This blog post was originally published at Nota AI’s website. It is reprinted here with the permission of Nota AI.
-
Proposes a simple next-frame prediction task using unlabeled video to enhance single-image encoders.
-
Injects 3D geometric and temporal priors into image-based models without requiring optical flow or object tracking.
-
Outperforms state-of-the-art self-supervised methods like DoRA and DINO on semantic segmentation (ADE20K) and object detection (COCO).
Most self-supervised visual representation learning methods rely solely on static images, overlooking the rich temporal and geometric cues present in videos. This paper introduces a simple change at training time: training a student network to predict the next frame’s features from the current frame embedding, supervised by a teacher network updated via EMA.
This approach is simpler yet more effective than existing methods like DoRA (uses object tracking) and PooDLe (uses optical flow). The proposed model achieves 36.4% mIoU on ADE20K and 33.5 mAP on COCO, surpassing current state-of-the-art performance.
Significance/Importance of the Paper
This work addresses one of the major limitations of existing self-supervised learning approaches—lack of temporal modeling. Without expensive modules like optical flow estimators or object trackers, the proposed method injects temporal and spatial reasoning into the encoder using only a lightweight auxiliary learning objective.
The approach enhances encoder representation without architectural changes, making it easy to apply in settings like robotics or embedded devices. Additionally, the prediction head used during training is discarded afterward, preserving inference efficiency.
Summary of Methodology
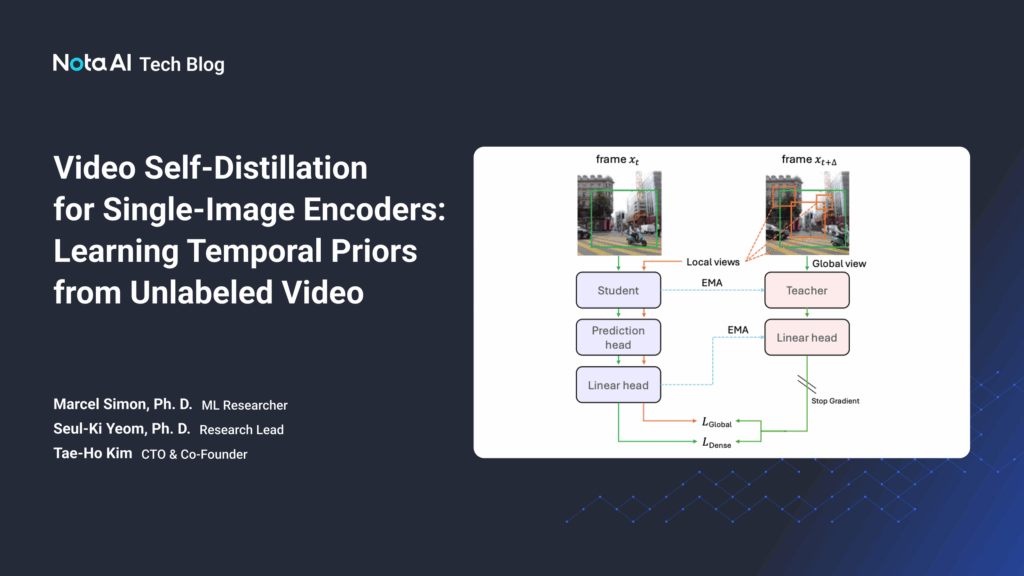
The architecture is based on a student-teacher framework similar to DINO. During training, the student predicts patch-level features of the next frame (t+30) from the current frame (t), and the teacher network (EMA-updated) provides the target features.
- The prediction head contains two attention blocks and an MLP, used only during training.
- The loss function is the average of: (1) dense next-frame prediction loss (patch-wise cross-entropy), and (2) a global [CLS] token-based contrastive loss.
This enables learning of dense, temporally informed features while maintaining efficient single-frame inference at test time.
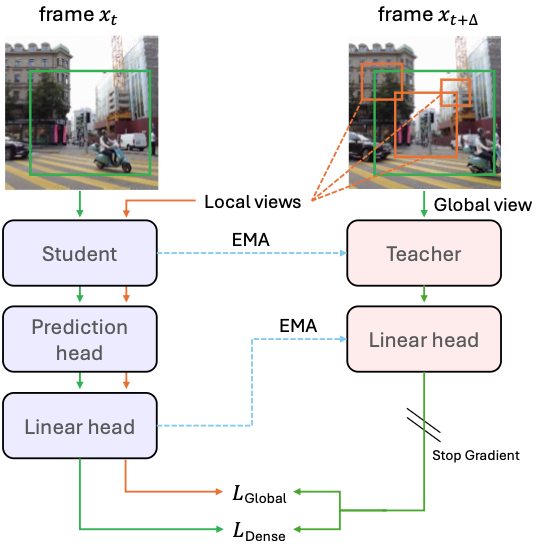 Figure 1: Training Overview
Figure 1: Training Overview
Experimental Results
For ADE20K semantic segmentation, we evaluated the model using both UperNet fine-tuning and linear probing:
- Our approach achieved 36.4% mIoU, outperforming DoRA (35.0%) and various DINO baselines.
- In linear probing, our method reached 18.3%, compared to 17.0% for DoRA.
 Table 1. Semantic segmentation results on ADE20
Table 1. Semantic segmentation results on ADE20
For object detection on MS COCO:
- Our model achieved 33.5 mAP, outperforming DoRA (33.0%) and DINO (33.3%).
- These improvements were achieved without optical flow or tracking, underscoring the simplicity and robustness of the method.
 Table 2. Object detection results on COCO
Table 2. Object detection results on COCO
Ablation on the stride parameter Δ shows best results at Δ = 30, confirming the benefit of moderate temporal context over shorter or excessively long intervals.
 Figure 2. Effect of prediction stride ∆ on ADE20K fast-linear accuracy
Figure 2. Effect of prediction stride ∆ on ADE20K fast-linear accuracy
Conclusion
This paper presents a simple yet effective self-supervised framework that enables single-image encoders to learn temporal reasoning during training. Using next-frame prediction alone, the model learns both temporal and geometric priors without requiring optical flow or object tracking modules.
Validated through semantic segmentation and object detection benchmarks, this approach holds promise for real-world applications such as robotics and vision-language systems, offering a practical path toward physically grounded perception.
Marcel Simon, Ph. D.
ML Researcher, Nota AI GmbH
Tae-Ho Kim
CTO & Co-Founder, Nota AI
Seul-Ki Yeom, Ph. D.
Research Lead, Nota AI GmbH
If you have any further inquiries about this research, please feel free to reach out to us at following email address: [email protected].
Furthermore, if you have an interest in AI optimization technologies, you can visit our website at netspresso.ai.