-efficient visual encoders, minimizing memory and compute while achieving top-tier accuracy. For example, we increased input image resolution by five times, accelerated the vision encoder by three times and reduced token output by four times — all while achieving 149% accuracy boost in single-image visual question answering.
And most notably, we unveiled the first large multimodal model (LMM) running on Android at MWC 2024, proving that high-performance language and vision models can operate efficiently on smartphones, bringing powerful GenAI directly to mobile users.

Agentic AI: Autonomous reasoning at the edge
Agentic AI systems are redefining autonomy by making intelligent decisions and taking purposeful actions based on their environment and user goals. With on-device deployment, agentic AI delivers deeply personalized and efficient user experiences. We invented chain-of-rank and inference-time-compute methods, significantly enhancing the planning accuracy of agentic LLMs.
At MWC 2025, we led the industry by being the first to showcase retrieval-augmented generation (RAG) on mobile, integrating chat history and third-party app queries. This allows agents to pull relevant information from past interactions and external sources, resulting in more contextual and useful responses.

Embodied AI: Intelligence in motion
Embodied AI transforms edge devices into intelligent agents that can perceive, reason and act within the physical world, and we are at the forefront of this evolution. We invented end-to-end automotive planner models that reduce collision rates of the previous best models by an impressive 80%, setting a new benchmark for autonomous agents in dynamic, mobile environments. Designed to operate in real time, these models are ideal for applications in navigation, robotics and personal assistance.
At CVPR 2023, we showcased the first fitness coach LMM that processes live video in real time, interacting with users to guide workouts and provide feedback. This model understands human movement and responds dynamically, making it a powerful tool for health and wellness applications.

Model efficiency: Preserving energy and maximizing performance
Efficiency is fundamental to our AI strategy, driving many layers of our innovations. We take a holistic approach to optimize model efficiency across multiple dimensions, spanning model architecture, quantization, distillation and heterogeneous computing. For example, we invented state-of-the-art weight and activation quantization methods tailored for LLMs, including function preserving transformations (FPTs).
At MWC 2025, we were first to demonstrate AdaScale quantization on reasoning models running efficiently on mobile, enabling low-power INT4 inference while maintaining accuracy.

Model adaptation: Personalized AI at scale
Delivering high-quality user experiences with generative AI on mobile devices demands personalization, where models adapt to individual users’ preferences, language styles and usage contexts. This requires efficient fine-tuning methods that operate under strict resource constraints without compromising responsiveness. Model adaptation enables AI to remain relevant, responsive and personalized. We invented model adaptation methods that drastically improve quality and latency, such as Fourier low-rank adaptation (FouRA). We also pioneered model adaptation techniques that do not rely on additional training or datasets.
At MWC 2024, we demonstrated the first dynamically-adjusted and fast-switching LoRA on mobile, enabling models to reconfigure themselves in real time based on user preferences.

Generative video: Reshaping creativity
From transforming static images into dynamic scenes to reimagining existing videos with new styles or contexts, our efficient video generation models bring advanced visual capabilities directly to mobile devices.
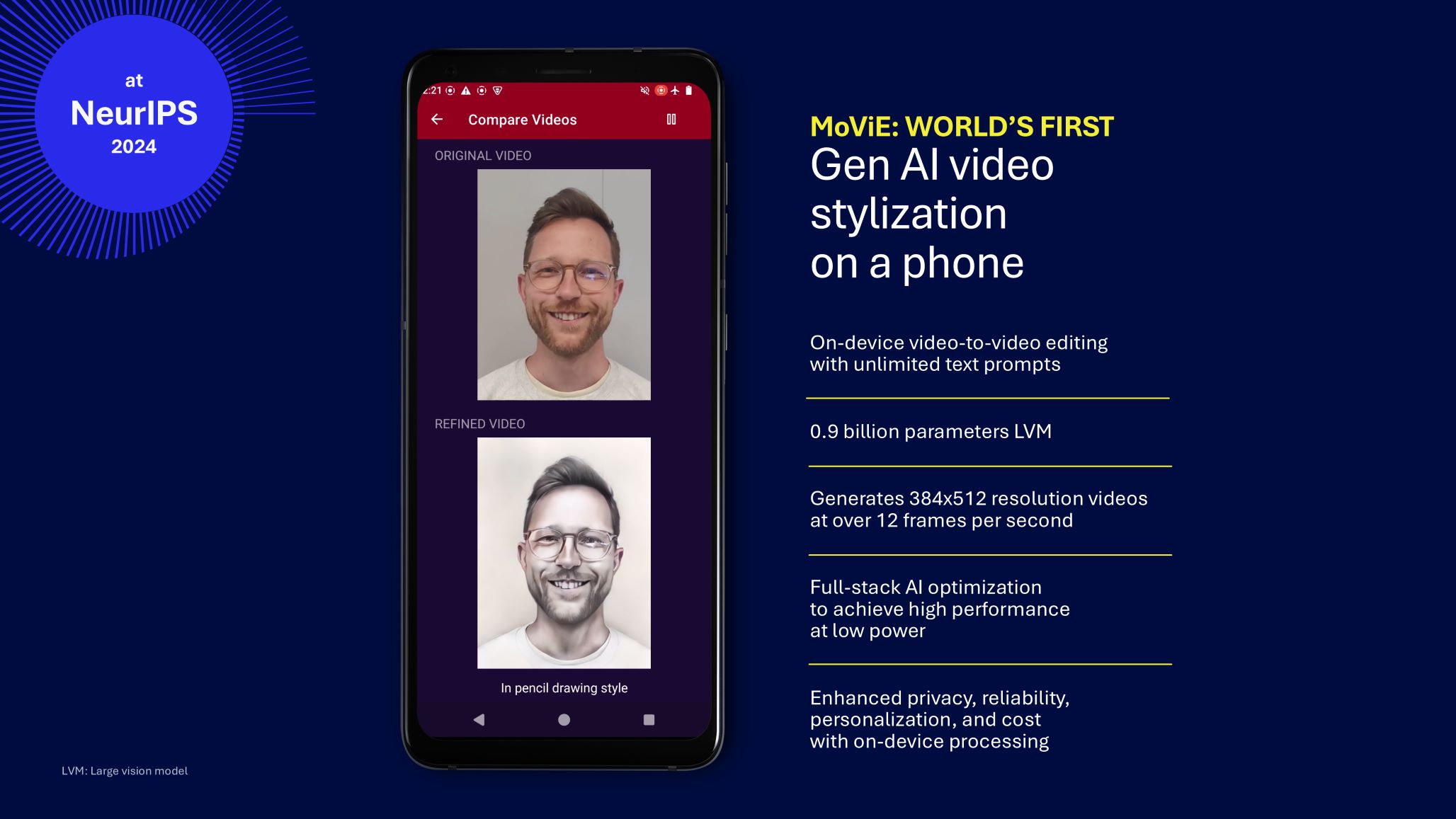
At NeurIPS 2024, we introduced the world’s first real-time video stylization and editing model allowing unlimited text prompts on a smartphone. Enabled by full-stack AI optimizations, this breakthrough delivers high performance at low power, while enhancing privacy, reliability and personalization — all without relying on cloud processing.
Building on that momentum, we showcased another industry first at CVPR 2025: real-time, on-device image-to-video generation on a smartphone. These innovations are redefining mobile experiences, allowing users to produce expressive, high-quality video content instantly and privately. By pushing the boundaries of what’s possible on-device, we are making sophisticated visual tools more intuitive, personal and widely available.
Generative image and 3D: Transforming creative processes
We developed the world’s first and fastest high-resolution text-to-image generation models, along with the first text-to-3D system capable of producing fully textured 3D meshes directly from a text prompt on-device. Traditional approaches rely on costly optimization loops to fit mesh parameters for each object, often taking over 20 minutes to produce a single model. In contrast, our efficient feed-forward architecture predicts mesh parameters instantly at inference, eliminating the need for iterative processing. Trained from scratch on a small 3D dataset, our model sets a new standard for speed and efficiency in spatial content generation.
At NeurIPS 2024, we showcased the first mobile video game powered by real-time text-to-3D generation, enabling personalized gameplay experiences with textured meshes rendered in under 3.5 seconds. This breakthrough brings immersive, responsive 3D environments to mobile platforms, unlocking new possibilities in gaming, AR, design and education. By making advanced 3D modeling fast, intuitive and accessible, we are redefining how users interact with spatial media.

A legacy of world firsts
These achievements are not isolated. They’re part of a broader vision to make AI ubiquitous. From the first transformer-based inverse rendering to the first LMM on Android, Qualcomm AI Research continues to deliver innovations that shape the future of technology.
Each breakthrough is the result of our full-stack approach, which spans model design, algorithms, software and hardware. By rigorously testing our research in real-world conditions, we ensure that our AI firsts are not just ideas — they’re on the path to commercialization.
As we continue to explore new frontiers in generative AI, our commitment remains the same: to lead with research, validate with proof-of-concept and scale through product commercialization. The future of AI is not just imagined — it’s engineered.
Fatih Porikli
Senior Director of Technology, Qualcomm Technologies, Inc.