
This blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
Vision-language models (VLMs) combine the powerful language understanding of foundational LLMs with the vision capabilities of vision transformers (ViTs) by projecting text and images into the same embedding space. They can take unstructured multimodal data, reason over it, and return the output in a structured format. Building on a broad base of pretraining, they can be easily adapted for different vision-related tasks by providing new prompts or parameter-efficient fine-tuning.
They can also be integrated with live data sources and tools, to request more information if they don’t know the answer or take action when they do. LLMs and VLMs can act as agents, reasoning over data to help robots perform meaningful tasks that might be hard to define.
In a previous post, Bringing Generative AI to Life with NVIDIA Jetson, we demonstrated that you can run LLMs and VLMs on NVIDIA Jetson Orin devices, enabling a breadth of new capabilities like zero-shot object detection, video captioning, and text generation on edge devices.
But how can you apply these advances to perception and autonomy in robotics? What are the challenges you face when deploying these models into the field?
In this post, we discuss ReMEmbR, a project that combines LLMs, VLMs, and retrieval-augmented generation (RAG) to enable robots to reason and take actions over what they see during a long-horizon deployment, on the order of hours to days.
ReMEmbR’s memory-building phase uses VLMs and vector databases to efficiently build a long-horizon semantic memory. Then ReMEmbR’s querying phase uses an LLM agent to reason over that memory. It is fully open source and runs on-device.
ReMEmbR addresses many of the challenges faced when using LLMs and VLMs in a robotics application:
- How to handle large contexts.
- How to reason over a spatial memory.
- How to build a prompt-based agent to query more data until a user’s question is answered.
To take things a step further, we also built an example of using ReMEmbR on a real robot. We did this using Nova Carter and NVIDIA Isaac ROS and we share the code and steps that we took. For more information, see the following resources:
- ReMEmbR website
- /NVIDIA-AI-IOT/remembr GitHub repo
- ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation paper
Enhancing Robot Navigation with LLM Agent ReMEmbR
ReMEmbR for long-horizon spatial and temporal memory, reasoning, and action
Robots are increasingly expected to perceive and interact with their environments over extended periods. Robots are deployed for hours, if not days, at a time and they incidentally perceive different objects, events, and locations.
For robots to understand and respond to questions that require complex multi-step reasoning in scenarios where the robot has been deployed for long periods, we built ReMEmbR, a retrieval-augmented memory for embodied robots.
ReMEmbR builds scalable long-horizon memory and reasoning systems for robots, which improve their capacity for perceptual question-answering and semantic action-taking. ReMEmbR consists of two phases: memory-building and querying.
In the memory-building phase, we took advantage of VLMs for constructing a structured memory by using vector databases. During the querying phase, we built an LLM agent that can call different retrieval functions in a loop, ultimately answering the question that the user asked.
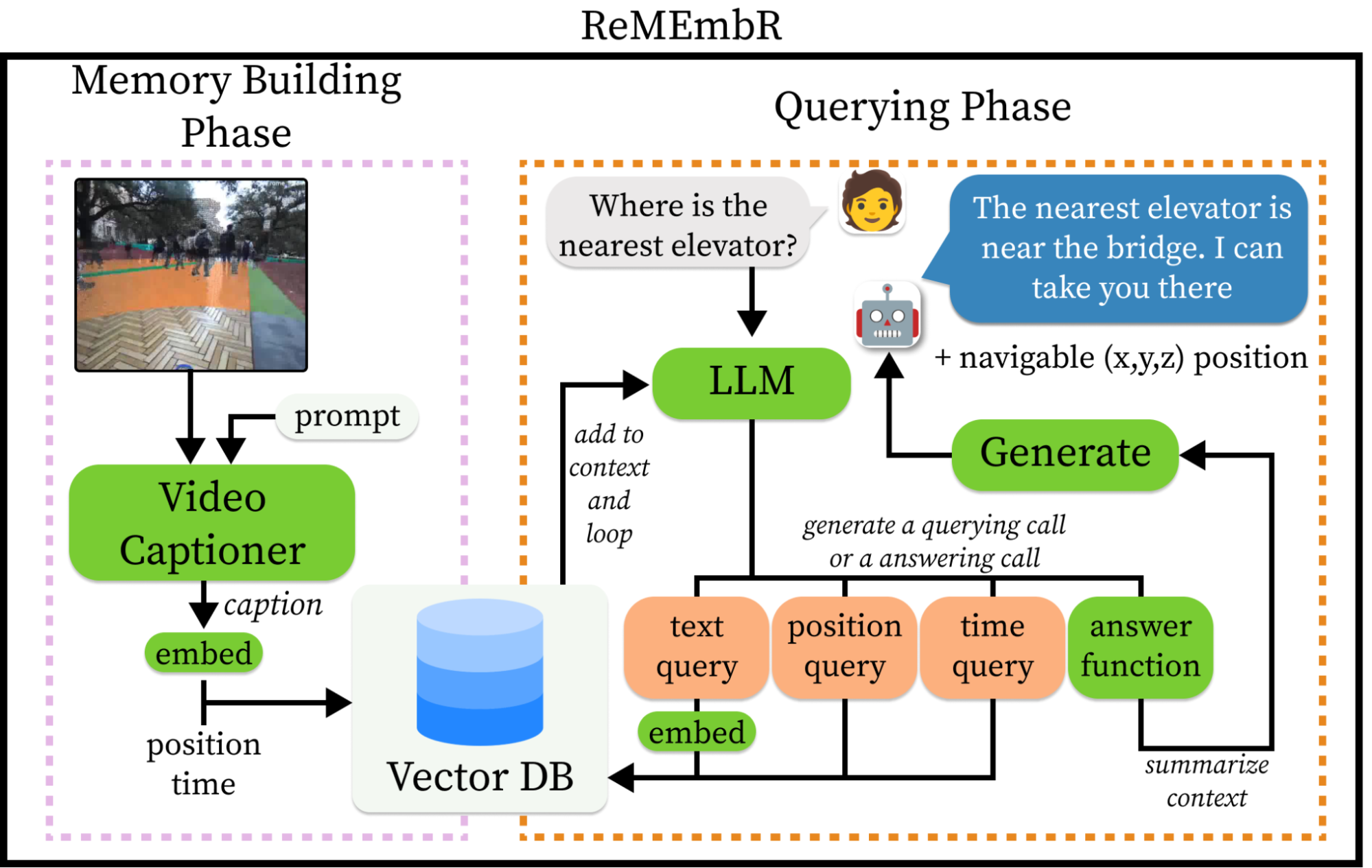 Figure 1. Full ReMEmbR system
Figure 1. Full ReMEmbR system
Building a smarter memory
ReMEmbR’s memory-building phase is all about making memory work for robots. When your robot has been deployed for hours or days, you need an efficient way of storing this information. Videos are easy to store, but hard to query and understand.
During memory building, we take short segments of video, caption them with the NVIDIA VILA captioning VLM, and then embed them into a MilvusDB vector database. We also store timestamps and coordinate information from the robot in the vector database.
This setup enabled us to efficiently store and query all kinds of information from the robot’s memory. By capturing video segments with VILA and embedding them into a MilvusDB vector database, the system can remember anything that VILA can capture, from dynamic events such as people walking around and specific small objects, all the way to more general categories.
Using a vector database makes it easy to add new kinds of information for ReMEmbR to take into consideration.
ReMEmbR agent
Given such a long memory stored in the database, a standard LLM would struggle to reason quickly over the long context.
The LLM backend for the ReMEmbR agent can be NVIDIA NIM microservices, local on-device LLMs, or other LLM APIs. When a user poses a question, the LLM generates queries to the database, retrieving relevant information iteratively. The LLM can query for text information, time information, or position information depending on what the user is asking. This process repeats until the question is answered.
Our use of these different tools for the LLM agent enables the robot to go beyond answering questions about how to go to specific places and enables reasoning spatially and temporally. Figure 2 shows how this reasoning phase may look.
 Figure 2. Example ReMEmbR query and reasoning flow
Figure 2. Example ReMEmbR query and reasoning flow
Deploying ReMEmbR on a real robot
To demonstrate how ReMEmbR can be integrated into a real robot, we built a demo using ReMEmbR with NVIDIA Isaac ROS and Nova Carter. Isaac ROS, built on the open-source ROS 2 software framework, is a collection of accelerated computing packages and AI models, bringing NVIDIA acceleration to ROS developers everywhere.
In the demo, the robot answers questions and guides people around an office environment. To demystify the process of building the application, we wanted to share the steps we took:
- Building an occupancy grid map
- Running the memory builder
- Running the ReMEmbR agent
- Adding speech recognition
Building an occupancy grid map
The first step we took was to create a map of the environment. To build the vector database, ReMEmbR needs access to the monocular camera images as well as the global location (pose) information.
 Figure 3. Building an occupancy grid map with Nova Carter
Figure 3. Building an occupancy grid map with Nova Carter
Depending on your environment or platform, obtaining the global pose information can be challenging. Fortunately, this is straightforward when using Nova Carter. Nova Carter, powered by the Nova Orin reference architecture, is a complete robotics development platform that accelerates the development and deployment of next-generation autonomous mobile robots (AMRs). It may be equipped with a 3D LIDAR to generate accurate and globally consistent metric maps.
 Figure 4. FoxGlove visualization of an occupancy grid map being built with Nova Carter
Figure 4. FoxGlove visualization of an occupancy grid map being built with Nova Carter
By following the Isaac ROS documentation, we quickly built an occupancy map by teleoperating the robot. This map is later used for localization when building the ReMEmbR database and for path planning and navigation for the final robot deployment.
Running the memory builder
After we created the map of the environment, the second step was to populate the vector database used by ReMEmbR. For this, we teleoperated the robot, while running AMCL for global localization. For more information about how to do this with Nova Carter, see Tutorial: Autonomous Navigation with Isaac Perceptor and Nav2.

Figure 5. Running the ReMEmBr memory builder
With the localization running in the background, we launched two additional ROS nodes specific to the memory-building phase.
The first ROS node runs the VILA model to generate captions for the robot camera images. This node runs on the device, so even if the network is intermittent we could still build a reliable database.
Running this node on Jetson is made easier with NanoLLM for quantization and inference. This library, along with many others, is featured in the Jetson AI Lab. There is even a recently released ROS package (ros2_nanollm) for easily integrating NanoLLM models with a ROS application.
The second ROS node subscribes to the captions generated by VILA, as well as the global pose estimated by the AMCL node. It builds text embeddings for the captions and stores the pose, text, embeddings, and timestamps in the vector database.
Running the ReMEmbR agent
 Figure 6. Running the ReMEmbR agent to answer user queries and navigate to goal poses
Figure 6. Running the ReMEmbR agent to answer user queries and navigate to goal poses
After we populated the vector database, the ReMEmbR agent had everything it needed to answer user queries and produce meaningful actions.
The third step was to run the live demo. To make the robot’s memory static, we disabled the image captioning and memory-building nodes and enabled the ReMEmbR agent node. As detailed earlier, the ReMEmbR agent is responsible for taking a user query, querying the vector database, and determining the appropriate action the robot should take. In this instance, the action is a destination goal pose corresponding to the user’s query.
We then tested the system end-to-end by manually typing in user queries:
“Take me to the nearest elevator”
“Take me somewhere I can get a snack”
The ReMEmbR agent determines the best goal pose and publishes it to the /goal_pose topic. The path planner then generates a global path for the robot to follow to navigate to this goal.
Adding speech recognition
In a real application, users likely won’t have access to a terminal to enter queries and need an intuitive way to interact with the robot. For this, we took the application a step further by integrating speech recognition to generate the queries for the agent.
On Jetson Orin platforms, integrating speech recognition is straightforward. We accomplished this by writing a ROS node that wraps the recently released WhisperTRT project. WhisperTRT optimizes OpenAI’s whisper model with NVIDIA TensorRT, enabling low-latency inference on NVIDIA Jetson AGX Orin and NVIDIA Jetson Orin Nano.
The WhisperTRT ROS node directly accesses the microphone using PyAudio and publishes recognized speech on the speech topic.
 Figure 7. Integrating speech recognition with WhisperTRT, for natural user interaction
Figure 7. Integrating speech recognition with WhisperTRT, for natural user interaction
All together
With all the components combined, we created our full demo of the robot.
Get started
We hope this post inspires you to explore generative AI in robotics. To learn more about the contents presented in this post, try out the ReMEmBr code, and get started building your own generative AI robotics applications, see the following resources:
- ReMEmbR website
- /NVIDIA-AI-IOT/remembr GitHub repo
- ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation paper
- NVIDIA Isaac ROS documentation
- Nova Carter
- NVIDIA Jetson AI Lab
Sign up for the NVIDIA Developer Program for updates on additional resources and reference architectures to support your development goals.
Stay up to date on LinkedIn, Instagram, X, and Facebook. For more information, explore our documentation and join the robotics community on our developer forums and YouTube channels. Follow along with self-paced training and webinars (Isaac ROS and Isaac Sim).
Related resources
- GTC session: Implementing Generative AI in Practice
- GTC session: Robotics in the Age of Generative AI
- GTC session: Generative AI Theater: Learning to Do Physical Work: Converting Natural Language High-Level Requests Into Complex Robot Instructions
- Webinar: Bringing Generative AI to Life with NVIDIA Jetson
- Webinar: What AI Teams Need to Know About Generative AI
- Webinar: Fast-Track to Generative AI With NVIDIA
Abrar Anwar
Ph.D. student, University of Southern California
Intern, NVIDIA
John Welsh
Developer technology engineer, autonomous machines, NVIDIA
Yan Chang
Principal engineer and senior engineering manager, NVIDIA