
This article was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
State-of-the-art image diffusion models take tens of seconds to process a single image. This makes video diffusion even more challenging, requiring significant computational resources and high costs. By leveraging the latest FP8 quantization features on NVIDIA Hopper GPUs with NVIDIA TensorRT, it’s possible to significantly reduce inference costs and serve more users with fewer GPUs. While deploying a quantized diffuser can be complex, the full ecosystem behind TensorRT can help overcome these challenges.
Using this approach, Adobe achieved a 60% reduction in latency and a nearly 40% reduction in TCO, enabling faster inference and improved responsiveness. The optimized deployment using TensorRT running on Amazon Web Services (AWS) EC2 P5/P5en accelerated by Hopper GPUs enables improved scalability, serving more users with fewer GPUs.
This post explores the strategies and optimizations implemented to enhance the performance of the Adobe Firefly video generation model, focusing on reducing latency, cutting costs, and accelerating deployment to market.
Revolutionizing creative AI with Adobe Firefly and NVIDIA TensorRT on AWS
With Firefly, users can generate detailed images from text prompts in moments, streamlining the creative process. For instance, a single video diffusion model can require more computing than a single image diffusion model.
The rapid development of Firefly and Adobe’s ongoing collaboration with NVIDIA are both driven by the need for fast, efficient, and scalable AI inference and training solutions. TensorRT provides the hardware acceleration and model optimization tools for Adobe to deploy their innovative generative models swiftly and at scale, ensuring they stay at the forefront of creative AI technology.
 Figure 1. Time to market was under four months in 2024 for the Adobe Firefly video generation model, from research to private beta
Figure 1. Time to market was under four months in 2024 for the Adobe Firefly video generation model, from research to private beta
Adobe Firefly launch
The Adobe Firefly launch (October 2024) has been nothing short of spectacular. It is one of the most successful beta launches in Adobe’s history. The numbers speak for themselves:
- Over 70 million images generated in the first month alone
- To date, Firefly has powered the creation of over 20 billion assets
- Integration across Adobe’s creative suite, including Adobe Photoshop, Adobe Premiere Pro, Adobe Express, and Adobe Illustrator
Leveraging TensorRT for efficient deployment
To address the challenges of scaling diffusion models, Adobe used NVIDIA TensorRT, a high-performance deep-learning inference optimizer. The latest FP8 quantization on NVIDIA H100 GPUs enabled the following:
- Memory footprint reduction: FP8 significantly lowers memory bandwidth while accelerating Tensor Core operations
- Inference cost savings: Fewer GPUs are required for the same workload
- Seamless model portability: TensorRT support for PyTorch, TensorFlow, and ONNX made deployment efficient
TensorRT optimizes and deploys models in various frameworks, including PyTorch and TensorFlow, making it an ideal choice for Adobe’s use case. The optimization process involved several key steps:
Step 1: ONNX export
Adobe chose ONNX (Open Neural Network Exchange) for its versatility and ease of export. This decision allowed for seamless code sharing between research and deployment, eliminating the need for time-consuming reimplementation.
Step 2: TensorRT implementation
The team implemented TensorRT, focusing on mixed precision with FP8 and BF16. This approach significantly decreased the memory footprint for weights and activations, leading to lower memory bandwidth and accelerated Tensor Core operations. The FP8 format substantially reduces the memory footprint for weights and activations. The E4M3 FP8 format can be represented as:

where:
is the sign bit (1 bit)
is the exponent (4 bits)
is the fraction (3 bits)
is 7 for E4M3
This format allows for a range of representable values from approximately 1.52×10-2 to 4.48×102. E4M3 was chosen over E5M2 because it allows for more granular precision rather than higher spikes in activations. This tradeoff is most suitable to forward inference, while backpropagation can benefit from a wider value range.
Step 3: Quantization techniques
Adobe employed post-training quantization, using NVIDIA TensorRT Model Optimizer PyTorch API. The PyTorch API allows for the use of existing evaluation pipelines for built-in research. While the PyTorch FP8 emulation offered by TensorRT Model Optimizer does not reflect the actual performance improvements of FP8 execution, it enables a quick quality evaluation without requiring network export.
 Figure 2. Adobe Firefly video generator AI pipeline running on AWS
Figure 2. Adobe Firefly video generator AI pipeline running on AWS
Identifying bottlenecks with NVIDIA Nsight Deep Learning Designer
Using NVIDIA Nsight Deep Learning Designer, engineers pinpointed critical bottlenecks in the diffusion pipeline, including:
- Scaled Dot Product Attention (SDPA), is the primary computational bottleneck, leading to excessive latency.
- ONNX profiling allowed mapping of kernel execution times, showing inefficiencies in high-resolution image and video diffusion models.
INSERT FIGURE
Figure 3. GPU profiling tool analyzing the baseline ONNX model
By isolating these performance issues, Adobe’s team fine-tuned the Transformer backbone to improve execution speed and reduce memory consumption.
Overcoming deployment challenges with quantized diffusers
Deploying a quantized diffuser can be complex, requiring careful tuning of model parameters and quantization settings. However, the full ecosystem behind TensorRT, including the NVIDIA Deep Learning SDK and TensorRT Model Optimizer, helped Adobe overcome these challenges.
Adobe’s engineers implemented techniques for evaluating and improving quantization quality, including distribution analysis and the use of TensorRT Model Optimizer for auto quantization.
Quantization
Quantization maps a full-precision floating-point value BF16 to an FP8 representation using a scaling factor 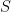

where:
is the quantized FP8 value
define the FP8 dynamic range, for example:
- For E4M3: Approximately [−448,448]
- For E5M2: Approximately [−57344,57344]
ensures values stay within the representable FP8 range
Dequantization
To recover the approximate full-precision value:

where:
is the reconstructed floating-point value
Scaling factor selection
The scaling factor
- Max-based scaling:
- Per-Tensor scaling: One scale for the entire Tensor

Error analysis (quantization noise)
The quantization error is often modeled as:

This follows a uniform distribution if properly scaled.
Handling FP8 formats
TensorRT supports E4M3 and E5M2 FP8 formats:
- E4M3 (1 sign bit, 4 exponent bits, 3 mantissa bits): Offers higher precision within a smaller dynamic range. It can represent values approximately in the range ±[1.52×10⁻², 448], including NaN.
- E5M2 (1 sign bit, 5 exponent bits, 2 mantissa bits): Offers a wider dynamic range with less precision. It can represent values approximately in the range ±[5.96×10⁻⁸, 57344], including ±inf and NaN.
The choice depends on the trade-off between precision and dynamic range.
Scalability and cost benefits for AI workloads
Adobe Firefly’s deployment on AWS played a crucial role in optimizing performance and ensuring seamless scalability. By leveraging the AWS high-performance cloud infrastructure, the team was able to maximize efficiency, reduce latency, and improve cost-effectiveness for large-scale AI workloads.
The optimized deployment using TensorRT has led to a 60% reduction in diffusion latency, a 40% reduction in total cost of ownership, significant cost savings, and improved scalability for Adobe’s creative applications. By reducing the computational resources required for diffusion model inference, Firefly has been able to serve more users with fewer GPUs, resulting in lower costs and improved efficiency.
 Figure 4. Diffusion backbone inference performance. NVIDIA TensorRT with BF16 and FP8 delivers up to 2.5x faster runtime compared to the PyTorch baseline
Figure 4. Diffusion backbone inference performance. NVIDIA TensorRT with BF16 and FP8 delivers up to 2.5x faster runtime compared to the PyTorch baseline
Future steps
Optimizing diffusion model deployment is crucial for making these powerful models accessible to a wider range of users. As Adobe continues to push the boundaries of creative AI, the lessons learned from Firefly’s development and deployment will shape future innovations. The combination of rapid development, strategic technical decisions, and relentless optimization has set a new standard in the world of generative AI. NVIDIA is excited to continue collaborating with Adobe and AWS to push the boundaries of what’s possible with diffusion models and deep learning.
For more information, check out the NVIDIA TensorRT documentation and watch the NVIDIA GTC session, Quantize Large Transformer Diffusion Models to Improve End-to-End Latencies and Save Inference Cost.
Related resources
- GTC session: Quantize Large Transformer Diffusion Models to Improve End-to-End Latencies and Save Inference Cost
- GTC session: Enable Blackwell Inference With TensorRT Model Optimizer
- GTC session: Tencent HunYuan: Building a High-Performance Inference Engine for Large Models Based on NVIDIA TensorRT-LLM
- SDK: Transformer Engine
- SDK: FasterTransformer
- Webinar: Accelerated Creative AI – Using NVIDIA-optimized image generation for Media and Entertainment
Maximilian Müller
Developer Technology Engineer for Professional Visualization, NVIDIA
Sagar Singh
Data scientist, NVIDIA
Abhinav Sharma
Senior Machine Learning Engineer, Firefly Team, Adobe
Allie Yang
Senior Machine Learning Engineer, Firefly Team, Adobe
Allen Philip
Senior Machine Learning Engineer, Firefly Team, Adobe