This technical article was originally published at Synopsys' website. It is reprinted here with the permission of Synopsys.
Embedded vision solutions will be a key enabler for making automobiles fully autonomous. Giving an automobile a set of eyes – in the form of multiple cameras and image sensors – is a first step, but it also will be critical for the automobile to interpret content from those images and react accordingly. To accomplish this, embedded vision processors must be hardware optimized for performance while achieving low power and small area, have tools to program the hardware efficiently, and have algorithms to run on these processors.
The significant automotive safety improvements in the past (e.g., shatter-resistant glass, three-point seatbelts, airbags), were passive safety measures designed to minimize damage during an accident. We now have technology that can actively help the driver avoid crashing in the first place. Advanced Driver Assistance Systems (ADAS) will help autonomous vehicles become a reality. Blind spot detection can alert a driver as he or she tries to move into an occupied lane. Lane departure warning and Lane Keep Aid alerts the driver if the car is drifting outside its lane and actively steers the car back into their own lane. Pedestrian detection notifies the driver that pedestrians are in front or behind the car and Automatic Emergency Braking applies the brakes to avoid an accident or pedestrian injury. As ADAS features are combined, we get closer to autonomous vehicles—all enabled by high-performance vision processing.
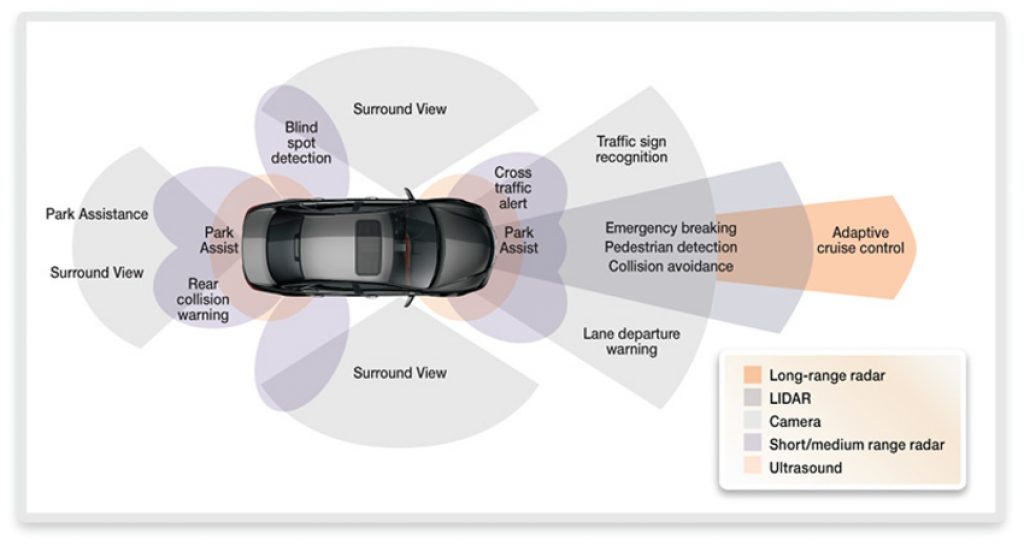
Auto manufacturers are including more cameras in their cars, as shown in Figure 1. A front facing camera can detect pedestrians or other obstacles and with the right algorithms, assist the driver in braking. A rear-facing camera – mandatory in the United States for most new vehicles starting in 2018 – can save lives by alerting the driver to objects behind the car, out of the driver’s field of view. A camera in the cars cockpit facing the driver can identify and alert for distracted driving. And most recently, adding four to six additional cameras can provide a 360-degree view around the car.
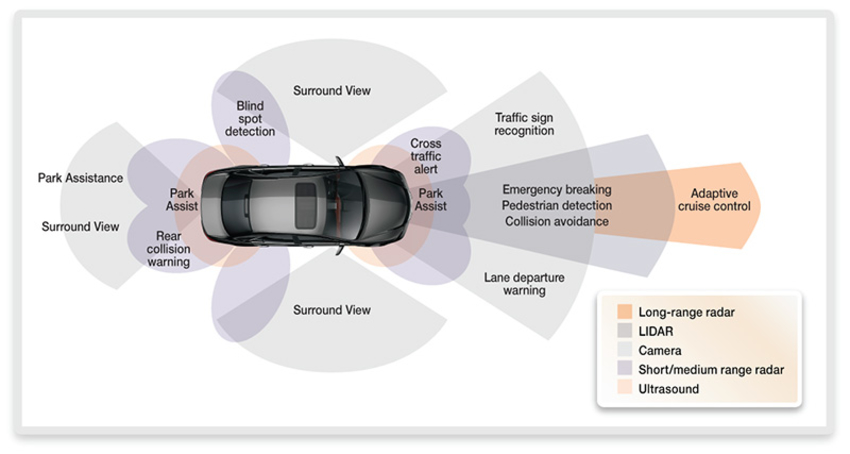
Figure 1: Cameras, enabled by high-performance vision processors, can "see" if objects are not in the expected place
Vision Processors for Object Detection
Since the driver is already facing forward, a front facing camera may seem unnecessary. So, to be of value, the front facing camera has to be consistently faster than the driver in detecting and alerting for obstacles. While an ADAS system can physically react faster than a human driver, it needs embedded vision to provide real-time analysis of the streaming video and know what to react to.
Vision processors are based on heterogeneous processing units. That means the programming tasks are divided into processing units with different strengths (Figure 2). Most of the code will be written using C or C++ for a traditional 32-bit scalar processor, which provides an easy-to-program processor. The vector DSP unit will perform most of the computations, because its very large instruction word can handle a lot of parallel computations for pixel processing of each incoming image.
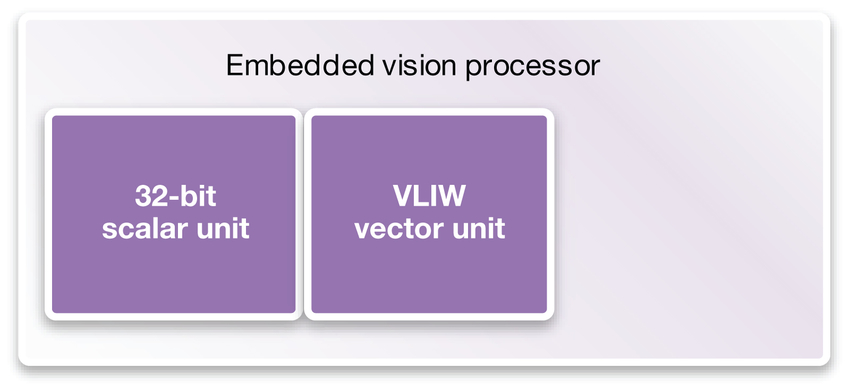
Figure 2: Vision processors are based on heterogeneous processing units, including scalar and Very Long Instruction Word (VLIW) vector DSP units
Detecting a pedestrian in front of a car is part of a broad class of “object detection.” For each object to be detected, traditional computer vision algorithms were hand-crafted. Examples of algorithms used for detection include Viola-Jones and more recently Histogram of Oriented Gradients (HoG). The HOG algorithm looks at the edge directions within an image to try to describe objects. HOG was considered a state-of-the art for pedestrian detection as late as 2014.
Emergence of Deep Learning for Object Detection
Although the concept of neural networks, which are computer systems modeled after the brain, have been around for a long time, only recently have semiconductors achieved the processor performance to make them a practical reality. In 2012, a convolutional neural network (CNN)-based entry into the annual ImageNet competition showed a significant improvement in accuracy in the task of image classification over the traditional computer vision algorithms. Because of the improved accuracy, the use of neural network-based techniques for image classification, detection and recognition have been gaining momentum ever since.
The important breakthrough of deep neural networks is that object detection no longer has to be a hand-crafted coding exercise. Deep neural networks allow features to be learned automatically from training examples. A neural network is considered to be “deep” if it has an input and output layer and at least one hidden middle layer. Each node is calculated from the weighted inputs from multiple nodes in the previous layer. CNNs are the current state-of-the art for efficiently implementing deep neural networks for vision. CNNs are more efficient because they reuse a lot of weights across the image.
Early CNNs in the embedded space were performed using a GPU or using the vector DSP portion of a vision processor. However, it’s helpful to look at the task performed in terms of three different heterogeneous processing units, as shown in Figure 3.
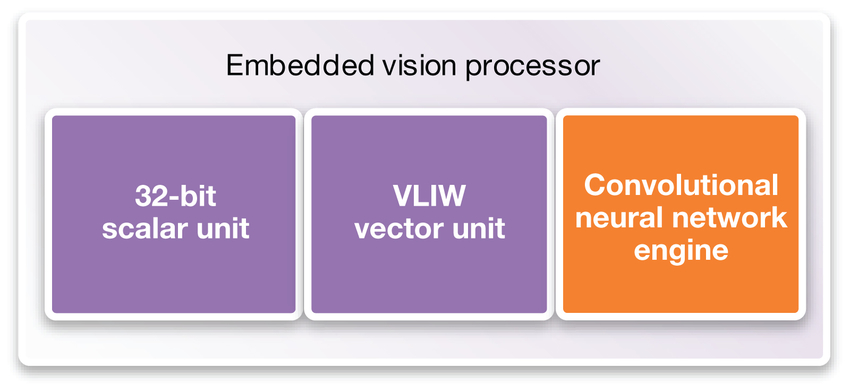
Figure 3: Adding a CNN engine to an embedded vision processor enables the system to learn through training
Early implementations of CNNs in hardware had a limited number of Multiply-Accumulator (MAC) units. For example, Synopsys’s EV5x, the industry’s first programmable and configurable vision processor IP cores implemented a CNN engine with 64 MACs. Running at 500 MHz, the EV5x could produce 32 GMACs/s or 64 GOPs/s of performance (a multiply-accumulator performs two operations in one instruction). That was not enough performance to process an entire 1MP (1280 x 1024) frame or image. However, it was enough processing power to perform a CNN on a portion of the image (say a 64×64 pixel patch). To process the entire image, a two-step process for pedestrian detection was needed. The vector DSP would perform a computationally intensive Region of Interest (ROI) algorithm on each incoming image of the video stream. ROI identifies candidates using a sliding window approach that could be a pedestrian (ruling out, for example, portions of the sky). Those “pedestrian” patches were then processed by the CNN to determine if it was in fact a pedestrian. CNN-based pedestrian detection solutions have been shown to have better accuracy than algorithms like HoG and perhaps more importantly, it is easier to retrain a CNN to look for a bicycle than it is to write a new hand-crafted algorithm to detect a bicycle instead of a pedestrian.
Larger CNNs for Whole Frame Object Detection
As embedded CNNs become more powerful, they no longer are restricted to processing patches of the incoming image. Synopsys’s latest vision processor, the EV6x, includes a CNN engine with 880 MACs – a significant performance leap compared to its predecessor. Running at 800MHz, this produces (880 x .8) = 704 GMACs/s or about 1400 GOPs/s. That performance is enough to process an entire 1MP image using CNN. The vector DSP is still valuable for pre-processing the images (e.g., reformatting and pyramiding) and performing post-processing tasks like non-maximum suppression (NMS). As shown in Figure 4, the EV6x still has scalar, vector and CNN units for heterogeneous processing. It was also designed with multicore features that allow it to easily scale to multiple vision cores.
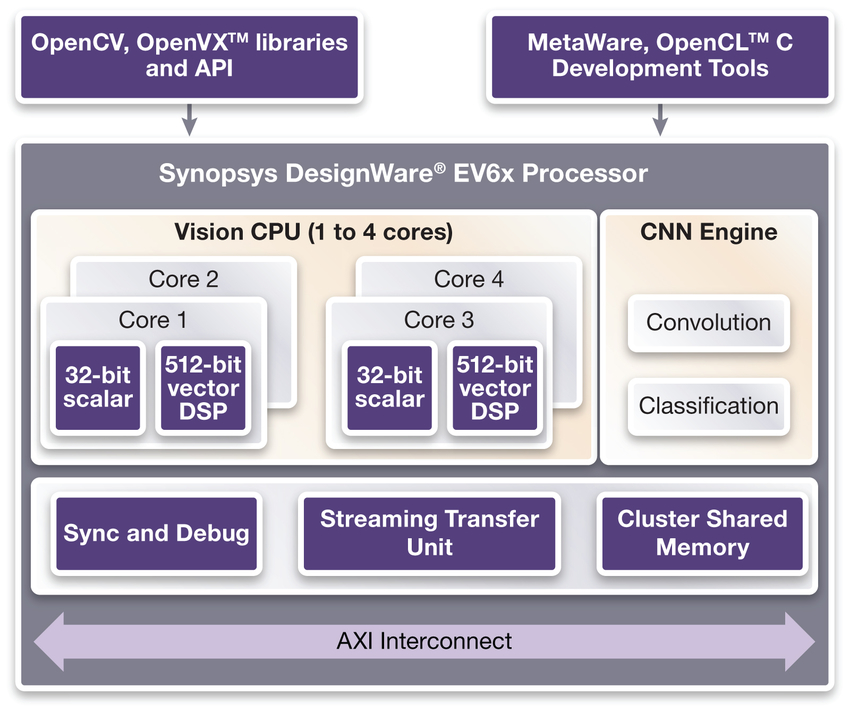
Figure 4: DesignWare EV6x Embedded Vision Processors include scalar, vector and CNN processing units for both pre- and post-processing
The benefit of processing the entire image frame is that CNN can be trained to detect multiple objects. Now, instead of just finding a pedestrian, the CNN graph can be trained to find a bicycle, other automobiles, trucks, etc. To do that with an algorithm like HoG would require hand-crafting the algorithm for each new object type.
Training and Deploying CNNs
As mentioned earlier, a CNN is not programmed. It is trained. A deep learning framework, like Caffe or TensorFlow, will use large data sets of images to train the CNN graph – refining coefficients over multiple iterations – to detect specific features in the image. Figure 5 shows the key components for CNN graph training, where the training phase uses banks of GPUs in the cloud for the significant amount of processing required.
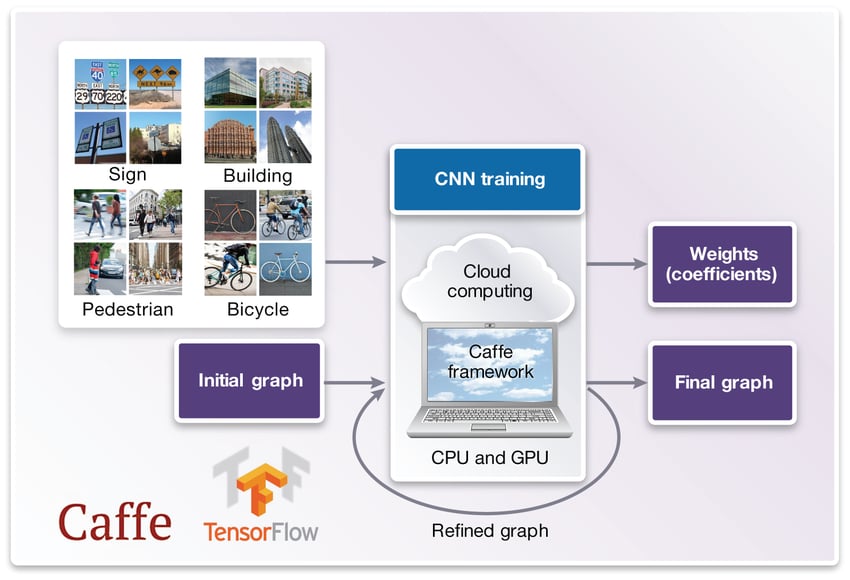
Figure 5: Components required for graph training
The deployment – or “inference” – phase is executed on the embedded system. Development tools, such as Synopsys’s MetaWare EV Toolkit, take the 32-bit floating point weights or coefficients output from the training phase and scale them to a fixed point format. The goal is to use the smallest bit resolution that still produces equivalent accuracy compared to the 32-bit floating point output. Fewer bits in a multiply-accumulator means less power required to calculate the CNN and smaller die area (leading to lower the cost) for the embedded solution. Based on Synopsys calculations, 10-bit or higher in resolution is needed to assure the same accuracy of the 32-bit Caffe output without graph retraining.
The MetaWare EV tools take the weights and the graph topology (the structure of the convolutional, non-linearity, pooling, and fully connected layers that exist in a CNN graph) and maps them into the hardware for the dedicated CNN engine. Assuming there are no special graph layers, the CNN is now “programmed” to detect the objects that it’s been trained to detect.
To keep the size small, the CNN engine is optimized to execute for key CNN features such as 3×3 and 5×5 matrix multiples, but not so optimized that it becomes a hard wired solution. It’s important to be programmable to maintain flexibility. As CNNs continue to evolve – new layer techniques or pooling methods for example – the vector DSP can play another important role in the vision processing. Since the vector DSP and CNN engine are closely coupled in the Synopsys EV6x, it is easy to dispatch tasks from the CNN to the vector DSP as needed. OpenVX runtime, incorporated into the MetaWare EV tools, makes sure those tasks are scheduled with other vector DSP processing requirements. The vector DSP future-proofs the CNN engine.
Figure 6 shows the inputs and outputs of an embedded vision processor. The streaming images from the car’s camera are fed into the CNN engine that is preconfigured with the graph and weights. The output of the CNN is a classification of the contents of the image.
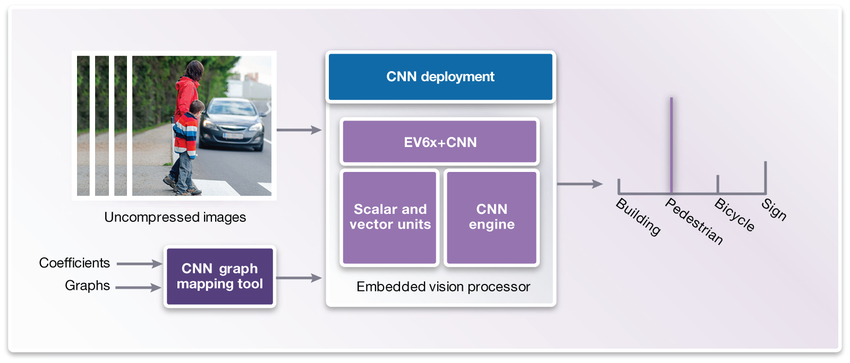
Figure 6: Inputs and outputs of embedded vision processor
Scene Segmentation and Navigation
Up to now, we’ve discussed object classification of pedestrians (or bicycles or cars or trucks) that can be used for collision avoidance – an ADAS example. CNNs with high enough performance can also be used for scene segmentation – the identifying of all the pixels in an image. The goal for scene segmentation is less about identifying specific pixels than it is to identify the boundaries between types of objects in the scene. Knowing where the road is compared to other objects in the scene provides a great benefit to a car’s navigation and brings us one step closer to autonomous vehicles.
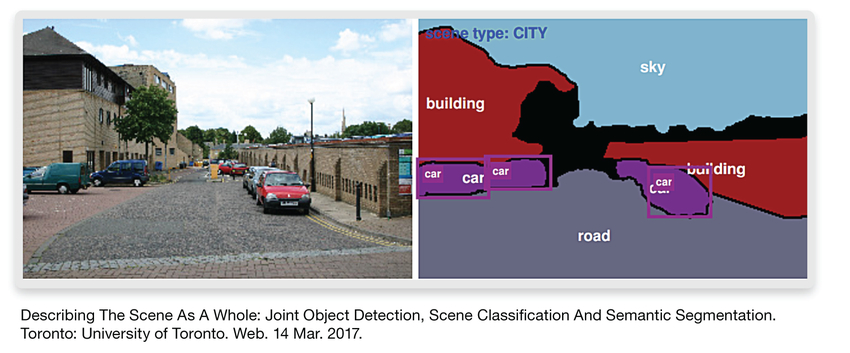
Figure 7: Scene segmentation identifies the boundaries between types of objects
One scene segmentation example, running on a DesignWare EV61’s CNN, segmented the streaming images using 11 categories of objects (road, sky, buildings, pedestrians, etc.). With five channels of 1920×1080 images as input, the CNN, running at 800MHz, achieved 18fps. Scene segmentation is difficult for CNNs that don’t have the horsepower to process multiple instances of the full images (frames).
Future Requirements for Vision Processors in Automotive Vision
Vision processing solutions will need to scale as future demands call for more processing performance. A 1MP image is a reasonable resolution for existing cameras in automobiles. However, more cameras are being added to the car and the demand is growing from 1MP to 3MP or even 8MP cameras. The greater a camera’s resolution, the farther away an object can be detected. There are simply more bits to analyze to determine if an object, such as a pedestrian, is ahead. The camera frame-rate (FPS) is also important. The higher the frame rate, the lower the latency and the greater the stopping distance. For a 1MP RGB camera running at 15 FPS, that would be 1280×1024 pixels/frame times 15 frames/second times three colors or about 59M bytes/second to process. An 8MP image at 30fps will require 3264×2448 pixels/frame times 30 frames/second times three colors or about 720M bytes/second.
This extra processing performance can’t come with a disproportionate spike in power or die area. Automobiles are consumer items that have constant price pressures. Low power is very important. Vision processor architectures have to be as optimized as power and yet still retrain programmability.
Conclusion
As the requirements for ADAS in automotive applications continue to grow, embedded vision and deep learning technology will keep up. Object detection has evolved from small-scale identification to full scenes with every pixel accounted for, and flexibility will continue to be as important as performance, power and area. Synopsys’ DesignWare EV6x Embedded Vision Processors are fully programmable to address new graphs as they are developed, and offers high performance in a small area and with highly efficient power.