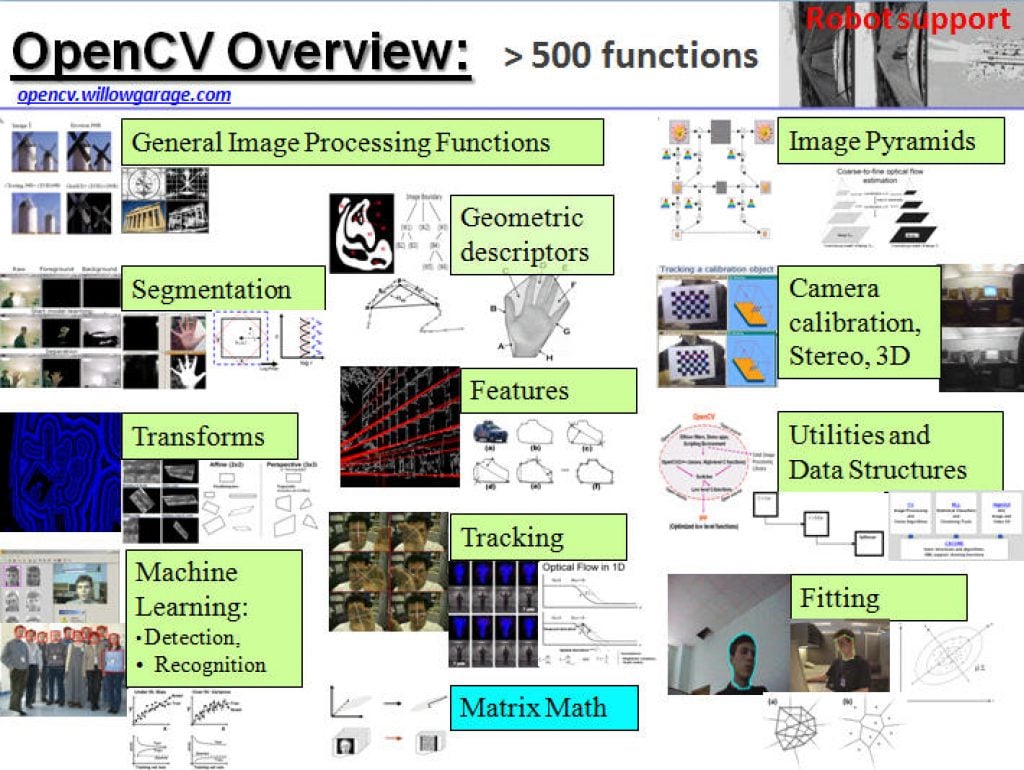

The Future of Security Is Already Running. Here Is What It Looks Like.
This blog post was originally published at Axelera AI’s website. It is reprinted here with the permission of Axelera AI. A camera sees everything and understands nothing. For decades, that has been the fundamental limitation of physical security at scale: vast amounts of footage, limited ability to act on it in real time. The gap between

Bringing AI Closer to the Edge and On-Device with Gemma 4
This blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA. The Gemmaverse expands with the launch of the latest Gemma 4 multimodal and multilingual models, designed to scale across the full spectrum of deployments, from NVIDIA Blackwell in the data center to Jetson at the edge. These models are suited

Google Pushes Multimodal AI Further Onto Edge Devices with Gemma 4
MOUNTAIN VIEW, Calif., April 2, 2026 — Google has introduced Gemma 4, a new family of open models with open weights that is clearly aimed at bringing more capable AI onto local hardware. Released under the Apache 2.0 license, the Gemma 4 family includes four sizes: E2B, E4B, 26B A4B MoE and 31B Dense. Google

The On-Device LLM Revolution: Why 3B-30B Models Are Moving to the Edge
This blog post was originally published at Quadric’s website. It is reprinted here with the permission of Quadric. After years of cloud-centric inference, AI is moving to the edge. The “Goldilocks zone” of 3B to 30B parameter models is delivering GPT-4-class performance on smartphones, automotive systems, and industrial equipment — and creating an acute challenge for

Inside the Intelligent Mobile Camera Powered by Exynos 2600 VPS
This blog post was originally published at Samsung Semiconductor’s website. It is reprinted here with the permission of Samsung Semiconductor. Until recently, the evolution of mobile cameras has been centered on the image sensor and the image signal processor (ISP). In this conventional architecture, the image sensor converts light into electrical signals, while the ISP corrects

Upcoming Webinar on Agentic Memory Systems
On April 16, 2026, at 1:00 pm EDT (10:00 am PDT) Boston.AI will deliver a webinar “Remembering to Forget: Agentic Memory Systems and Context Constraints” From the event page: As AI agents evolve from stateless responders into persistent, goal-directed systems, memory has become a central design challenge. The question is no longer just what agents

Lightweight Keyword Spotting Solution from Microchip
Microchip presents a customizable, target-agnostic solution to program wake words and voice commands. The ML model, generated and tested using a custom application, has low latency and a minimal memory footprint, making it ideal for resource-constrained embedded systems. The ML model can be integrated into voice-based applications running on any 32-bit microcontroller or microprocessor running

2026: The Year Intelligence Gets Physical
This article was originally published at Analog Devices’ website. It is reprinted here with the permission of Analog Devices. Artificial intelligence is entering a new phase where models interpret contextual data whilst interacting with the physical world in real time. At Analog Devices, Inc. (ADI), we call this Physical Intelligence: intelligent systems that can perceive, reason

Why Night HDR Is More Challenging Than Daytime HDR
This blog post was originally published at Visidon’s website. It is reprinted here with the permission of Visidon. High Dynamic Range (HDR) imaging has become a standard feature in modern cameras, from smartphones to automotive and surveillance systems. While daytime HDR is already a complex task, nighttime HDR introduces a completely different level of difficulty. The same

NVIDIA and Global Robotics Leaders Take Physical AI to the Real World
News Summary: Physical AI leaders across robot brain developers, industrial, and surgical robot giants and humanoid pioneers including ABB Robotics, AGIBOT, Agility, CMR Surgical, FANUC, Figure, Hexagon Robotics, KUKA, Medtronic, Skild AI, Universal Robots, World Labs and YASKAWA are building on NVIDIA technology to develop and deploy physical AI at scale. NVIDIA unveils new NVIDIA

AI at the Edge: Designing for Constraints from Day One
This blog post was originally published at ModelCat’s website. It is reprinted here with the permission of ModelCat. Artificial intelligence has never been more visible yet more misunderstood. Every week seems to bring new headlines about larger models, more parameters, and benchmark-breaking performance. For developers and product teams responsible for shipping real-world AI systems, that

Introducing the Electronics Industry’s First AI Agent with Visual Reasoning
This blog post was originally published at Rapidflare’s website. It is reprinted here with the permission of Rapidflare. AI has made extraordinary progress in understanding language. But in industries like semiconductors, electronics, manufacturing, medical devices, and infrastructure, language represents only a slice of the knowledge. The most critical technical knowledge is often not written in paragraphs. It

ERGO: Efficient High-Resolution Visual Understanding for Vision-Language Models
This blog post was originally published at Nota AI’s website. It is reprinted here with the permission of Nota AI. Key Takeaways: Efficient coarse-to-fine pipeline: A two-stage reasoning pipeline that first processes low-resolution inputs to identify task-relevant regions and then re-encodes them at higher resolution, reducing computational cost while preserving essential information. Reward for reasoning-driven perception:

ModelCat AI Announces AI Model Portability Across Silicon Devices
An industry first, ModelCat’s Agentic AI generates models for new chips using a user’s current production models, dramatically accelerating inferencing to the edge. SUNNYVALE, Calif., March 5, 2026 /PRNewswire/ — ModelCat, the creator of the world’s first fully autonomous AI model builder, today announced its latest innovative platform capability: Model Retargeting (Patent Pending). Using Model Retargeting, ModelCat customers gain model

Why On-device AI Matters
This blog post was originally published at ENERZAi’s website. It is reprinted here with the permission of ENERZAi. Hello! I’m Minwoo Son from ENERZAi’s Business Development team. Through several posts so far, we’ve shared ENERZAi’s full-stack software capabilities for delivering high-performance on-device AI — including Optimium, our proprietary AI compiler that encapsulates our optimization expertise;

Upcoming Webinar on LLM-driven Driver Development
On March 19, 2026, at 1:00 pm EDT (10:00 am PDT) Boston.AI will deliver a webinar “Intelligent Driver Development with LLM Context Engineering ” From the event page: Developing even simple sensor drivers can consume valuable engineering time, requiring manual transcription of registers from datasheets into code—an error-prone and repetitive process. In this webinar, you’ll