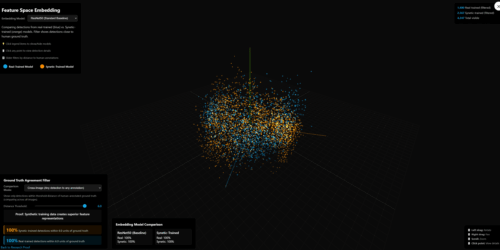
Better Than Real? What an Apple-Orchard Benchmark Really Says About Synthetic Data for Vision AI
If you work on edge AI or computer vision, you’ve probably run into the same wall over and over: The model architecture is fine. The deployment hardware is (barely) ok. But the data is killing you—too narrow, too noisy, too expensive to expand. That’s true whether you’re counting apples, spotting defects on a production line, […]








