
This blog post was originally published at SiMa.ai’s website. It is reprinted here with the permission of SiMa.ai.
The AI hardware landscape is dominated by one uncomfortable truth: most teams feel trapped by CUDA. You trained your models on NVIDIA GPUs, deployed them with TensorRT, and now the thought of switching hardware feels like rewriting your entire stack from scratch.
Here’s the reality check you need: You don’t have to port CUDA. You never wrote CUDA in the first place.
The CUDA Myth That’s Costing You
Let’s start with what CUDA actually is and more importantly, what it isn’t in your workflow.
CUDA is NVIDIA’s proprietary parallel computing framework made for using GPUs to perform general-purpose processing (GPGPU). Traditionally, before AI, these were:

When ML came along, it too was a prime target of massively parallel computation, and NVIDIA seized the opportunity to expand CUDA for training/inference in ML.
Most teams never touch CUDA directly. They write models in PyTorch, JAX, TensorFlow or Keras; those frameworks call NVIDIA’s cuDNN/cuBLAS kernels through CUDA to accelerate training on GPUs. The “CUDA part” lives underneath the framework and underneath your code. When training finishes, the artifact you keep (the model graph + weights) does not embed CUDA kernels. It’s just math: ops, shapes, and parameters. Let’s take a look at the different layers:
The ML CUDA stack
When you export a model for inference, there’s no CUDA in it. When you ship a trained model to production, the model file contains math operations, shapes, and parameters not CUDA kernels.
The stack looks like this:
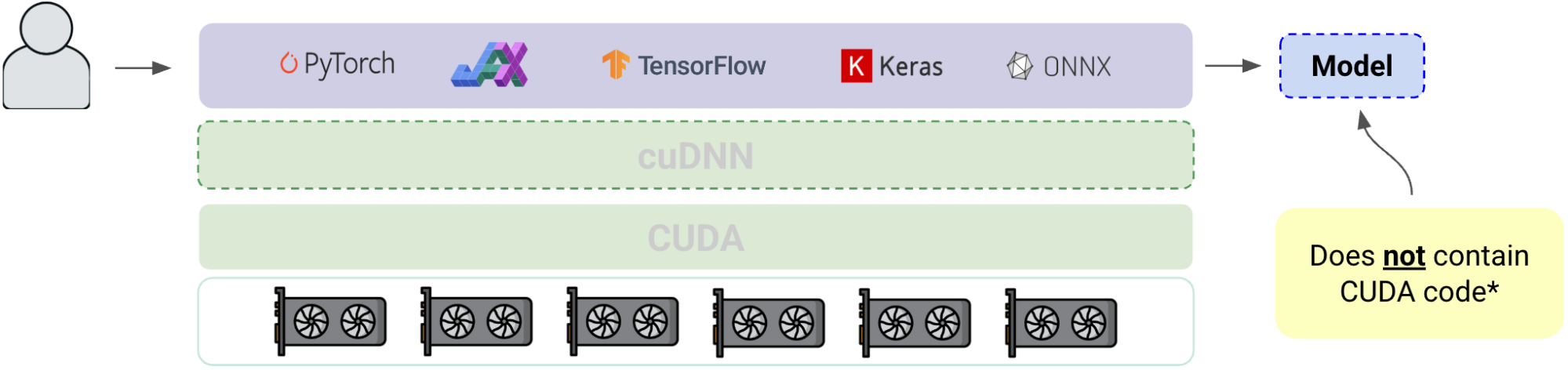
* Generically it will not contain CUDA code. Very rarely advanced customers will have models with CUDA code.
This diagram shows why CUDA feels synonymous with ML: it powers a huge amount of training compute, but developers rarely write it, read it, or ship it.
CUDA powers the training, but your model is the product. And that model? It’s completely portable.
What this means for moving from NVIDIA to SiMa.ai
You don’t need to “port CUDA.” You keep your training workflow exactly as it is and hand off a model artifact:
- Export the trained network to a standard interchange (ONNX is ideal; TorchScript and TF SavedModel also work).
- (If needed) Clean up ops with light graph surgery so everything maps to supported operators.
- Quantize & compile with Palette’s ModelSDK to generate SiMa.ai optimized kernels.
- Deploy: integrate the compiled model into an existing pipeline, or create your own pipeline using Python, C++ or Gstreamer no CUDA required.
This mirrors how many teams already deploy on non-NVIDIA targets: the framework produces a device-agnostic model; the deployment toolchain lowers it to the target hardware.
When CUDA does matter to you
There are a few edge cases where you may have to do extra work:
- Custom CUDA ops / fused kernels written by your team.
- Vendor-specific layers or plugins (e.g., TensorRT plugins) that don’t exist as portable ops.
- Tight loops in data pre/post-processing originally implemented in CUDA.For these instances, you can:
- Replace them with standard supported ops
- Implement them as supported graph patterns
- Recreate the behavior in Edgematic pre/post blocks or via a custom operator extension on SiMa.ai.
How does NVIDIA deploy to the Edge?
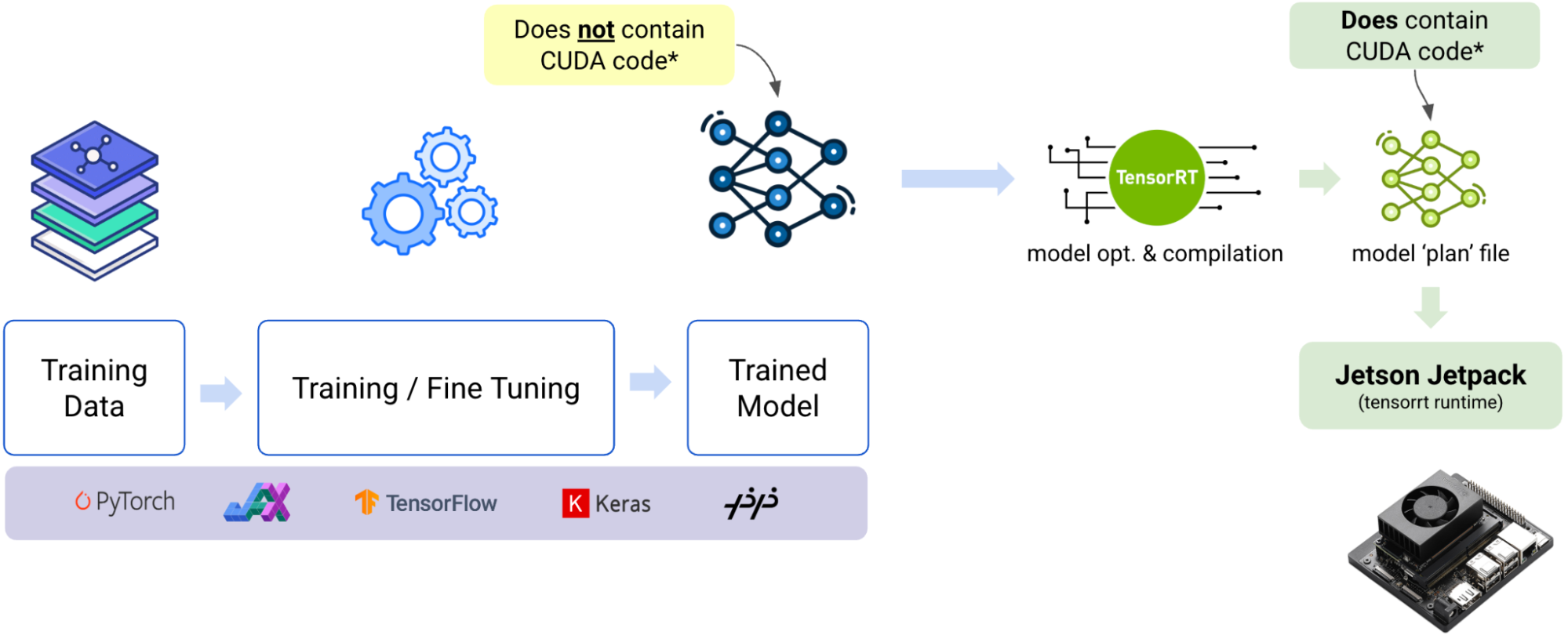
The path from trained model to edge deployment for Nvidia involves a crucial transformation. Let’s break down what actually happens.
The Three-Stage Process
- Train Your Model.
You collect training data, train and fine-tune your model, then save it. This happens in standard ML frameworks like PyTorch, JAX, TensorFlow, or Keras. The artifact you end up with, model graph plus weights, contains framework-level math operations, not CUDA code. - Export for Deployment.
Export your model to a portable format, usually ONNX or framework-specific formats like TorchScript or SavedModel. This exported model remains completely device-agnostic. - Optimize with TensorRT.
Here’s where the NVIDIA-specific optimization happens. TensorRT parses your portable model, fuses layers for efficiency, selects optimal GPU execution strategies, and optionally calibrates for INT8 precision. The output is a serialized engine file, commonly called a “.plan” file.
Think of It Like Compiling Code
This process mirrors how you’d compile C++ source code. Your C++ code is portable across architectures, but when you compile it, you get platform-specific binaries—one for x86, another for ARM. The same principle applies here: your trained model is the “source code,” and the TensorRT plan is the “compiled binary.”
What Makes TensorRT Plans Special (and Limiting)
- CUDA-Dependent: The engine requires NVIDIA GPUs and depends on CUDA/cuDNN through the TensorRT runtime.
- Version-Locked: Plans are tightly coupled to specific TensorRT versions, CUDA/driver stacks (JetPack), and GPU architectures. Upgrading JetPack or switching Jetson models often requires rebuilding the plan.
- Precision Baked-In: FP32/FP16/INT8 choices are made at build time. INT8 optimization requires calibration data and must be redone when you change models significantly.
- Opaque Format: The plan is a serialized, device-specific runtime graph, not a human-readable model description.
- Custom Components: Any TensorRT plugins or custom CUDA operations get embedded in the engine and must be available on the target device.
Deployment Reality
When you deploy on Jetson hardware, JetPack provides the complete runtime stack: TensorRT runtime, CUDA, cuDNN, and drivers. Your application (whether C++/Python or using DeepStream) loads the .plan file and executes it on the GPU.
The portable model serves as your source of truth. CI/CD pipelines typically maintain per-device, per-version build steps to generate fresh plans whenever JetPack updates roll out. Pre and post-processing code still lives in your application layer, so end-to-end performance depends heavily on how efficiently you implement the code around the optimized inference engine.
Why Teams Think They’re “Locked Into CUDA”
The confusion stems from deployment. When you take that portable model and run it on Jetson hardware, you typically pass it through TensorRT, which produces a “.plan” file, a serialized engine that is CUDA-dependent and version-locked to specific JetPack releases.
But here’s the key insight: that .plan file is not your model. It’s a compiled, optimized version of your model for NVIDIA hardware. The original model remains completely portable.
The SiMa.ai Advantage: Keep Training, Change Only Deployment
Moving from NVIDIA to SiMa.ai doesn’t require touching your training workflow. Here’s the complete migration process:

Step 1: Export Your Model (What You Already Do)
Export your trained network to ONNX (preferred), Keras, or Pytorch. This is the same portable model you’d export for any deployment target. It contains zero CUDA code.
Step 2: Compile for SiMa.ai (Instead of TensorRT)
Feed that model to SiMa’s ModelSDK, which:
- Loads and validates all operations and flags anything non-portable
- Applies quantization (PTQ or QAT) to preserve accuracy
- Optimizes and compiles kernels specifically for SiMa.ai MLSoC hardware
- Packages everything into a single .tar.gz deployment artifact
Step 3: Deploy on Palette Runtime
Deploy the compiled model using Palette and run it on the SiMa device using MLA runtime, our runtime environment that delivers deterministic latency at single-digit watts. Finally, build complete pipelines using C++, Python, Gstreamer like you would do using Jetson or develop your pipeline visually using Edgematic.
That’s it. No CUDA porting, no kernel rewrites, no architectural changes.
What’s different vs. Jetson/TensorRT
- You don’t ship a CUDA-bound plan; you ship a SiMa package that has no CUDA dependency.
- There’s no JetPack matrix to babysit. Your compiled archive targets the Palette runtime on SiMa hardware; upgrades are a straightforward re-compile, not a driver dance.
- The artifact remains cleanly separated from your app logic, so building pipelines (decode → pre → model → post → encode) is simple and reproducible.
Handling Edge Cases
About 95% of models migrate with zero friction. For the remaining 5%, here’s what might require attention:
- Custom CUDA Operators: If your team wrote custom CUDA kernels, you’ll need to replace them with standard operations or implement them as ModelSDK custom operators. This is rare and usually indicates over-engineering that can be simplified.
- TensorRT Plugins: Replace vendor-specific plugins with portable operations. Most can be expressed using standard ops that work across all platforms.
- Tight Pre/Post Processing Loops: If you implemented data processing in CUDA, move that logic to standard CPU/ARM code.
The key insight: these aren’t “CUDA dependencies”, they’re NVIDIA-specific optimizations that can be replaced with platform-agnostic alternatives.
The Migration Checklist
Ready to evaluate SiMa.ai? Here’s how to start:
Technical Assessment
- Model zoo: Export your current models to ONNX this validates portability immediately.
- Custom Operations: Identify any custom CUDA ops or TensorRT plugins that need replacement.
- Performance Requirements: Document your current batch-1 latency and throughput targets.
- Power Constraints: Measure actual power consumption vs marketing TDP numbers.
Proof of Concept
- Model Migration: Run your exported models through ModelSDK compilation.
- Accuracy Validation: Compare inference results between platforms.
- Performance Benchmarking: Test end-to-end pipeline performance, not just model kernels.
- Integration Testing: Validate your application logic works with Palette APIs.
Production Readiness
- Pipeline Development: Build complete solutions in Edgematic or using plain Gstreamer, Python or C++.
- Fleet Testing: Deploy across representative hardware configurations.
- Monitoring Integration: Connect to your existing MLOps and monitoring systems.
- Scale Planning: Validate deployment and update procedures.
The Bottom Line
You’re not locked into CUDA, you never were. Your models are portable – your training workflows don’t need to change. Migration to SiMa.ai is a deployment decision, not an architectural overhaul.
Are you ready to break free from NVIDIA’s grip on your power budget, operational complexity, and vendor dependency and switch to lower power and more economical solution?
The SiMa.ai team is here to support you and your team to achieve your goals.
Manuel Roldan
Product Manager, Software, SiMa.ai