
By Brian Dipert
Editor-In-Chief
Embedded Vision Alliance
Senior Analyst
BDTI
This article was originally published in the First Quarter 2012 issue (PDF) of the Xilinx Xcell Journal. It is reprinted here with the permission of Xilinx.
A jointly developed reference design validates the potential of Xilinx’s Zynq device in a burgeoning application category.
By Brian Dipert
Editor-In-Chief
Embedded Vision Alliance
[email protected]
José Alvarez
Engineering Director, Video Technology
Xilinx, Inc.
[email protected]
Mihran Touriguian
Senior DSP Engineer
BDTI (Berkeley Design Technology, Inc.)
[email protected]
What up-and-coming innovation can help you design a system that alerts users to a child struggling in a swimming pool, or to an intruder attempting to enter a residence or business? It’s the same technology that can warn drivers of impending hazards on the roadway, and even prevent them from executing lane-change, acceleration and other maneuvers that would be hazardous to themselves and others. It can equip a military drone or other robot with electronic “eyes” that enable limited-to-full autonomous operation. It can assist a human physician in diagnosing a patient’s illness. It can uniquely identify a face, subsequently initiating a variety of actions (automatically logging into a user account, for example, or pulling up relevant news and other information), interpreting gestures and even discerning a person’s emotional state. And in conjunction with GPS, compass, accelerometer, gyroscope and other features, it can deliver a data-augmented presentation of a scene.
The technology common to all of these application examples is embedded vision, which is poised to enable the next generation of electronic-system success stories. Embedded vision got its start in traditional computer vision applications such as assembly line inspection, optical character recognition, robotics, surveillance and military systems. In recent years, however, the decreasing costs and increasing capabilities of key technology building blocks have broadened and accelerated vision’s penetration into key high-volume markets.
Driven by expanding and evolving application demands, for example, image sensors are making notable improvements in key attributes such as resolution, low-light performance, frame rate, size, power consumption and cost. Similarly, embedded vision applications require processors with high performance, low prices, low power consumption and flexible programmability, all ideal attributes that are increasingly becoming a reality in numerous product implementation forms. Similar benefits are being accrued by latest-generation optics systems, lighting modules, volatile and nonvolatile memories, and I/O standards. And algorithms are up to the challenge, leveraging these hardware improvements to deliver more robust and reliable analysis results.
Embedded vision refers to machines that understand their environment through visual means. By “embedded,” we’re referring to any image-sensor-inclusive system that isn’t a general-purpose computer. Embedded might mean, for example, a cellular phone or tablet computer, a surveillance system, an earth-bound or flight-capable robot, a vehicle containing a 360° suite of cameras or a medical diagnostic device. Or it could be a wired or wireless user interface peripheral; Microsoft’s Kinect for the Xbox 360 game console, perhaps the best-known example of this latter category, sold 8 million units in its first two months on the market.
THE FPGA OPPORTUNITY: A CASE STUDY
A diversity of robust embedded vision processing product options exist: microprocessors and embedded controllers, application-tailored SoCs, DSPs, graphics processors, ASICs and FPGAs. An FPGA is an intriguing silicon platform for realizing embedded vision, because it approximates the combination of the hardware attributes of an ASIC—high performance and low power consumption—with the flexibility and time-to-market advantages of the software algorithm alternative running on a CPU, GPU or DSP. Flexibility is a particularly important factor at this nascent stage in embedded vision’s market development, where both rapid bug fixes and feature set improvements are the norm rather than the exception, as is the desire to support a diversity of algorithm options. An FPGA’s hardware configurability also enables straightforward design adaptation to image sensors supporting various serial and parallel (and analog and digital) interfaces.
The Embedded Vision Alliance is a unified worldwide alliance of technology developers and providers chartered with transforming embedded vision’s potential into reality in a rich, rapid and efficient manner (see sidebar). Two of its founding members, BDTI (Berkeley Design Technology, Inc.) and Xilinx, partnered to co-develop a reference design that exemplifies not only embedded vision’s compelling promise but also the role that FPGAs might play in actualizing it. The goal of the project was to explore the typical architectural decisions a system designer would make when creating highly complex intelligent vision platforms containing elements requiring intensive hardware processing and complex software and algorithmic control.
BDTI and Xilinx partitioned the design so that the FPGA fabric would handle digital signal-processing-intensive operations, with a CPU performing complex control and prediction algorithms. The exploratory implementation described here connected the CPU board to the FPGA board via an Ethernet interface. The FPGA performed high-bandwidth processing, with only metadata interchanged through the network tether. This project also explored the simultaneous development of hardware and software, which required the use of accurate simulation models well ahead of the final FPGA hardware implementation.
PHASE 1: ROAD SIGN DETECTION
This portion of the project, along with the next phase, leveraged two specific PC-based functions: a simulation model of under-development Xilinx video IP blocks, and a BDTI-developed processing application (Figure 1). The input data consisted of a 720p HD resolution, 60-frame/second (fps) YUV-encoded video stream representing the images that a vehicle’s front-facing camera might capture. And the goal was to identify (albeit not “read” using optical character recognition, although such an added capability would be a natural extension) four types of objects in the video frames as a driver-assistance scheme:
- Green directional signs
- Yellow and orange hazard signs
- Blue informational signs, and
- Orange traffic barrels
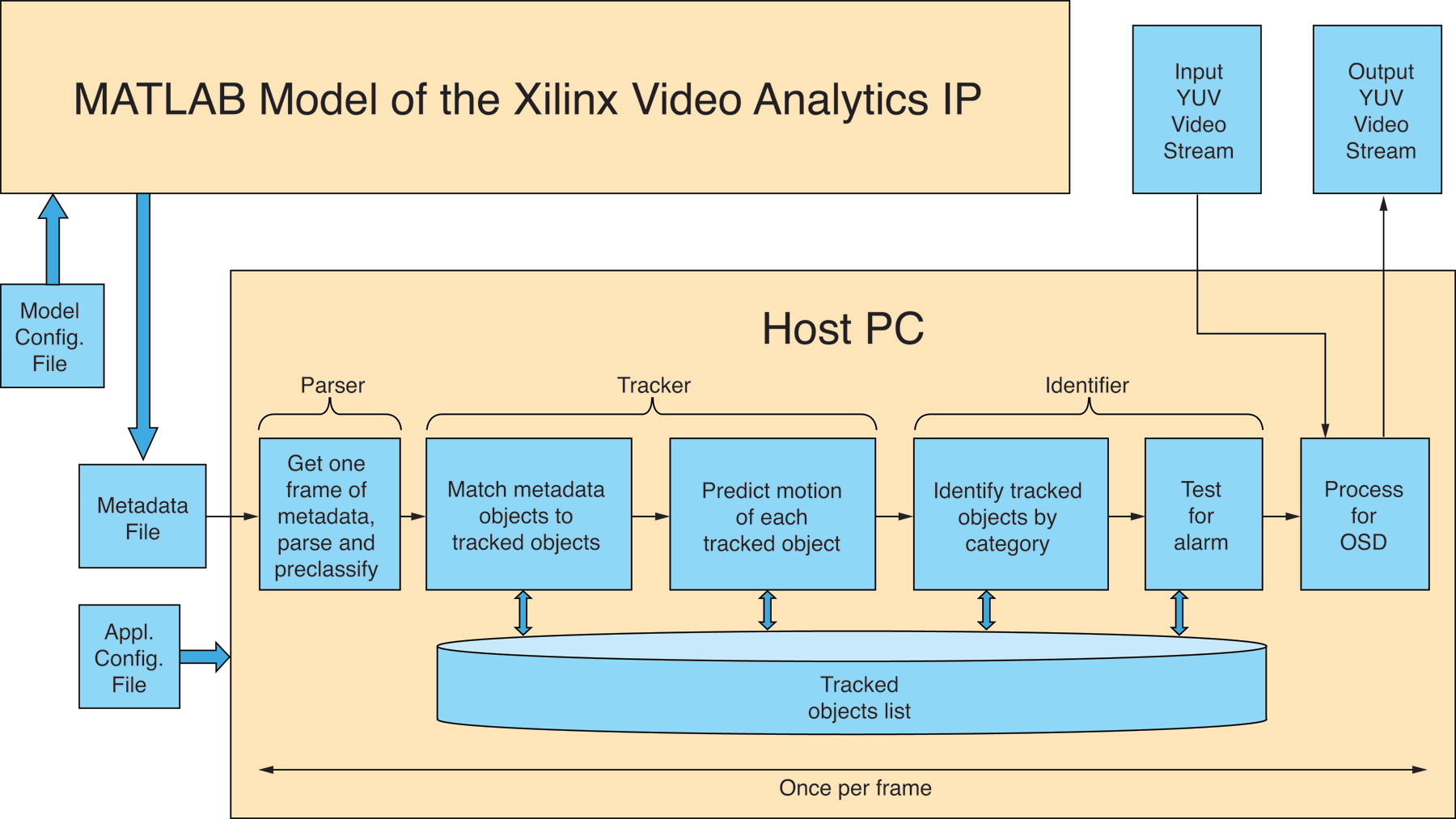
Figure 1 – The first two phases of BDTI and Xilinx’s video-analytics proof-of-concept reference design development project ran completely on a PC.
The Xilinx-provided IP block simulation models output metadata that identified the locations and sizes of various-colored groups of pixels in each frame, the very same metadata generated by the final hardware IP blocks. The accuracy of many embedded vision systems is affected by external factors such as noise from imaging sensors, unexpected changes in illumination and unpredictable external motion. The mandate for this project was to allow the FPGA hardware to process the images and create metadata in the presence of external disturbances with parsimonious use of hardware resources, augmented by predictive software that would allow for such disturbances without decreasing detection accuracy.
BDTI optimized the IP blocks’ extensive set of configuration parameters for the particular application in question, and BDTI’s postprocessing algorithms provided further refinement and prediction capabilities. In some cases, for example, the hardware was only partially able to identify the objects in one frame, but the application-layer software continued to predict the location of the object using tracking algorithms. This approach worked very well, since in many cases the physical detection may not be consistent across time. Therefore, the software intelligent layer is the key to providing consistent prediction.
As another example, black or white letters contained within a green highway sign might confuse the IP blocks’ generic image-analysis functions, thereby incorrectly subdividing the sign into multiple-pixel subgroups (Figure 2). The IP blocks might also incorrectly interpret other vehicles’ rear driving or brake lights as cones or signs by confusing red with orange, depending on the quality and setup of the imaging sensor used for the application.
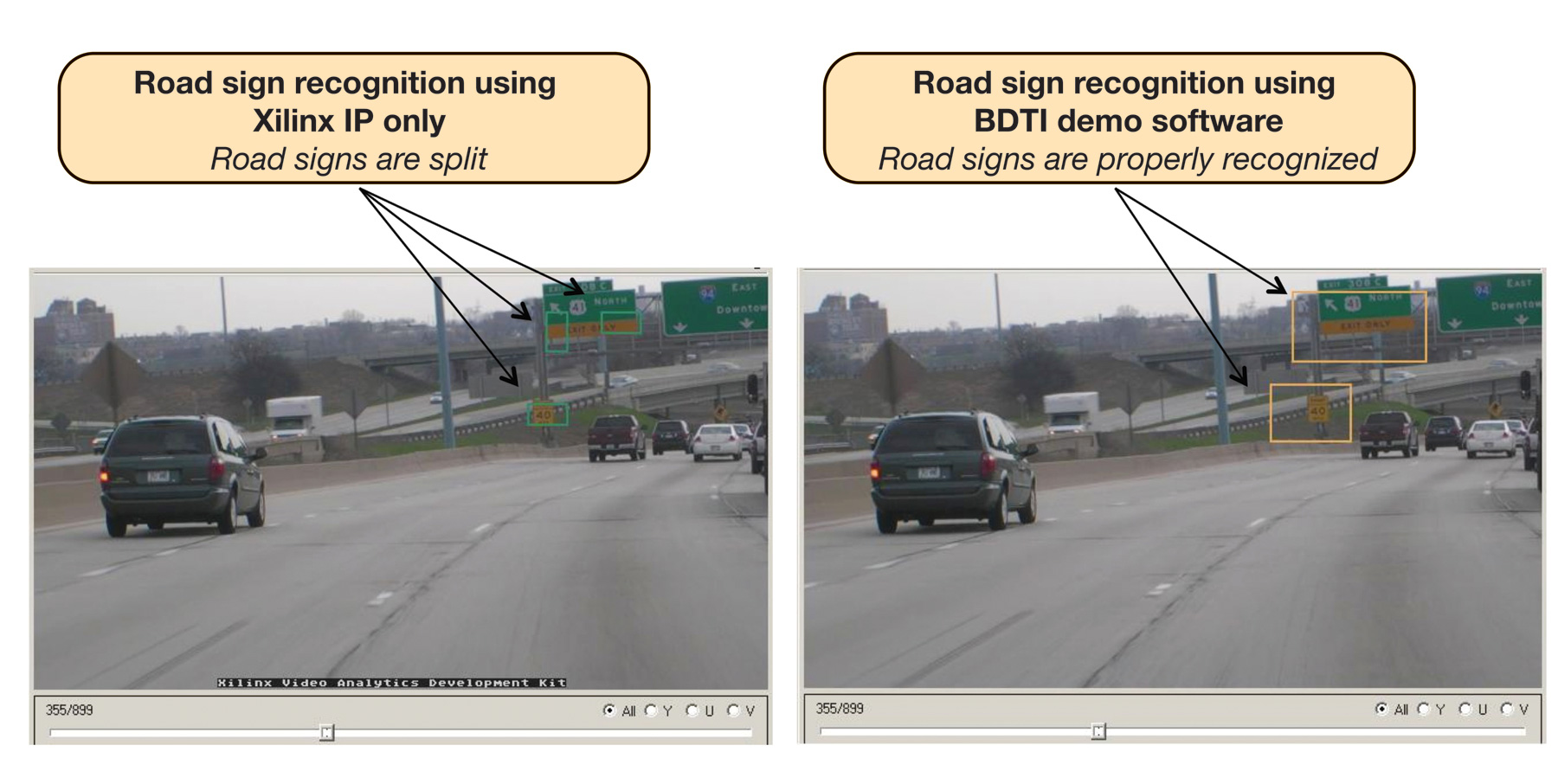
FIGURE 2- Second-level, application-tailored algorithms refined the metadata coming from the FPGA’s video-analysis hardware circuits.
The BDTI-developed algorithms therefore served to further process the Xilinx-supplied metadata in an application-tailored manner. They knew, for example, what signs were supposed to look like (size, shape, color, pattern, location within the frame and so on), and therefore were able to combine relevant pixel clusters into larger groups. Similarly, the algorithms determined when it was appropriate to discard seemingly close-in-color pixel clusters that weren’t signs, such as the aforementioned vehicle brake lights.
PHASE 2: PEDESTRIAN DETECTION AND TRACKING
In the first phase of this project, the camera was in motion but the objects (that is, signs) being recognized were stationary. In the second phase targeting security, on the other hand, the camera was stationary but objects (people, in this case) were not. Also, this time the video-analytics algorithms were unable to rely on predetermined colors, patterns or other object characteristics; people can wear a diversity of clothing, for example, and come in various shapes, skin tones and hair colors and styles (not to mention might wear head-obscuring hats, sunglasses and the like). And the software was additionally challenged with not only identifying and tracking people but also generating an alert when an individual traversed a digital “trip wire” and was consequently located in a particular region within the video frame (Figure 3).

Figure 3 – Pedestrian detection and tracking capabilities included a “trip wire” alarm that reported when an individual moved within a bordered portion of the video frame.
The phase 2 hardware configuration was identical to that of the earlier phase 1, although the software varied; a video stream fed simulation models of the video-analytics IP cores, with the generated metadata passing to a secondary algorithm suite for additional processing. Challenges this time around included:
- Resolving the fundamental trade-off between unwanted noise and proper object segmentation
- Varying object morphology (form and structure)
- Varying object motion, both person-to-person and over time with a particular person
- Vanishing metadata, when a person stops moving, for example, is blocked by an intermediary object or blends into the background pattern
- Other objects in the scene, both stationary and in motion
- Varying distance between each person and the camera, and
- Individuals vs. groups, and dominant vs. contrasting motion vectors within a group
With respect to the “trip wire” implementation, four distinct video streams were particularly effective in debugging and optimizing the video-analytics algorithms:
- “Near” pedestrians walking and reversing directions
- “Near” pedestrians walking in two different directions
- A “far” pedestrian with a moving truck that appeared, through a trick of perspective, to be of a comparable size, and
- “Far” pedestrians with an approaching truck that appeared larger than they were
PHASE 3: HARDWARE CONVERSIONS AND FUTURE EVOLUTIONS
The final portion of the project employed Xilinx’s actual video-analytics IP blocks (in place of the earlier simulation models), running on the Spartan®-3A 3400 Video Starter Kit. A MicroBlaze™ soft processor core embedded within the Spartan-3A FPGA, augmented by additional dedicated-function blocks, implemented the network protocol stack. That stack handled the high-bit-rate and Ethernet-packetized metadata transfer to the BDTI-developed secondary processing algorithms, now comprehending both road sign detection and pedestrian detection and tracking. And whereas these algorithms previously executed on an x86-based PC, BDTI successfully ported them to an ARM® Cortex™-A8-derived hardware platform called the BeagleBoard (Figure 4).
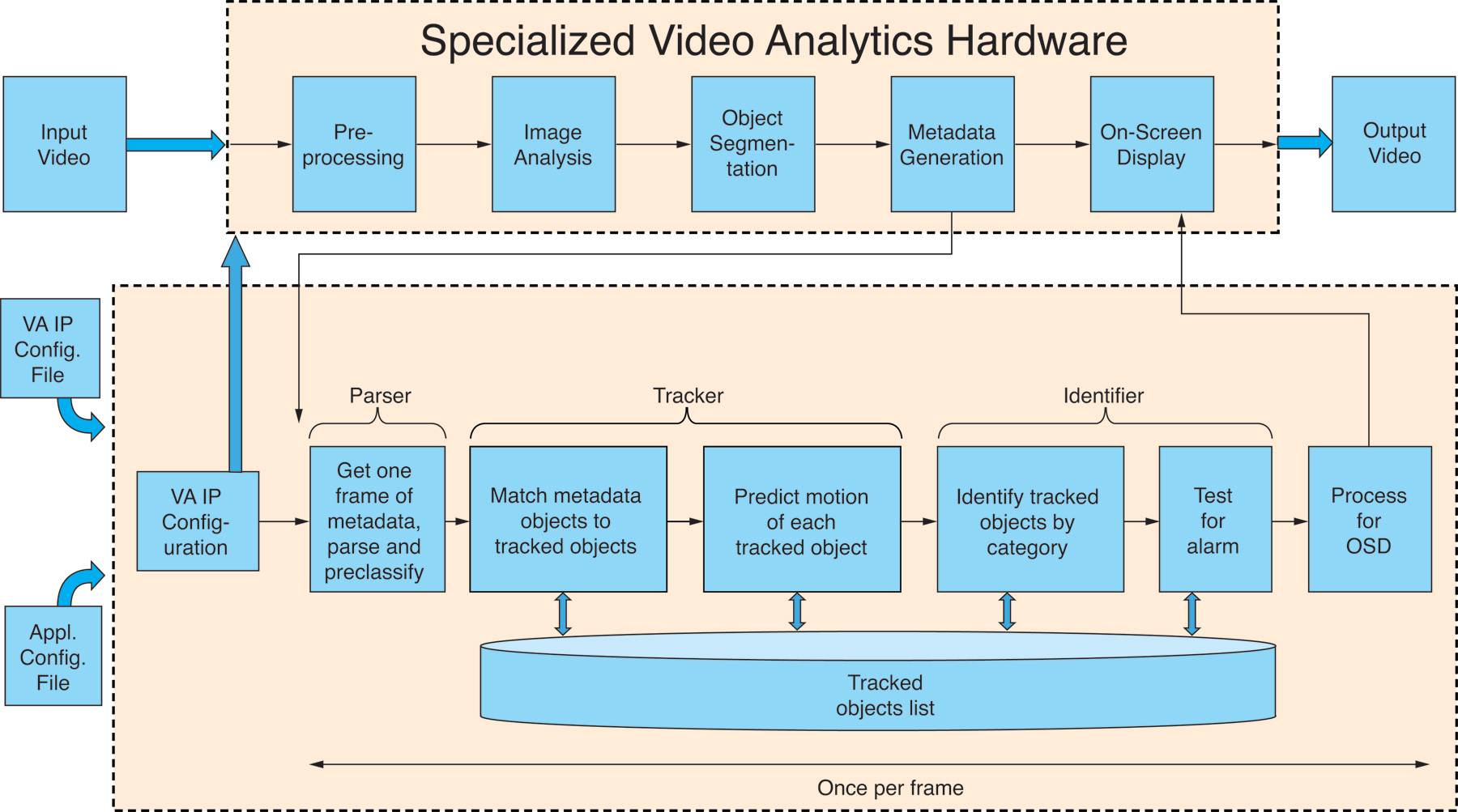
Figure 4 – The final phase of the project migrated from Xilinx’s simulation models to actual FPGA IP blocks. BDTI also ported the second-level algorithms from an x86 CPU to an ARM-based SoC, thereby paving the path for the single-chip Zynq Extensible Processing Platform successor.
Embedded vision is poised to become the next notable technology success story for both systems developers and their semiconductor and software suppliers. As the case study described in this article suggests, FPGAs and FPGA-plus-CPU SoCs can be compelling silicon platforms for implementing embedded vision processing algorithms.
SIDEBAR: EMBEDDED VISION ALLIANCE SEES SUCCESS
Embedded vision technology has the potential to enable a wide range of electronic products that are more intelligent and responsive than before, and thus more valuable to users. It can add helpful features to existing products. And it can provide significant new markets for hardware, software and semiconductor manufacturers. The Embedded Vision Alliance, a unified worldwide organization of technology developers and providers, will transform this potential into reality in a rich, rapid and efficient manner.
The alliance has developed a full-featured website, freely accessible to all and including (among other things) articles, videos, a daily news portal and a multi-subject discussion forum staffed by a diversity of technology experts. Registered website users can receive the alliance’s monthly e-mail newsletter; they also gain access to the Embedded Vision Academy, containing numerous tutorial presentations, technical papers and file downloads, intended to enable new players in the embedded vision application space to rapidly ramp up their expertise.
Other envisioned future aspects of the alliance’s charter may include:
- The incorporation, and commercialization, of technology breakthroughs originating in universities and research laboratories around the world,
- The codification of hardware, semiconductor and software standards that will accelerate new technology adoption by eliminating the confusion and inefficiency of numerous redundant implementation alternatives,
- Development of robust benchmarks to enable clear and comprehensive evaluation and selection of various embedded vision system building blocks, such as processors and software algorithms, and
- The proliferation of hardware and software reference designs, emulators and other development aids that will enable component suppliers, systems implementers and end customers to develop and select products that optimally meet unique application needs.
For more information, please visit www.embedded-vision.com. Contact the Embedded Vision Alliance at [email protected] and (510) 451-1800.