Computers can learn a lot about a person from their face – even if they don’t uniquely identify that person. Assessments of age range, gender, ethnicity, gaze direction, attention span, emotional state and other attributes are all now possible at real-time speeds, via advanced algorithms running on cost-effective hardware. This article provides an overview of the facial analysis market, including size and types of applications. It then discusses the facial analysis capabilities possible via vision processing, along with the means of implementing these functions, including the use of deep learning. It also introduces an industry alliance available to help product creators incorporate robust facial analysis capabilities into their vision designs.
Before you can analyze a face, you first must find it in the scene (and track it as it moves). Once you succeed, however, you can do a lot. With gaze tracking, for example, you're able to determine which direction a person is looking at any particular point in time, as well as more generally ascertain whether their eyes are closed, how often they blink, etc. Using this information, you can navigate a device's user interface by using only the eyes, a function with both flashy (gaming) and practical (medical, for example, for patients suffering from paralysis) benefits. You can also log a person's sleep patterns. You can ascertain whether a driver is dozing off or otherwise distracted from paying attention to the road ahead. And you can gain at least a rudimentary sense of a person's mental and emotional state.
Speaking of emotion discernment, plenty of other facial cues are available for analysis purposes. They include the color and pattern of the skin (both at any particular point in time and as it changes over time), the presence of a smile or a frown, the location, amount, and intensity of wrinkles, etc. The camera you're designing, for example, might want to delay tripping the shutter until the subject has a grin on his or her face. If a vehicle driver is agitated, you might want to dial up the autonomous constraints on his or her compulsions. A person's emotional state is also valuable information in, say, a computer game. And the retail sales opportunity to tailor the presentation of products, promotions, etc. is perhaps obvious.
In fact, retail is one of many key opportunities for yet another major facial analysis function: audience classification. How old is someone? What's their gender? Ethnicity? Real-time identification of a particular individual may not yet be feasible, unless the sample size is fairly small and pre-curated (as with social media networks) or you're the National Security Agency or another big-budget law enforcement agency. But the ability to categorize and "bin" the customers that enter your store each day, for example, is already well within reach.
In all of these facial analysis use cases, various vision processing architecture alternatives (local, locally connected, "cloud", and combinations of these in a heterogeneous computing approach) are possible, along with diversity in the algorithms that those processors will be running and the 2-D and 3-D cameras that will capture the source images to be analyzed. And performance, power consumption, cost, size and weight are all key considerations to be explored and traded off as needed in any particular implementation.
Market Status and Forecasts
Face recognition technology has been widely used in security applications for many years, although it was thrust into the public spotlight after the 9/11 attacks. The FBI database, for example, supposedly now contains more than 400 million images. Broader facial analysis technology has found applications beyond security and surveillance with the emergence of new algorithms, which enable users to extract a wide range of additional information about facial features, such as skin color and texture, gender, eye gaze, and emotional state. This information is widely being used by the business sector, especially within the healthcare, retail, and transportation industries.
Facial analysis has been extensively developed in academic and research lab settings for some time now, and the quality of its results has improved significantly in recent years. Recognition algorithms can be divided into two main approaches: geometric and photometric. The geometric approach looks at distinguishing features and tries to recognize various aspects of a face. In contrast, the photometric approach statistically converts an image into values and then compares these values with a template in order to maximize a match.
Three-dimensional (3D) image capture can improve the accuracy of facial analysis. This technique uses depth-discerning sensors to capture information about the shape of a face. The information is then used to identify distinctive features, such as the contour of the eye sockets, nose, and chin. 3D imaging typically costs more to implement than conventional 2D imaging, due to the more exotic sensors required, and is also more computationally intensive due to the added complexity of the associated algorithms.
Facial recognition suffers from the typical challenges of any computer vision technology. Poor lighting and environmental conditions, sunglasses, and long hair or other objects partially covering the subject’s face can make analysis difficult. Image resolution, color depth and other quality metrics also play a significant role in facial analysis success. In addition, the face naturally changes as a subject ages. The algorithm must “learn” these changes and then apply appropriate adjustments in order to prevent false-positive matches.
The facial biometrics market, which includes both conventional facial analysis and facial thermography (the measurement of the amount of infrared energy emitted, transmitted, and reflected by various areas of the face, which is subsequently displayed as a subject-unique image of temperature distribution), is still relatively young. Tractica’s market analysis indicates that the sector accounted for $149 million in 2015. Tractica forecasts that the market for facial biometrics will reach $882 million by 2024, representing a compound annual growth rate (CAGR) of 21.8% (Figure 1). Cumulative revenue for the 10-year period 2015 and 2024 will reach $4.9 billion. Facial analysis technologies represent 57% of the market opportunity during this period, with facial thermography accounting for the balance.
Figure 1. Forecasted worldwide and regional revenue growth (USD) for facial biometrics (courtesy Tractica).
A wide range of emerging applications is driving the forecasted revenue growth. For instance, facial analysis technology has gained significant traction in the retail industry. Applications here include customer behavior analysis, operations optimization, and business intelligence. Facial recognition techniques can be used, for example, to identify a person entering a store. If the person is identified as a frequent visitor, he or she is given preferred treatment. More generally, by analyzing the direction of a person’s gaze, facial analysis technology can analyze the effectiveness of various marketing campaigns. And by identifying customer attributes such as age range, gender, and ethnicity, facial analysis enables retail stores to gain valuable business intelligence.
The financial and gaming markets can use facial recognition technology to identify persons of interest. At an automated teller machine (ATM), for instance, it can be used to identify whether or not the account owner is the person currently accessing the account. Casinos can use it to identify VIP customers as well as troublemakers. Hospitals are using facial recognition systems to detect patient identity theft. Facial detection, analysis and recognition algorithms are also being deployed in intelligent surveillance cameras, capable of tracking individuals as they move as well as identifying known "friendly" persons (family members, etc.). Such capabilities provide manufacturers with significant market differentiators.
Tractica forecasts the top 20 use cases for facial analysis, in terms of cumulative revenue during the period from 2015 to 2024 (Table 1). The top industry sectors for facial recognition, in order of cumulative revenue opportunity during the 2015-2024 forecast period, are:
- Consumer
- Enterprise
- Government
- Finance
- Education
- Defense
- Retail
- NGOs (non-governmental organizations)
- Law Enforcement
|
Rank |
Use Case |
Revenue (2015-2024) ($M USD) |
|
1 |
Consumer Device Authentication |
2,358.67 |
|
2 |
Identifying Persons of Interest |
1,057.30 |
|
3 |
Time and Attendance |
308.60 |
|
4 |
Cashpoint/ATM |
201.04 |
|
5 |
Visitor Access |
198.51 |
|
6 |
Border Control (entry/exit) |
197.07 |
|
7 |
Physical Building Access |
139.46 |
|
8 |
De-duplication |
77.19 |
|
9 |
Online Courses |
60.84 |
|
10 |
National ID Cards |
51.04 |
|
11 |
Biometrics Passports |
43.53 |
|
12 |
Demographic Analysis/Digital Signage |
38.88 |
|
13 |
Mobile Banking – High Value 2nd Factor |
38.53 |
|
14 |
Border Control (on bus, etc.) |
31.16 |
|
15 |
Point of Sale Payment |
29.18 |
|
16 |
Aid Distribution/Fraud Reduction |
21.29 |
|
17 |
Fraud Investigation |
13.35 |
|
18 |
Healthcare Tracking |
10.63 |
|
19 |
Voter Registration/Tracking |
4.34 |
|
20 |
Benefits Enrollment (proof of life) |
2.80 |
|
|
Total |
4,883.41 |
Table 1. Cumulative facial analysis revenue by use case, world markets: 2015-2024 (courtesy Tractica).
Facial analysis technology still has a long way to go before it will realize its full potential; applications beyond security are only beginning to emerge. Tractica believes that facial recognition will find its way into many more applications as accuracy steadily improves, along with camera resolution and other image quality metrics.
Audience Classification
Facial classification (age, gender, ethnicity, etc.) approaches typically follow a four-step process flow: detection, normalization, feature extraction, and classification (Figure 2). Identifying the region of the input image that contains the face, and then isolating it, is an important initial task. This can be accomplished via face landmark detection libraries such as CLandmark and flandmark; these accurate and memory efficient real-time implementations are suitable for embedded systems.
Figure 2. Facial classification encompasses a four-step process flow.
Deep learning training (and subsequent inference) techniques with annotated datasets such as CNNs (convolutional neural networks), which will be further discussed in the next section, can also find use. In such cases, however, implementers need to comprehend and account for any biases present in the training datasets, such as possible over-representation of certain ethnicities as well as over-representation of adults versus children.
Some classification methods benefit from the alignment of the face into an upright canonical pose; this can be achieved by first locating the eyes and then rotating the face image in-plane to horizontally align the eyes. Cropping the area of the image that contains face(s) and resizing these to a specific size for further analysis is often then required. Generally, the various methods are sensitive to face illumination; varying the illumination angle or intensity of a scene can notably alter classification results.
The extracted and normalized face images then undergo a series of preprocessing steps, generated by various filters and with various effects, to prepare the images for feature extraction (Figure 3). Binarization followed by segmentation, for example, can be used to remove unnecessary background information as well as highlight feature zones such as eyebrows, the nose and lips. Gaussian blur/smoothing can be used to remove noise from the image. And the Sobel edge filter can be used to emphasize edges of lines in the face, useful in determining age based on the magnitude of wrinkles in areas where they're commonly found.
Figure 3. Pre-processing filters (and their effects) can be useful in emphasizing and understating various facial features.
After pre-processing comes feature extraction. Typically the eyes, brows, nose and mouth are associated with the most important facial features regions. Additional information can also be extracted from secondary features such as the shape of the hairline, the cheeks and the chin, in order to further classify the images into more specific "bins." Gender classification is based on observed differences and variations of the shape and characteristics of various facial features (Table 2). And age classification can be determined from the ratios of measurements of various facial features, as well as from the variety of wrinkles in the cheeks, forehead and eye regions (which become more pronounced as people age).
Table 2. Gender-based feature characteristics.
Classification is done in steps, typically in a "tree" approach. Discriminating the age range after initially determine gender often works well, since facial structure differences between genders frequently exist. Middle-aged males and females often don't show the same facial aging signs, for example, due to females' better skin care habits. Differences in cranial structures and skin colors among various ethnic groups may also influence the results; a tree with a "parent" classification for ethnicity prior to tackling classifications for gender and age may further improve overall results (Figure 4).
Figure 4. Discriminative demographics classification can improve accuracy for "child" classes.
Video-based classification is more challenging than still-image-based techniques, since video sequences can lead to misclassifications due to frame-to-frame variations in head pose, illumination, facial expressions, etc. In these cases, a temporal majority-voting approach to making classification decisions for a partially tracked face across multiple frames can find use in stabilizing the results, until more reliable frame-to-frame tracking is restored.
Emotion Discernment
Identify emotions is a basic skill learned by humans at an early age and critical to successful social interactions. Most of the time, for most people, a quick glance at another person’s face is sufficient to accurately recognize commonly expressed emotions such as anger, happiness, surprise, disgust, sadness, and fear. Transferring this skill to a machine, however, is a complex task. Researchers have devoted decades of engineering time to writing computer programs that recognize a particular emotion feature with reasonable accuracy, only to have to start over from the beginning in order to recognize a slightly different feature.
But what if instead of programming a machine, you could teach it to recognize emotions with great accuracy? Deep learning techniques are showing great promise in lowering error rates for computer vision recognition and classification, while simultaneously simplifying algorithm development versus traditional approaches. Implementing deep neural networks in embedded systems can give machines the ability to visually interpret facial expressions with near-human levels of accuracy.
A neural network, which can recognize patterns, is considered "deep" if it has at least one hidden middle layer in addition to the input and output layers (Figure 5). Each node is calculated from the weighted inputs sourced from multiple nodes in the previous layer. These weighting values can be adjusted to perform a specific image recognition task, in a process known as neural network training.

Figure 5. A neural network is considered "deep" if it includes at least one intermediary "hidden" layer.
To teach a deep neural network to recognize a person expressing happiness, for example, you first present it with a collection of images of happiness as raw data (image pixels) at its input layer. Since it knows that the result should be happiness, the network recognizes relevant patterns in the picture and adjusts the node weights in order to minimize the errors for the "happiness" class. Each new annotated image showing happiness further refine the weights. Trained with enough inputs, the network can then take in an unlabeled image and accurately analyze and recognize the patterns that correspond to happiness, in a process called inference or deployment (Figure 6).
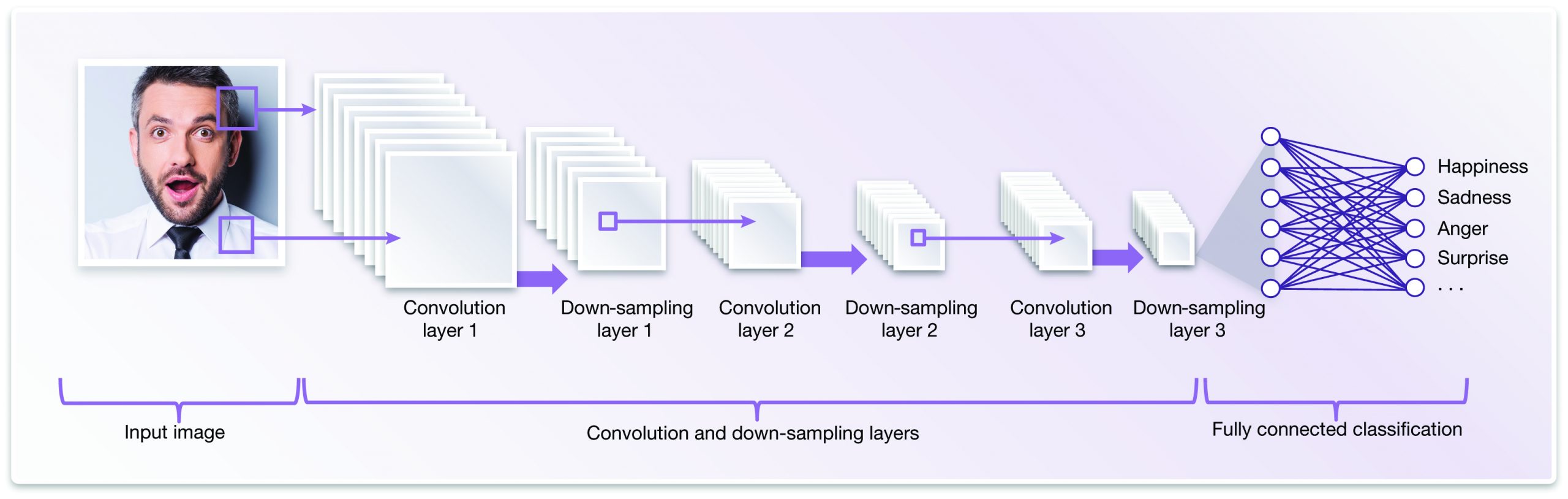
Figure 6. After being initially (and adequately) trained via a set of pre-annotated images, a CNN (convolutional neural network) or other deep learning architecture is then able to accurately classify emotions communicated via new images' facial expressions.
The training phase leverages a deep learning framework such as Caffe or TensorFlow, and employs CPUs, GPUs, FPGAs or other specialized processors for the training calculations and other aspects of framework usage (Figure 7). Frameworks often also provide example graphs that can be used as a starting point for training. Deep learning frameworks also allow for graph fine-tuning; layers may be added, removed or modified to achieve improved accuracy.
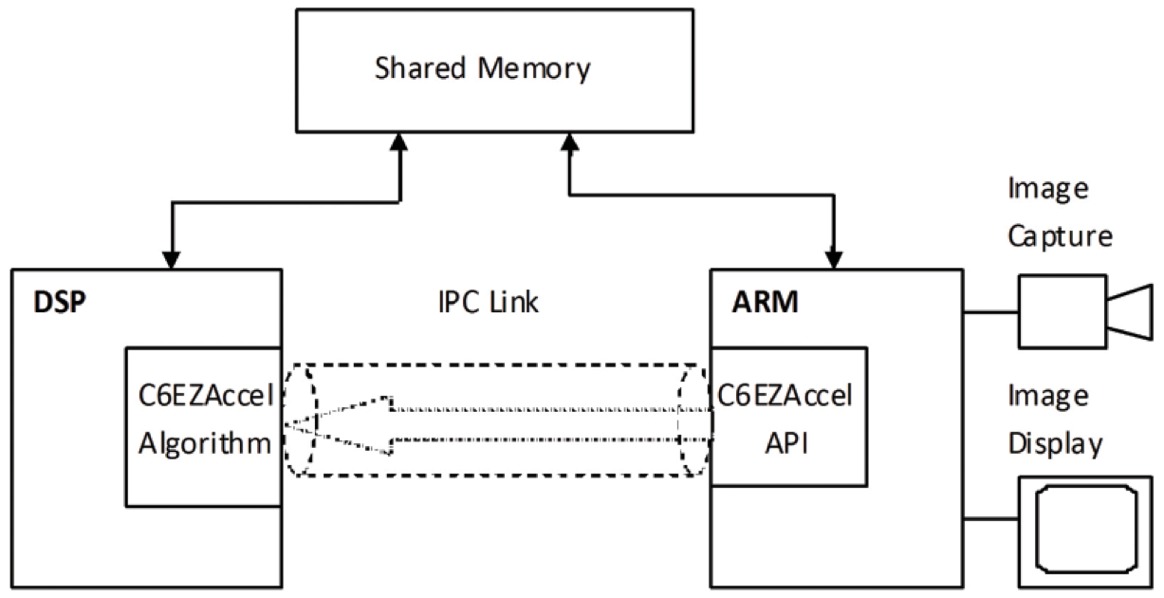
Figure 7. Deep learning frameworks provide a training starting point, along with supporting layer fine-tuning to optimize classification outcomes.
Deep neural networks require a lot of computational horsepower for training, in order to calculate the weighted values of the numerous interconnected nodes. Adequate-capacity and –bandwidth memory, the latter a reflection of frequent data movement during training, are also important. CNNs are the current state-of-the art deep learning approach for efficiently implementing facial analysis and other vision processing functions. CNN implementations can be efficient, since they tend to reuse a high percentage of weights across the image and may take advantage of two-dimensional input data structures in order to reduce redundant computations.
One of the biggest challenges in the training phase is finding a sufficiently robust dataset to "feed" the network. Network accuracy in subsequent inference (deployment) is highly dependent on the distribution and quality of the initial training data. For facial analysis, options to consider are the emotion-annotated public dataset from FREC (the Facial Expression Recognition Challenge) and the multi-annotated proprietary dataset from VicarVision.
The inference/deployment phase can often be implemented on an embedded CPU, potentially in conjunction with a DSP, vision or CNN processor or other heterogeneous co-processor, and/or dedicated-function hardware pipelines (Figure 8). If a vision-plus-CNN coprocessor combination is leveraged, for example, the scalar unit and vector unit are programmed using C and OpenCL C (for vectorization), but the CNN engine does not require specific programming. The final graph and weights (coefficients) from the training phase can feed into a CNN mapping tool, with the embedded vision processor’s CNN engine then configured and ready to execute facial analysis tasks.
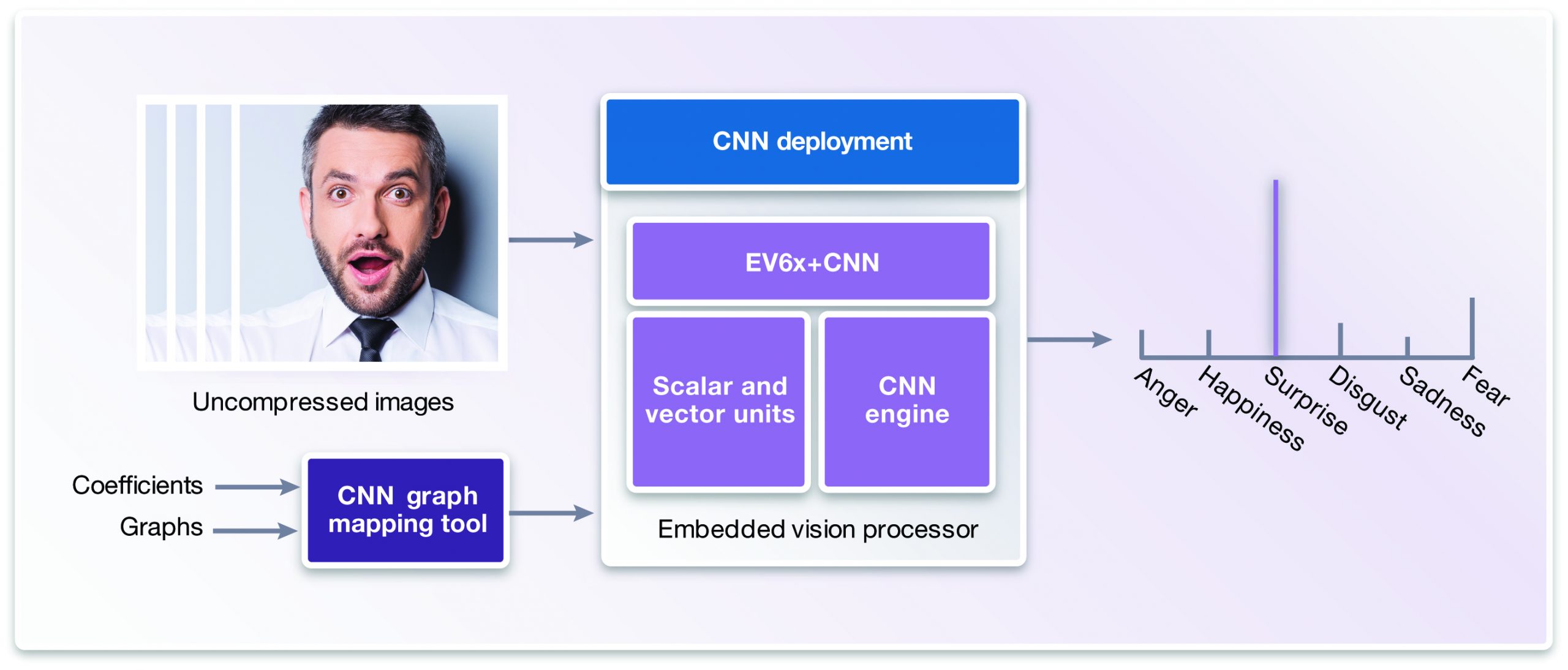
Figure 8. Post-training, the deep learning network inference (deployment) phase is the bailiwick of an embedded processor. Heterogeneous coprocessors, if available, efficiently tackle portions of the total calculation burden.
It can be difficult for the CNN to deal with significant variations in lighting conditions and facial poses, as was previously discussed regarding audience classification; here too, pre-processing of the input images to make the faces more uniform can deliver notable accuracy benefits. Heterogeneous multi-core processing architectures enable, for example, a CNN engine to classify one image while the vector unit simultaneously preprocesses (light normalization, image scaling, plane rotation, etc.) the next image…all at the same time that the scalar unit is determining what to do with the CNN detection results. Image resolution, frame rate, number of graph layers and desired accuracy all factor into the number of parallel multiply-accumulations needed and overall performance requirements.
Gaze Tracking and Other Implementation Details
By combining previously discussed deep learning advances with powerful computational imaging algorithms, very low false-acceptance rates for various facial analysis functions are possible. The analysis execution time can be shortened, and accuracy boosted, not only by proper network training prior to inference but also by programming facial templates to improve scalability, and by integrating various computer vision-based face tracking and analysis technologies. FotoNation, for example, has in its various solutions standardized on 12×12 pixel clusters to detect a face, along with recommending a minimum of 50 pixels' spacing between the eyes.
Leading-edge feature detection technologies examine 45 or more landmarks in real-time video, along with over 60 landmarks in a still image, in order to decipher facial features with high confidence. These features can also be detected in diverse orientations, ranging from +/-20° yaw and +/-15° pitch. Achieving adequate performance across diverse lighting conditions is also a major challenge that must be overcome in a robust facial analysis solution. And full-featured facial analysis approaches also support related technologies such as eye/gaze tracking and liveliness detection.
The integration of head and eye position, for example, will facilitate locating and tracking the gaze in the scene, even in cases where the eyes aren't encased in an enclosure free of interfering ambient light (such as a virtual reality headset) and more challenging bright-pupil tracking algorithms must therefore find use. Liveliness detection technology determines whether the frame contains a real person or a high-resolution photograph. Its algorithm takes into account both any motion of the facial features and the skin's reflections. The integration of all these technologies results in rapid and high-reliability facial analysis that's sufficiently robust to overcome even occlusions caused, for example, by wearing glasses.
Conclusion
Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products. And it can provide significant new markets for hardware, software and semiconductor suppliers (see sidebar "Additional Developer Assistance"). Facial analysis in its various implementations discussed in this article – audience classification, emotion discernment, gaze tracking, etc. – is relevant and appealing to an ever-increasing set of markets and applications. And as the core technologies continue to advance, response-time and accuracy results will improve in tandem, in the process bringing the "holy grail" of near-instantaneous unique-individual identification ever closer to becoming a reality for the masses.
Sidebar: Additional Developer Assistance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision processing into reality. FotoNation, NXP and Synopsys, three of the co-authors of this article, are members of the Embedded Vision Alliance; Tractica is a valued partner organization. The Embedded Vision Alliance's mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV, along with Caffe, TensorFlow and other deep learning frameworks. Access is free to all through a simple registration process.
The Embedded Vision Alliance’s annual technical conference and trade show, the Embedded Vision Summit, will be held May 1-3, 2017 at the Santa Clara, California Convention Center. Designed for product creators interested in incorporating visual intelligence into electronic systems and software, the Summit provides how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. The Summit is intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings. Online registration and additional information on the 2017 Embedded Vision Summit are now available.
By Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Durga Peddireddy,
Director of Product Management, FotoNation Limited (a subsidiary of Tessera Holding Corporation)
Ali Osman Ors
Senior R&D Manager, NXP Semiconductors
Gordon Cooper
Product Marketing Manager, Synopsys
Anand Joshi
Principal Analyst, Tractica