

Secure Edge AI, High-Speed Vision and Power-Efficient Design With VectorBlox™
Microchip’s FPGA Engineer, Apurva Peri, shares the VectorBlox™ Accelerator SDK solution, which offers AI/ML Inference for PolarFire® FPGAs and SoCs. This software-based implementation enables AI deployment without reprogramming the FPGA, supports sparse networks using structured and unstructured compression and provides power-efficient inference and video pipelines delivering less than 5W power consumption. This Broad AI model

Microchip Demonstrates Secure Edge AI Facial Recognition with Single-Camera Liveness Detection
Swapna Gurumani from Microchip’s Edge AI business unit demonstrates the company’s facial recognition with liveness detection solution at the 2026 Embedded Vision Summit. The demo shows how Microchip’s Edge AI technology enables secure, real-time identity verification using a single RGB camera and on-device processing. The solution combines facial recognition with liveness detection to help identify

From Silicon to Ecosystems: The New Edge AI Competitive Model
This blog post was originally published at Macnica America’s website. It is reprinted here with the permission of Macnica America. For years, silicon providers have benefited from a well-established stakeholder ecosystem of traditional sales, direct markets and customer solutions that have been pioneering the physical AI deployment. Today, that success requires a lot more work. Silicon

NXP Tech Days Comes to Silicon Valley
NXP Semiconductors will host “NXP Tech Days,” on August 18, 2026, from 9:00 am to 6:00 pm PDT in Santa Clara, California. The event will feature hands-on workshops, expert-led sessions, and real-world insights across embedded systems, edge AI, connectivity, and security. From the event page: The Future, Engineered During the general session, discover how NXP

Microchip’s Demonstration of an SDI-to-HDMI® Cross-Converter on PolarFire FPGAs
Prakash Battu, Senior Manager of Design Engineering at Microchip, shares the company’s latest SDI-to-HDMI cross-converter solution. Built on PolarFire® FPGAs, the application supports dynamic rate switching and embedded audio across all SDI standards from 1.5G to 12G, and a standard HDMI IP for seamless interoperability. Because the design that delivers 2× better power efficiency, it

Real-Time Vision-Language Inference on AMD Radeon™ iGPU Using ROCm™
This demonstration showcases a real-time vision-language inference pipeline running on an AMD Radeon™ integrated GPU, highlighting multimodal AI capabilities on power-efficient embedded platforms. The system processes live or recorded video streams and enables interactive question answering based on visual scene understanding. A lightweight Vision-Language Model (VLM) is deployed to jointly interpret visual inputs and natural

NVIDIA Introduces New Jetson Thor Computers to Advance Mainstream Robotics and Edge AI
New NVIDIA Blackwell-powered T3000 and T2000 modules, paired with new NVIDIA Jetson software memory optimization and agent skills, help partners and customers move advanced robotics, visual AI and edge workloads onto compact, power-efficient systems. This news blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA. General-purpose

AMD Versal™ AI Edge Series Gen 2Hard ISP Featuring 12x Sensor Inputs
This demo showcases the AMD Versal™ AI Edge Series Gen 2 VEK385 evaluation board’s ability to support streaming raw video data from 12 different CMOS image sensors concurrently and process 14 live streams out through the hardened ISP blocks in a single 2VE3858 adaptive SoC. It features a mix of sensors with different resolutions and

AI Agents on AMD – Secure Agent Computing at the Edge
See how agentic AI workflows can use both local AMD hardware and cloud resources to improve privacy, performance, and cost efficiency. This demo showcases AI agents running with the AMD ROCm™ software platform. Private and data-sensitive tasks can remain on the local system, while more demanding workloads can be sent to cloud-based models when needed.
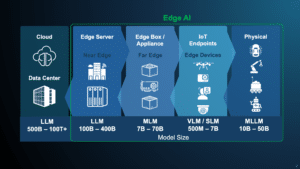
Free Webinar on Building Trustworthy Physical AI at the Edge
On September 2, 2026 at 9 am PT (noon ET), Muneyb Minhazuddin, Customer Growth Officer at Ambarella and Pietro Antonio Cicalese, Senior Technical Marketing Engineer at Ambarella, will present the free hour webinar “See, Think, Act, Learn: Building Trustworthy Physical AI at the Edge,” organized by the Edge AI and Vision Alliance. Here’s the description, from

Breadth, Depth and Value: Arm Empowers Developers for the Agentic AI Era
This blog post was originally published at Arm’s website. It is reprinted here with the permission of Arm. Great hardware matters, but software is what helps unlock its full value. Arm’s DNA is hardware, and our sustained software investments help make that hardware easier to use, optimize, and scale. Since our inception, Arm has invested across the

VeriSilicon Introduces CPP2000 Camera Post-Processing IP for Embodied Robotics and Mobile Vision Applications
Shanghai, China, July 3, 2026–VeriSilicon (688521.SH) today announced its high-performance CPP2000 Camera Post-Processing (CPP) IP, expanding the company’s Image Signal Processing (ISP) solutions with advanced post-processing capabilities. By improving image quality and visual perception in mobile imaging scenarios, CPP2000 enables more reliable vision performance in robotics, drones, and other mobile vision applications. CPP2000 integrates multiple

Microchip Advances Neural Network Implementation with VectorBlox 3.0 Accelerator SDK
Latest release leverages sparse neural networks to improve performance and enable more efficient edge AI on PolarFire® FPGAs and SoCs CHANDLER, Ariz., July 14, 2026 — Deploying AI inference in power‑constrained and mission‑critical environments such as aerospace and defense systems requires solutions that balance performance, efficiency, reliability and ease of development. To better manage these challenges,

Smart Sensor Demo: On-Device Object Detection with Lattice CertusPro™-NX
Lattice Semiconductor demonstrates how the CertusPro-NX FPGA bridges an image sensor to a Raspberry Pi, performing on-device pre-processing and object detection before passing data to the host CPU. Sensor frames at 30 fps are fed into the FPGA, where an object detection model — trained on eight automotive object classes — runs locally and outputs

“From YOLO to SAM: Segmentation Models on Real Edge Hardware,” a Presentation from Au-Zone Technologies
Sébastien Taylor, VP of R & D at Au-Zone Technologies presents “From YOLO to SAM: Segmentation Models on Real Edge Hardware” at the May 2026 Embedded Vision Summit. Segmentation is fundamental to edge vision—from drivable surface detection to industrial inspection. But how do different approaches actually perform on resource-constrained hardware?… “From YOLO to SAM: Segmentation

Run Ultralytics YOLO on Axelera AIPUs in Minutes
This blog post was originally published at Axelera AI’s website. It is reprinted here with the permission of Axelera AI. Trying new AI hardware typically means weeks of integration work before you can tell if the hardware is even worth it. There’s a new compiler, new runtime, and new preprocessing quirks. By the time you’ve ported

Microchip Expands Developer Access with Free MPLAB® XC Compilers and MPLAB Machine Learning Development Suite
CHANDLER, Ariz., July 8, 2026 — Microchip Technology (Nasdaq: MCHP) has announced that its MPLAB® XC Pro Compilers and MPLAB Machine Learning (ML) Development Suite are now available at no cost to customers. By enabling unlimited installs across individual and team environments, these tools give developers free access to advanced optimization capabilities and integrated embedded machine learning workflows. “Our focus is on optimizing

Ebttikar and MemryX Form Strategic Partnership to Accelerate Computer Vision Edge AI Across Saudi Arabia
RIYADH, Saudi Arabia, July 9, 2026 /PRNewswire/ — Ebttikar Technology Company, a Saudi technology solutions provider and systems integrator, and MemryX Inc., a developer of edge AI inference accelerator chips, today announced a strategic partnership to accelerate the commercial deployment of production-ready Computer Vision Edge AI solutions across Saudi Arabia, with potential expansion to qualified opportunities in

Free Webinar on Designing Computer Vision for the Far Edge
On September 24, 2026 at 9 am PT (noon ET), Nicolas Widynski, AI Fellow at Lattice Semiconductor, will present the free hour webinar “Efficient Computer Vision at the Far Edge: Design and Training Under Constraints,” organized by the Edge AI and Vision Alliance. Here’s the description, from the event registration page: This session explores practical

Upcoming Webinar on Agentic Smart City Systems
On July 29, 2026 at 10:00 am PT (1:00 pm ET), Intel will present the webinar “Agentic Smart City Systems: Real-Time Traffic Orchestration.” Here’s the description, from the event registration page: Beat congestion, save time, and route smarter in this hands-on, gamified workshop where Agentic AI meets Edge AI to power next-generation smart cities and