This blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
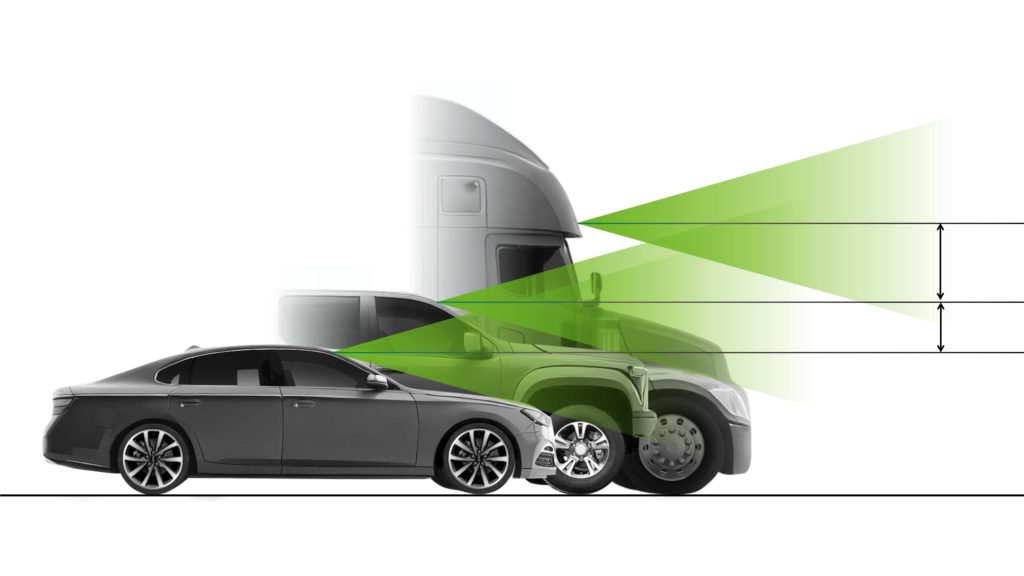
Autonomous vehicles (AV) come in all shapes and sizes, ranging from small passenger cars to multi-axle semi-trucks. However, a perception algorithm deployed on these vehicles must be trained to handle similar situations, like avoiding an obstacle or a pedestrian.
The datasets used to develop and validate these algorithms are typically collected by one type of vehicle— for example sedans outfitted with cameras, radars, lidars, and ultrasonic sensors.
Perception algorithms trained on fleet sensor data can perform reliably on similar sensor configurations. However, when deploying the same algorithm on a vehicle with a different sensor configuration, perception performance can degrade, as it is seeing the world from a new point of view.
Addressing any loss in perception accuracy requires measuring the sensitivity of the deep neural network (DNN) to new sensor positions. Using the sensitivity analysis, it is possible to retrain the perception algorithm with data from multiple points of view to improve robustness in a targeted manner.
However, performing a sensitivity analysis and retraining perception both require the collection and annotation of datasets across a variety of sensor configurations. This is a time- and cost-prohibitive process.
This post shows how synthetic datasets in NVIDIA DRIVE Sim and the latest NVIDIA research in novel view synthesis (NVS) fill these data gaps and help recover perception accuracy otherwise lost when deploying to new sensor configurations.
Measuring DNN sensitivity
Before creating synthetic datasets for different sensor viewpoints, the first step is to create a digital twin of the test fleet vehicle in NVIDIA DRIVE Sim, along with a sensor rig of simulated cameras that are calibrated to match real-world sensor configurations.
Synthetic data is generated by driving the ego-vehicle through a predefined scenario where it follows a specific trajectory, and saving the simulated camera data. For each run of the scenario, aspects are varied, such as sensor rig height, pitch, and mount position to emulate other vehicle types.
Using the capabilities of NVIDIA Omniverse Replicator, generate the ground truth (GT) labels, such as 3D bounding boxes, and object classes needed to evaluate perception algorithms. This entire workflow is repeatable and enables running well-defined experiments to quickly measure perception sensitivity.
After running DNN inference on the generated datasets, compare the network’s predictions with the GT labels to measure the network’s accuracy for each sensor configuration for different camera heights, as shown in Figures 1 and 2. Each dataset is the same scenario but from different sensor view points. In Figure 1, blue boxes represent GT labels while green boxes show the network’s predictions. In Figure 2, blue boxes represent GT labels while red boxes show the network’s predictions.

Figure 1. An example of an object detection DNN running on four different synthetic datasets, focusing on the vehicle object class

Figure 2. Example of an object detection DNN running on four different synthetic datasets, focusing on the pedestrian object class
Given that the network was trained on data from one vehicle type, detections are more accurate for similar camera positions, and degrade as camera positions change significantly.
Addressing these gaps in perception and deploying on a new vehicle type requires a targeted dataset for viewpoints that differ from the original data. While existing fleet data can be used with traditional augmentations, this approach does not fully satisfy the need for datasets captured from new points of view.
Novel view synthesis
NVS is a computer vision method for generating new, unseen views of a scene from a set of existing images. This capability makes it possible to create images of a scene from different viewpoints or angles not originally captured by the vehicle’s camera.

Figure 3. The complete novel view synthesis pipeline
The NVIDIA research team recently presented an NVS method that can transform dynamic driving data from one sensor position to new viewpoints emulating other camera heights, pitches, and angles. For details, see Towards Viewpoint Robustness in Bird’s Eye View Segmentation.
Our approach builds on Worldsheet, a method for using depth estimation and 3D meshing to synthesize new viewpoints of a static scene. A 3D scene mesh is created by warping a lattice grid onto a scene based on predicted depth values. Then, a texture sampler is used to “splat,” or project, the RGB pixel intensities from the original image onto the texture map of the 3D mesh. This approach expands on prior work in this area by using lidar-based depth supervision and automasking to improve the quality of the depth estimation and handle occlusions.
The NVS model can now be used to generate data as if it was acquired from different vehicle types, unblocking existing fleet data for use in all future AV development.

Figure 4. Examples of NVS-transformed images, generating viewpoints with changes in pitch, depth and height
Validating NVS and improving perception performance
Before incorporating NVS-generated data into the training dataset, first validate that it accurately represents the real world and is effective for perception training.
To do this, validate the NVS algorithm by training a perception algorithm on a combination of fleet data and NVS-transformed data. In the absence of real data to test the model’s performance from multiple sensor viewpoints, generate synthetic data and GT labels in DRIVE Sim, similar to the sensitivity testing previously discussed.

Figure 5. A set of camera images generated in DRIVE Sim with varied pitch, depth, and height for perception validation
Running inference on these synthetic datasets shows that using NVS-generated data for training can improve perception performance. Specifically:
- NVS-generated data quality is best for changes in sensor pitch and lowest for large changes in height.
- NVS-transformed data for training enables recovering valuable perception performance that would only have been possible by collecting new data for each new sensor configuration.
This approach unlocks a new approach to AV development, where data only needs to be collected once, then repurposed for multiple vehicle types—significantly reducing cost and time to deployment.
Conclusion
Developing a perception stack that works robustly across different vehicle types is a massive data challenge. However, synthetic data generation and AI techniques for novel view synthesis enable the systematic measurement of perception sensitivity. This significantly multiplies the value of existing datasets and reduces the time to deploy a perception stack for any vehicle.
We invite the research community to add to this body of work. Accordingly, we are releasing the synthetic data from DRIVE Sim as reported in Towards Viewpoint Robustness in Bird’s Eye View Segmentation. Explore this data and learn more.
Related resources
- GTC session: How to Generate Synthetic Data with NVIDIA DRIVE Replicator (Spring 2023)
- GTC session: A State-of-the-Art AI Solution for Point Cloud Resolution Transformation Based on Synthetic Data (Spring 2023)
- GTC session: Generate Synthetic Data Using Omniverse Replicator for Perception Models (Spring 2023)
- Webinar: Isaac Developer Meetup #2 – Build AI-Powered Robots with NVIDIA Isaac Replicator and NVIDIA TAO
- Webinar: Enhancing Robotic Perception: Synthetic Data Generation using Omniverse Replicator
- Webinar: Inception Workshop 101 – Getting Started with Vision AI
Gautham Sholingar
Senior Manager, AV Simulation Product Team, NVIDIA
Jose Alvarez
Research Director, NVIDIA
Tae Eun Choe
Distinguished Engineer, NVIDIA
Jungseock Joo
Principal Computer Vision and Deep Learning Engineer, NVIDIA