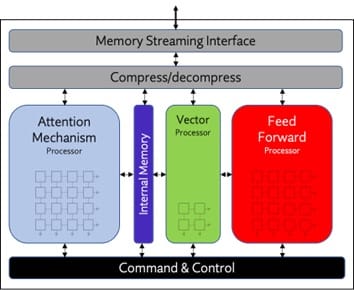
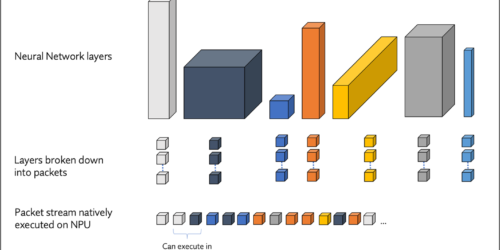
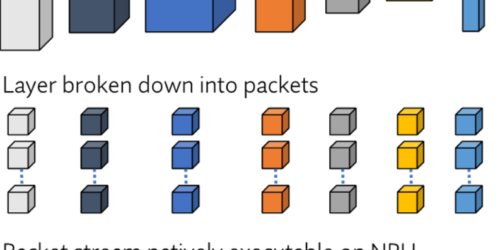
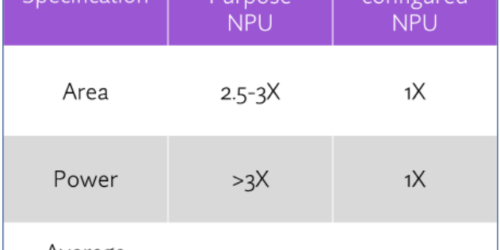
“Evolving Inference Processor Software Stacks to Support LLMs,” a Presentation from Expedera
Ramteja Tadishetti, Principal Software Engineer at Expedera, presents the “Evolving Inference Processor Software Stacks to Support LLMs” tutorial at the May 2025 Embedded Vision Summit. As large language models (LLMs) and vision-language models (VLMs) have quickly become important for edge applications from smartphones to automobiles, chipmakers and IP providers have struggled with how to adapt […]