
This blog post was originally published at SiMa.ai’s website. It is reprinted here with the permission of SiMa.ai.
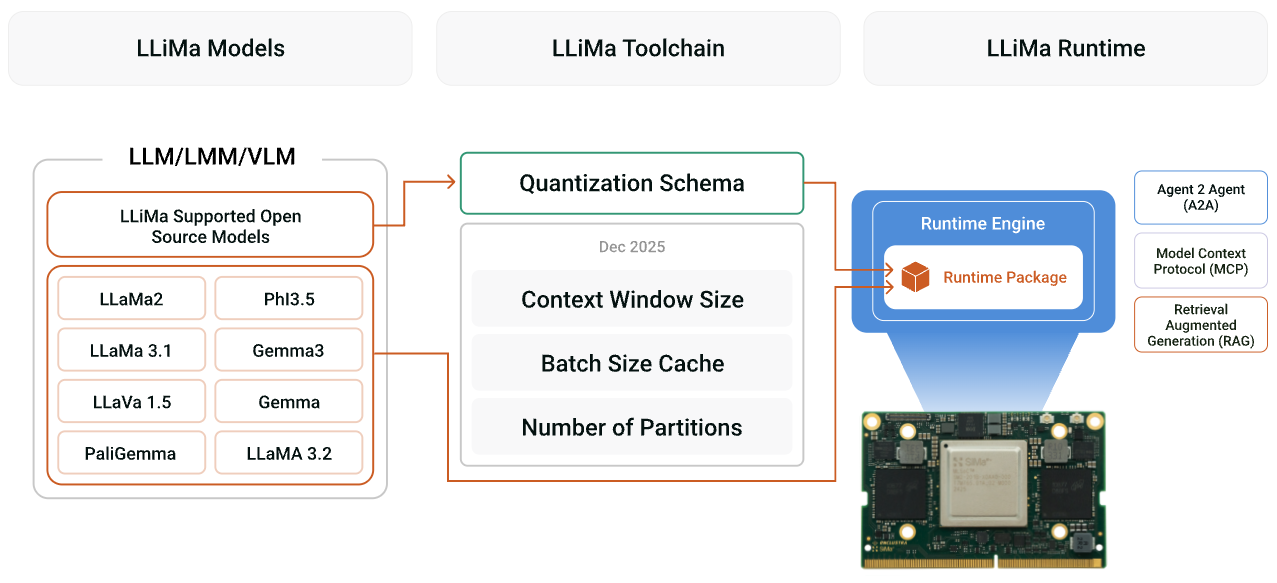
LLiMa represents a paradigm shift in physical AI deployment that fundamentally changes how enterprises approach GenAI integration, enabling real Physical AI. While competitors typically offer pre-optimized models that were manually tuned for specific hardware configurations, LLiMa takes an entirely different approach with its automated compilation and optimization framework.
With LLiMa, deploying LLMs in Physical AI applications is no longer a manual engineering effort, it’s a single, fully automated step. Integrated within SiMa.ai’s Palette, LLiMa automatically configures your model, applies quantization, optimizes memory and compute, compiles and packages it – ready for seamless performant execution on the edge. No code, no complex SDKs – just a simple workflow that results in production-ready applications.
Watch: LLiMa on Modalix: Installing on Devkit
Why LLMs are Moving from Cloud to Physical AI
Cloud GPU stacks deliver raw throughput but they carry unpredictable per-token costs, data-egress fees, and connectivity/latency risks. High-power edge GPUs improve performance but add heat, fans, and BOM/operational overhead.
References to support this:
- Cosine: Pricing AI Coding Agents: Why Pay-Per-Token Won’t Last
- Rafay: The Hidden Costs of Running Generative AI Workloads—And How to Optimize Them
- Hashroot: Edge AI vs. Cloud AI in 2025: Where Should You Run Your Workloads?
- Engineered Systems News: Meeting the Deamnds of AI Edge and High Performance Computing by Rethinking Cooling
LLiMa on Modalix (<10W) gives you:
- Real-time interactions on-device (no round trips), even where connectivity is constrained or non-existent.
- Predictable costs (no pay-per-token surprises).
- Data privacy and compliance (keep video, voice, and sensitive prompts on premise).
- Consistent performance under sustained workloads, no thermal throttling or degradation over time.
- A repeatable path: automate compilation, quantization, scheduling, and runtime orchestration instead of re-engineering per model.
The Deeper Transformation at Play: Cloud to Physical AI
This shift reflects a fundamental maturation of the GenAI market. Early adoption was driven by experimentation and proof-of-concept work where cloud costs seemed reasonable for testing. But as enterprises scale from pilots to production deployments, especially in customer-facing applications, the economics become untenable. When you’re processing thousands of customer interactions daily, those per-token fees compound into budget-breaking expenses.
The Physical AI migration also signals that AI is becoming truly embedded in business operations rather than being a novelty add-on. Industries like manufacturing, healthcare, and retail need AI responses in milliseconds, not the 200-500 milliseconds cloud round trips that break user experience. More critically, sectors handling sensitive data, financial services, healthcare, and government, are discovering that regulatory compliance becomes exponentially simpler when AI processing never leaves their premises.
The power and thermal problem
Traditional physical AI solutions face a critical but often overlooked challenge: thermal management. High-power GPUs and edge accelerators along with supporting components such as the CPU, DRAM, and system peripherals generate significant heat during sustained AI workloads, triggering thermal throttling that gradually degrades performance over hours of operation. This creates a vicious cycle of performance degradation and throttling of system performance. For enterprise applications relying on stringent and consistent latencies, thermal variability would be unacceptable, and would lead to having to spend more or over-designing the system to ensure throughput targets are met and kept throughout the operational lifetime of the system.
The problem compounds in environments like retail stores, manufacturing floors, or vehicle installations where ambient temperatures fluctuate and cooling systems are limited. What starts as sub-second inference can degrade to multi-second delays as thermal limits are reached, making the system unsuitable for customer-facing applications.
Modalix’s ultra-low power consumption (<10W) eliminates thermal throttling entirely, while its statically scheduled architecture ensures every inference runs with identical, predictable timing for the same input size. This thermal stability transforms AI from an unpredictable performance wildcard into a reliable system component that enterprises can depend on for mission-critical applications.
There’s also a strategic independence factor. Enterprises are recognizing the risk of being locked into cloud providers’ AI infrastructure pricing and availability. By moving inference to the edge, they regain control over their AI capabilities and can optimize for their specific workloads rather than accepting one-size-fits-all cloud solutions.
Articles that defend this point:
- CIO: CIOs Weigh the New Economics and Risks of Cloud Lock-in
- ACL Digital: The Multi-Cloud Revolution: Breaking Free from Vendor Lock-in [2024 Updated]
- Financial Times: Why it is vital that you understand the infrastructure behind AI
- Cake: Why Cake Beats AWS SageMaker for Enterprise AI
- TechRadar: Europe needs to decouple from Big Tech USA: Here’s 5 ways it can be achieved
The technical enablement piece is crucial too. Modalix embodies this convergence, ultra-low-power hardware (<10 W) paired with SiMa.ai’s advanced model static scheduling, and runtime orchestration. This integration turns edge deployment from a theoretical possibility into a repeatable, engineering-driven process. Instead of treating every model deployment as a bespoke R&D exercise, Modalix enables predictable, production-grade AI pipelines that meet strict latency, thermal, and compliance requirements. In other words, it signals that we’ve entered the “pragmatic adoption” phase; where scaling AI to the edge is no longer about proving it can work, but about executing it efficiently, reliably, and at scale.
Where it Fits: Common Verticals and High-Impact Uses
When Machines Understand Your Commands
Picture this: It’s the middle of a scheduled production changeover at a food processing plant. The shift has been planned for days: frozen pizzas in the morning, chicken nuggets in the afternoon. A new floor operator is tasked with making the switch. The industrial oven in front of them looks like mission control: dozens of buttons, cryptic displays showing “MODE 3A” and “TEMP PROF 7,” and a thick manual that would make a phone book jealous.
In the old world, even with planning, this operator might spend valuable minutes cross-checking cycle times, oven profiles, and conveyor speeds, calling a supervisor to confirm settings, or waiting on customer service from the equipment vendor to avoid an expensive mistake. Every delay eats into the carefully scheduled production window, and misconfigurations can trigger costly QA failures or rework.
With an LLM-powered interface, the operator simply says, “Switch to the chicken nugget profile.” The system, trained on years of production data, QA protocols, and equipment manuals, instantly confirms: “Loading pre-approved chicken nugget cycle: 375°F convection mode, belt speed 12 feet per minute, breading station mist activated. Estimated warm-up: 8 minutes.” Instead of flipping through binders or calling for help, changeovers happen faster, with fewer errors, less reliance on senior staff, and reduced downtime, keeping the line on schedule and QA on target.
Error Code Explainer: When “E47” Actually Means Something
Every maintenance technician has been there. You’re called to a critical production line that’s down, and the only clue is a cryptic code blinking on a display: “E47.” The traditional ritual begins: dig through filing cabinets for the right manual, call the equipment manufacturer’s support line, or rely on Joe from maintenance who might remember what E47 means. Even when you find the manual, you’re greeted with something like: “E47: Sensor fault detected in Module 3B. Check connections, verify power supply.” You still don’t know if it’s a $5 loose wire or a $5,000 sensor replacement.
An LLM system instantly translates “E47” into plain English: “The vibration sensor on conveyor belt #3 isn’t getting a signal. This usually happens when the sensor cable gets pinched under the belt tensioner. It’s a known issue after about 18 months of operation.” The system provides step-by-step repair guidance with exact part numbers and installation videos, then asks for a photo to verify the fix worked. What once took hours of detective work and multiple phone calls now takes 15 minutes, with the LLM’s vision capabilities confirming the repair before you restart the line.
What once took hours of detective work and multiple phone calls now takes 15 minutes. The result is faster recovery times, less downtime, fewer service calls, lower maintenance costs, and a reduced need for highly specialized labor. Keeping production lines running and maintenance budgets under control.
Automotive: The ghost in the machine
Picture this: You’re on your way to an important meeting when the check engine light suddenly flicks on. Concern sets in. Is this serious? Can you keep driving? Traditionally, you might call a mechanic for advice, pull over to search for answers on your phone, or make an expensive trip to the dealer, only to discover it was a minor sensor glitch.
Now, imagine saying, “Hey, the engine light came on, what’s going on?” The LLM-powered system responds in plain English: “Your oxygen sensor is reporting a slightly rich mixture. Common causes are a minor sensor misread or a temporary exhaust fluctuation. You can continue driving safely, but I’ll log this and suggest a service appointment next week.”
From there, the conversation flows naturally: “Change the radio to something upbeat for my presentation,” “Find me the fastest route that avoids construction on I-95,” and even “Walk me through changing a flat tire step-by-step.” This is the kind of capability only possible when LLMs run locally at the edge. In the middle of the Rockies, with no internet and no cell signal, your car can still guide you through complex repairs, adapt to your preferences, and act as a real copilot, context-aware, responsive, and always available.
Robotics: The Household Helper That Actually Helps
A working mom or dad juggling dinner prep while her toddler demands attention and dishes pile up in the sink. Traditional home robots are glorified vacuum cleaners, single-purpose machines that bump into furniture and get confused by a sock on the floor. Even “smart” robots require precise programming through clunky apps, and if you move it to a different set up, they’re lost. Lisa doesn’t have time to map rooms, set waypoints, or troubleshoot why the robot thinks the kitchen island is a wall.
Instead, Lisa simply says, “Hey robot, help me wash the dishes.” The LLM-powered household assistant springs into action, using its vision system to assess the situation: “I can see plates, glasses, and pans in the sink. I’ll start by clearing the counter space, then rinse items in order from least to most greasy. Should I load the dishwasher or hand-wash the wine glasses?” As it works, the robot adapts to obstacles. Navigating around Lisa’s toddler, pausing when someone opens the dishwasher, and even asking, “I notice you’re cooking pasta, should I save some pasta water in this jar like you did last week?” The robot doesn’t just follow commands; it understands the full context of household life and proactively helps in ways that actually matter. This has always been science fiction. However, now we are closer than ever before https://www.youtube.com/shorts/vsvi0s6XETA.
Breaking Free from Manual Optimization Constraints
LLiMa’s automatic architecture adaptation fundamentally transforms how enterprises deploy custom AI models at the edge. Traditional physical AI solutions force you into a rigid framework where only manually pre-optimized models work, essentially trapping you in a limited catalog of someone else’s choices. LLiMa’s intelligent ML compiler breaks these constraints by automatically compiling supported Hugging Face models into optimized code for the Modalix MLSoC’s patented statically scheduled architecture, giving you access to a wide ecosystem of modern LLMs and VLMs.
Complete System Integration: Beyond model compilation, LLiMa provides enterprise-grade infrastructure components including MCP-compatible data connectors, automated RAG pipeline deployment, and A2A communication protocols. This transforms individual models into collaborative AI systems that can access enterprise data, reference knowledge bases, and coordinate across multiple specialized agents—all while maintaining the security and performance advantages of edge deployment.
The Complete physical AI Ecosystem
LLiMa doesn’t just run models. It provides a complete enterprise AI infrastructure that seamlessly integrates with your existing systems and workflows. While your LLMs run locally on Modalix hardware, LLiMa’s framework extends their capabilities through three key integration layers:
Model Context Protocol (MCP) Integration: Your edge-deployed models can securely connect to enterprise data sources, databases, and APIs without exposing sensitive information to external services. Whether it’s pulling customer records, accessing inventory systems, or retrieving compliance documentation, MCP enables your local AI to work with live enterprise data.
Retrieval-Augmented Generation (RAG) Pipeline: LLiMa automatically orchestrates local RAG workflows, combining your fine-tuned models with enterprise knowledge bases, technical documentation, and proprietary datasets. This means your manufacturing AI can reference the latest safety protocols, your customer service AI stays current with product updates, and your diagnostic AI accesses the most recent troubleshooting guides—all without internet dependencies.
Agent-to-Agent (A2A) Communication: Deploy multiple specialized AI agents across your infrastructure that can collaborate intelligently. Your predictive maintenance agent can communicate with inventory management agents, quality control agents can coordinate with production planning agents, and customer service agents can seamlessly hand off to technical support agents—creating a distributed AI workforce that operates autonomously while maintaining human oversight.
Physical AI: LLMs on Modalix Under 10 Watts

Currently Supported Model Architectures
- LLaMA family: Llama-2, Llama-3, Llama-3.1, Llama-3.2 (up to 8B parameters)
- Gemma series: Gemma-2, Gemma-3 (2B-4B parameters)
- Microsoft Phi: Phi-3.5-mini and variants
- Vision-Language Models: LLaVA-1.5, PaliGemma with CLIP and SigLIP vision encoders
- More Models coming soon!
Real Performance Data (all models running <10W)

All models exceed the 3.5 TPS threshold required for real-time conversational AI, with context lengths up to 4096 tokens (1024 recommended for optimal compilation times).
Automated Optimization Pipeline
LLiMa’s framework currently implements a sophisticated five-stage optimization process:
- Architecture Analysis: Hugging Face config.json stores a model’s architecture parameters and settings (like hidden size, number of layers, vocab size, etc.) so the framework knows how to load and use the model correctly. We start the process with the automatic parsing of Hugging Face config.json files to extract model parameters (attention heads, hidden layers, embedding dimensions)
- Component Segmentation: Each transformer layer is automatically divided into three optimized components:
- Pre-cache: QKV projection and position embedding
- KV cache accessor: Self-attention mechanism with parameterized granularity
- Post-cache: Output projection and feed-forward networks
- Static Scheduling: Unlike dynamic dispatch systems, Modalix’s patented statically scheduled architecture provides cycle-level operation knowledge, enabling:
- Predictable inference timing.
- Precise power management
- Deterministic latency for mission-critical applications
- Multi-Level Quantization: Flexible precision options with automatic trade-off optimization:
- BF16: Full precision baseline.
- INT8: Less accurate but faster performance, it also utilizes less memory.
- INT4: Least accurate and fastest configuration, minimal memory usage.
- Runtime Orchestration: Automated pipeline coordination across Modalix’s APU and MLA components
To learn more about the technical implementation check out LLiMa: SiMa.ai’s Automated Code Generation Framework for LLMs and VLMs for < 10W.
Direct Compilation of Custom Models
LLiMa’s automation framework extends to your own custom models. If you’ve invested time and resources into retraining or fine-tuning a supported model architecture, whether it’s a domain-specific LLaMA variant, a custom LLaVa fine-tune for your industry, or a specialized vision-language model. LLiMa can directly compile it without requiring you to understand the intricacies of hardware optimization. You don’t need to learn what kernel modifications to make, how to adjust memory layouts, or which quantization strategies work best with your specific model changes. The compiler handles all of this for supported models automatically.
Deployment Timeline Transformation
- Traditional: Model training → Manual optimization (months) → Integration testing → Performance tuning
- LLiMa: Trained Model → Automatic compilation (hours) → Direct deployment validation.
How We Compare to Alternative Stacks
Comprehensive Performance and Cost Analysis
| Deployment Option | System Power | Latency and UX | Cost Model | Integration and Ops | Data Posture |
| LLiMa on Modalix | <10W | Real-time on-device (0.12-1.38s TTFT, 6-17 TPS) | Predictable (no per-token/egress fees) | Automated compile & runtime orchestration | Private by default (on-device processing) |
| High-power edge GPU modules | 15–60W+ | Low latency on-prem | Hardware + power/thermal budgets | Manual model porting & thermal management | On-prem, higher BOM complexity |
| Cloud GPU (datacenter) | 250–700W/accelerator (off-device) | Network-dependent latency spikes | Variable per-token + data egress fees | Dev-friendly start, unpredictable scaling costs | Data leaves premises, compliance overhead |
Quantified Advantages
- Power Efficiency: 15-70x lower power consumption than alternatives
- Thermal Reliability: Zero thermal throttling vs. performance degradation in high-power solutions
- Cost Predictability: Fixed hardware costs vs. variable per-token pricing that scales unpredictably
- Compilation Speed: Hours vs. months for custom model deployment
- Enterprise Integration: Native MCP, RAG, and A2A support eliminates complex middleware and custom API development
- Data Sovereignty: Complete AI workflows run on-premises while accessing live enterprise data
- Agent Orchestration: Multi-agent coordination without cloud dependencies or external API calls
Technical Validation Results
Our performance measurements demonstrate consistent real-time capability across all supported architectures:
- Time-to-First-Token: 0.12-1.38 seconds (well below 2-second user experience threshold)
- Sustained Throughput: 6-17 tokens per second (exceeds 3.5 TPS conversational minimum)
- Power Consumption: Sub-10W across all model configurations
- Context Support: Up to 1024 tokens with flexible KV cache granularity
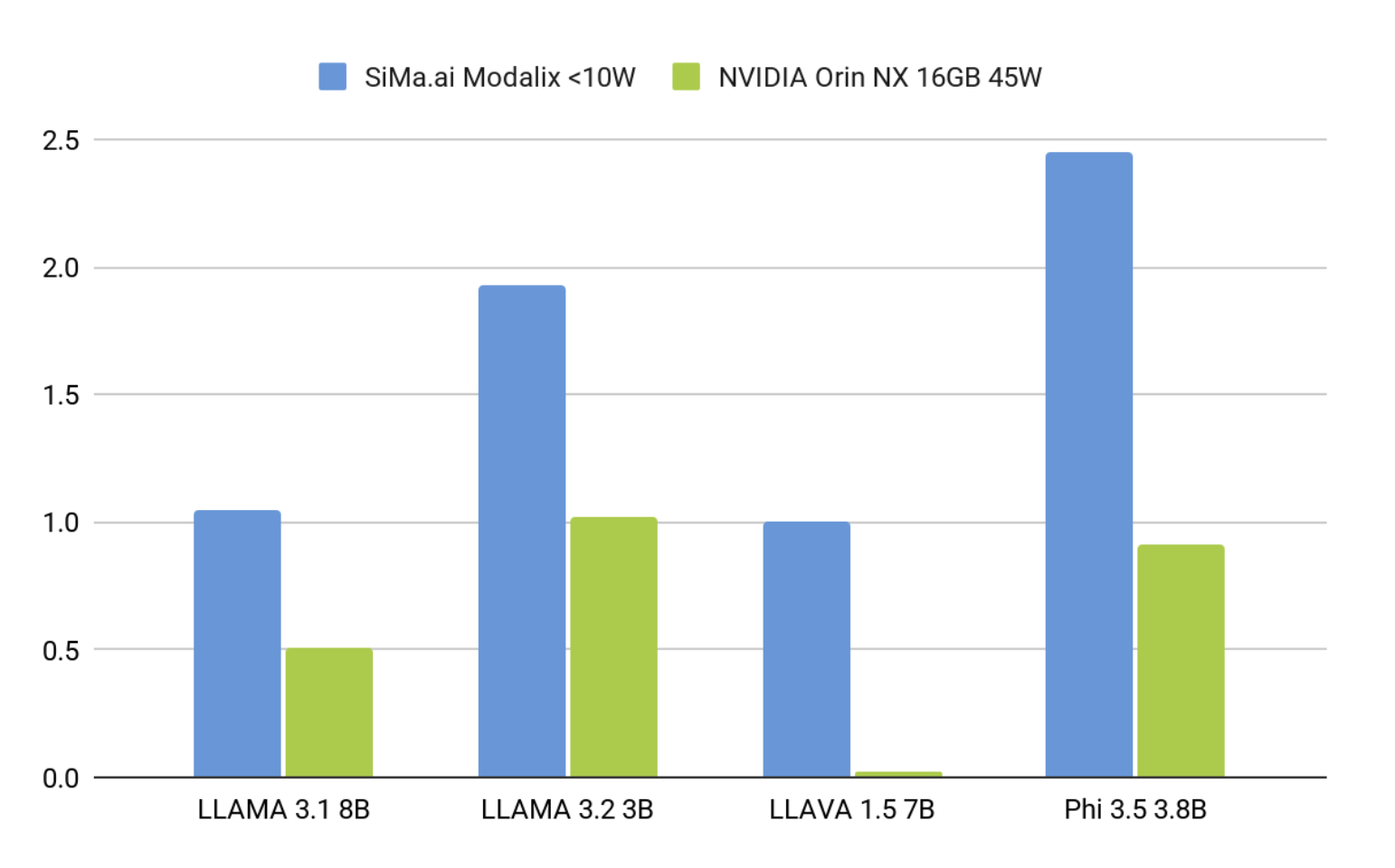
Figure 3 uses a maximum context length of 1,024 tokens, an input prompt size of 100 tokens for LLMs (including the system prompt), and an input prompt size of 100 + n tokens for VLMs, where n is the number of tokens produced by the vision encoder for the input image.
Download Links: Pre-compiled models available at our Hugging Face repository for immediate evaluation on Modalix systems.
Unlocking Specialized Use Cases
This capability opens up transformative use cases that were previously impractical for edge deployment:
Industry-Specific Intelligence: Deploy medical diagnostic models trained on proprietary datasets, financial risk assessment models with custom regulatory compliance features, or manufacturing quality control models fine-tuned on your specific production line data, all running locally with sub-10W power consumption.
Personalized AI Systems: Run customer-specific recommendation engines, personalized content generation models, or adaptive user interface systems that have been fine-tuned on individual user behaviors, maintaining privacy while delivering tailored experiences.
Rapid Prototyping and A/B Testing: Test multiple model variants in production environments simultaneously. Compare a standard pre-trained model against your fine-tuned version, or evaluate different quantization strategies, all without the traditional months-long optimization cycles.
Continuous Model Evolution: As your models improve through ongoing training or as new base models become available, simply recompile and deploy. Your edge infrastructure adapts automatically rather than requiring extensive re-engineering.
Why Static Scheduling Changes Everything
Traditional physical AI accelerators use dynamic dispatch, making scheduling decisions in real-time as operations execute. This approach works for cloud environments with unlimited power budgets, but creates unpredictable performance and thermal behavior at the edge.
Modalix’s patented statically scheduled architecture represents a fundamental architectural shift. During compilation, LLiMa’s compiler gains complete knowledge of which operations execute during every cycle. This enables:
Predictable Performance: Every inference with same input and output size runs with identical timing, regardless of input complexity or environmental conditions
Thermal Stability: Precise power management eliminates the thermal throttling that degrades other edge solutions over time
Memory Optimization: Static knowledge enables optimal tensor placement and data movement patterns
Real-Time Guarantees: Deterministic execution timing makes Modalix suitable for safety-critical applications where response time variance is unacceptable
Quantization Without Compromise
LLiMa implements a sophisticated quantization strategy that maintains accuracy while dramatically reducing memory bandwidth requirements:
Parameter Quantization: Static compression of model weights to INT8 or INT4 precision using advanced block quantization techniques that preserve accuracy
Activation Quantization: Dynamic BF16→INT8 compression performed on-chip, eliminating the need for calibration datasets
Memory Bandwidth Impact: INT4 quantization reduces DRAM transfers by 4x compared to full precision, directly translating to power savings and faster inference
This multi-tiered approach allows developers to select the optimal accuracy/performance trade-off for their specific use case, with quantization options ranging from near-lossless INT8 to aggressive INT4 compression.
Getting Started
- Evaluate: Download pre-compiled models from our HuggingFace repo in your Modalix system and measure TTFT/TPS, .
- Bring your model via Palette SDK: Compile with LLiMa, select quantization (BF16 → INT8 → INT4), and deploy on your Modalix system.
- Pilot to production: Size hardware, integrate app logic (prompts, safety layer), and roll out to your fleet.
Ready to see real-time GenAI at the edge under 10W? Let’s set up a demo and an evaluation plan tailored to your use case here.
Manuel Roldan, Software Product Manager, SiMa.ai